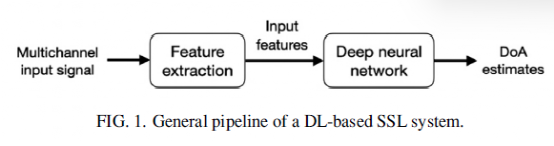
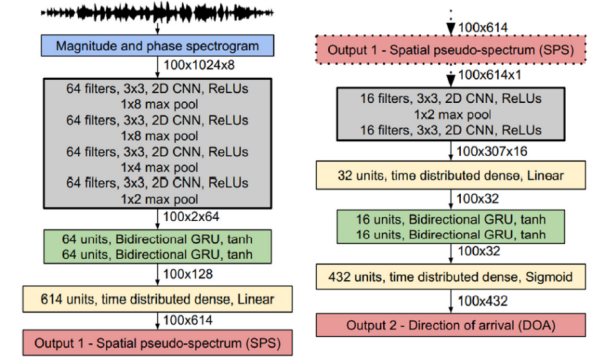
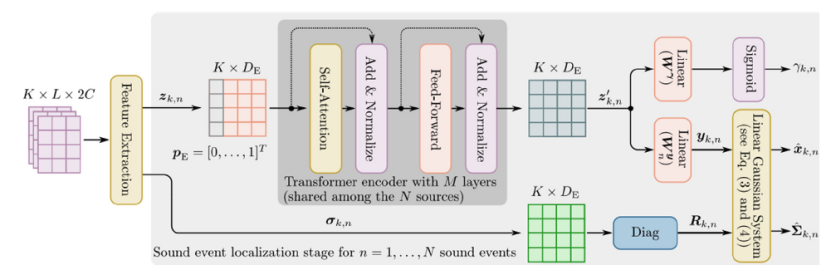
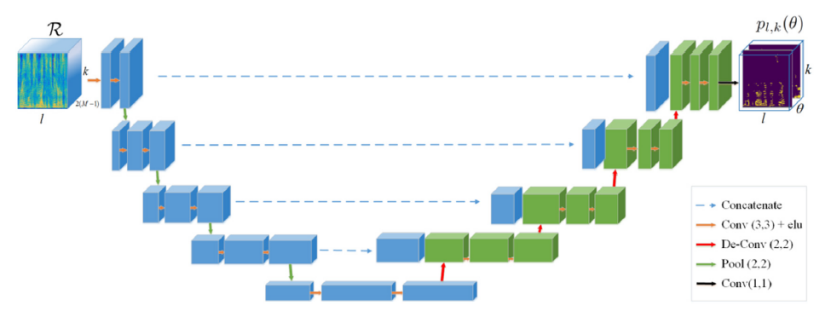
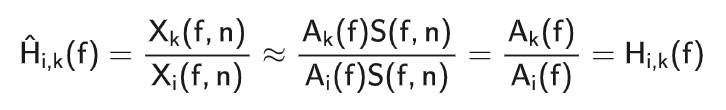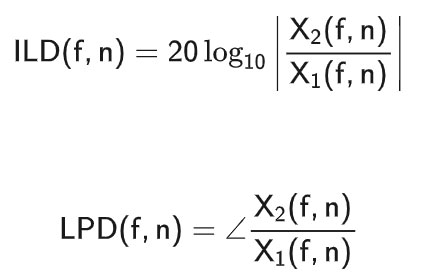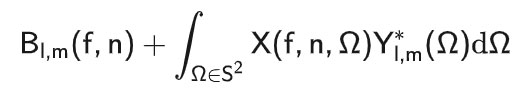基于RTF的表征已经被用于几个基于DNN的系统中,例如,Chazan等人(2019年)、Hammer等人(2021年)和Bianco等人(2021年)将从所有麦克风对获得的测量RTF的参数作为输入特征。
双耳特征对应于特定的双通道录音装置,旨在以最真实的方式重现人类的听觉感知。为了达到这个目的,采用带有入耳式传声器的假人头/身体来模拟声源到人耳的传播过程,特别是头部和外耳(耳廓)的影响。在消声环境中,(双通道)源-传声器的脉冲响应被称为双耳脉冲响应(BIR)。BIR的频域表示是HRTF。BIR和HRTF都是源DoA的函数。考虑到现实场景SSL应用中的房间声学,将BIRs扩展为双耳房间脉冲响应(BRIRs),它结合了头部/身体效应和房间效应(特别是混响)。
人耳对于单声源的定位主要依赖于两个重要参数,双耳时间差(ITD)及双耳强度差(ILD)。其中ILD和双耳相位差(IPD)与RTF密切相关,对应的公式如下:
当有多个声源存在时,TF域中语音/音频信号的稀疏性允许ILD/IPD/ITD值提供关于几个同时活动的声源的位置信息。Nguyen等人(2018)使用IPD作为参数,将其与多个频率bin和时间帧的ILD串联在一起,生成一个二维张量,然后将其输入到CNN中进一步分析。Pak和Shin(2019)提出了一个只依赖IPD的系统,实现了比传统DOA估计更好的性能。对于基于DNN的系统,Roden等人(2015)和Zermini等人(2016)使用了ILD和ITD,Shimada等人(2020-2021)采用了IPD及其他类型的特征。
根据加权函数的不同,广义互相关函数有多种不同的变形,其中广义互相关-相位变换方法(GCC-PHAT)方法应用最为广泛。GCC-PHAT方法本身具有一定的抗噪声和抗混响能力,但是在信噪比降低和混响增强时,该算法性能急剧下降。还有一些SSl依赖于交叉功率谱(CPS),Leung和Ren(2019)以及Xue等人(2020)将CPS输入CRNN架构中,以提高定位性能;Grondin等人(2019)还在其体系结构的卷积块中使用了每个麦克风对的交叉谱,并且在更深的一层中串联了GCC-PHAT特征。
传统的基于多通道信号CC矩阵特征分解的SSL方法,如MUSIC(Schmidt,1986)或ESPRIT(