
本文作者尘漠加入大淘宝到现在也有5年了,一路走来很开心,他认为在这里可以让他静心做技术研究。以下是尘漠的自述——
在淘宝前三年,我主要偏向研究 2d计算机视觉算法,相比于研究GAN、Transformer等热门课题,我更偏向解决一些算法在工业界落地遇到的常见问题,如深度学习模型训练中,常遇到训练数据不足、数据有噪声等问题,所以我更感兴趣噪声标签识别、主动学习等类型算法,也发表了简单实用的O2U-Net[5] (ICCV 2019) 噪声识别算法;另外算法推理性能提升,也是工业应用常见问题,比如在手机端部署CNN模型,需要提升模型推理效率,可能需要模型压缩、剪枝技术,也是我感兴趣的方向之一。
这两年随着元宇宙的爆发,内部团队项目的调整,我也转而开始加入到 元宇宙数字世界构建探索中,开始探索低成本高质量3D建模应用。2022年双十一,淘宝Meta 团队推出的 低成本高质量3D建模工具-Object Drawer,首次将学术界神经渲染3D建模算法(NeRF[1])在工业界规模化落地,实现了十几种品类的低成本建模(成本下降了70%)。我的工作职责主要是Object Drawer性能优化,下面聊一聊性能优化经历。
背景
电商商品3D化,可以使得用户在APP中,实时浏览3D商品模型,更直观地了解商品的外观颜色、形状结构、物理材质等信息,为用户带来更好的消费体验,为虚实结合带来更多可能,后续也可以用于AR\VR等内容生产。然而商品3D化存在:人工设计 3D建模成本太高,传统3D重建算法稳定性又很差。
2020年,谷歌提出神经辐射场3D建模方法NeRF[1],可以渲染出较高质量的图片,不需要人工修模,3D建模成本较低,为大规模3D模型生产带来了新思路。
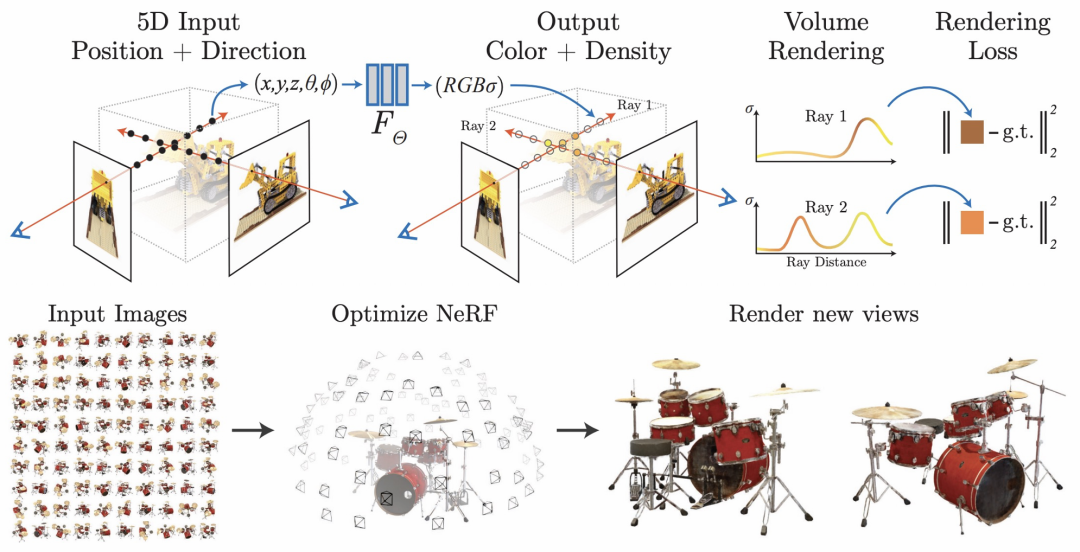
起初淘宝Meta 团队主要致力于 提升 NeRF重建效果(布料细节清晰度、商品文字清晰度等提升),使其渲染清晰度达到工业落地标准;然而由于NeRF存在推理速度慢等较大缺陷(服务器V100 GPU显卡,渲染一张高清图 需要1min),所以NeRF在淘宝落地主要在静态出图、AI内容创作做应用尝试,无法扩展到3D交互相关应用。
2020年底,由于项目调整,主管列出团队内一些急需解决的难题供选择。其中一个便是NeRF 算法性能优化,目标是 解决NeRF 3D模型到手机实时渲染的瓶颈问题,使其未来可以扩展到3D AR/VR等更多应用。问题难点:NeRF起初渲染速度非常慢,服务器 V100 GPU显卡上,渲染一张1080p图超过一分钟;如果要做到手机实时渲染,渲染速度预估需提升10000倍以上。
出于对模型推理效率优化方向感兴趣,外加喜欢挑战有难度的任务,我最终选择了解决NeRF推理性能优化。由于NeRF手机实时渲染,在当时并没有论文可以参考,算法推理效率需提升一万倍,所以只能尽力尝试推理加速各种方案。主管没给太大的压力与干涉,实验方案选择上没有任何约束,一句话:只要你认为有效的方案,都可以尝试。这使得我在算法优化工作中,更敢于去尝试有挑战的任务,更敢于去突破业界前沿。
一个人研究一个方向,没有内卷,静心实验研究,大胆尝试自认为有效的方案,这便是我得追求。
由浅入深尝试
由于我以前经历主要涉及 2D 计算机视觉相关算法,对于3D几何相关算法不太熟悉。所以对于算法推理速度优化,起初会偏向选择自己比较熟悉的方案进行尝试,比如神经网络推理加速通用的方案,网络剪枝、8bit量化、蒸馏等方法。经过了半年了实验,最终把神经网络常见的算法加速推理方法都尝试了一遍,最终效率仅提升200 倍左右的效率,离提升10000倍的目标仍遥不可及。后来又折腾了两个月,目标没什么大进展,慢慢意识到如果不对NeRF算法做较大改动,提出具有创新性的方法,效率基本不大可能有四个数量级的提升,因此我开始静下心来,学习3D模型表示、图形渲染等基础3D技术。
随着对3D模型表示、渲染有了进一步深入了解,业界前沿也有了一些推理加速的方法可以参考(Fast-NeRF、PlenOctree[3])。在综合考虑效率、内存占用、存储空间等问题上,我结合了PlenOctree[3] +SNeRG[4] 优点,提出了 采用 Octree+Tiny-MLP数据结构,并对MLP模型做了效率优化,在普通Android上1080p渲染效率做到了6FPS左右。推理效率提升了三个数量级,问题得到大幅度缓解,但还需要继续提升5倍以上的推理速度,才可以实现NeRF手机实时交互。
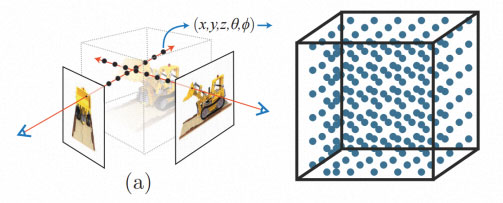
基于体素表示的推理加速方法,也会引入新的挑战:空间换时间策略,会引入新的问题,模型存储空间、内存占用变大,比如1024*1024*1024分辨率体素,结合前沿方法,经过模型量化、剪枝后,存储空间依旧达到300M;内存占用更是直接打爆手机,基本在2G以上。另外相比于学术研究NeRF 360视角渲染开源数据集来说,720 电商商品展示 在模型大小、内存占用都会更大。
| PlenOctree[3] +SNeRG[4] | 目标 |
| 6FPS | 30FPS |
| >1500M | 50M |
| >300M | 5M |
走不寻常的路,多个问题一起思考解决
如前所述,经过了第一阶段的模型优化,虽然推理效率问题大幅缓解,然而也带来了新的挑战问题。存储空间、内存都很大,效率也需要进一步提升,三个问题都很艰巨。正常的思维是三个问题逐一解决,分开思考、逐个击破,然而在考虑到分开解决存在研发周期过长、同时各性能难以平衡问题,研发周期过长,每个问题解决可能需要花好几个月的时间探索。我最终选择探索三个问题一起解决方案,相比于逐个解决,虽然难度加大,但可以把三个问题综合考虑、更好的平衡效果,缩短研发周期。
基于体素表示的神经辐射场,要提升效率、内存、存储三者性能,真正的难点在于其基本只有一条路可以走:减少体素点数,其可供参考的资料较少,需要靠自己摸索实验。
从2D图片压缩启发,我发现人类视觉上看,一张渲染图片是否清晰,取决于一张图片的边缘区域是否清晰。于是第一阶段优化,我们提出了 HrSRG[2](ECCV 2022)的方法:3D体模型分层表示+感知损失+GAN,在提升纹理清晰度的同时,使得模型推理效率模型达到state-of-the-art。在高端手机上可实时渲染,720商品展示模型大小40M左右(相比于学术开源数据360展示更加复杂)
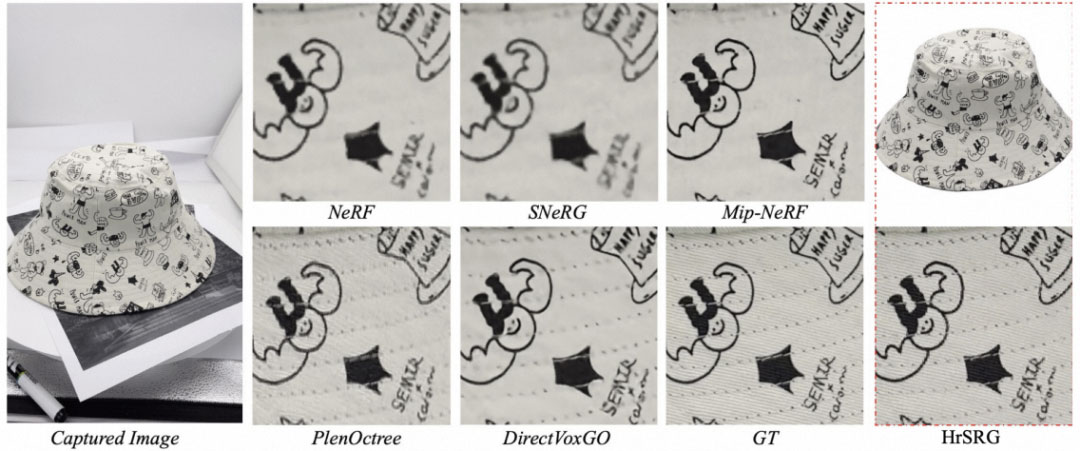
然而如果要真正达到业务落地要求,我需要进一步做到低端手机实时渲染,同时模型需要进一步压缩到5M的模型大小,进而我提出了:3D 体素模型高频检测算法,对低频区域用更少得体素点来表示,高频区域用更多的体素来表示。在结合HrSRG[2]+体模型高频检测算法后,可以把一个6000w个点 NeRF 3d体素模型,减少到200w个点,存储空间和模型大小会减少到原来的1/30,效率也会有大幅度提升。相比于前沿方法PlenOctree[3]、SNeRG[4]等方法,该方法可以实现大幅度压缩,且清晰度更为清晰,同时能够把效率、推理速度、内存三者性能都能得到大幅度提升,达到了手机上5M模型,同时低端手机能够实时渲染的要求:

在效果上,可以更好的保持纹理清晰度,对于商品特征细节信息上,相比于NeRF达到更高精度还原:

展望未来
即使目前目标任务基本完成,达到业务上线要求,我依旧喜欢更进一步精细打磨算法性能,比如NeRF[1] 体素表示现在模型大小压缩到5M左右,精益求精,未来还是希望进一步能够压缩到1M以内,NeRF[1]在低端机实时渲染效率依旧需要进一步提升到50FPS以上,每向前走一步都是成长。
参考文档
1、NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
2、《 Digging into Radiance Grid for Real-Time View Synthesis with Detail Preservation》
3、《PlenOctrees for Real-time Rendering of Neural Radiance Fields》
4、《Baking Neural Radiance Fields for Real-Time View Synthesis》
5、《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks 》
作者:黄锦池(尘漠)
来源:大淘宝技术
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
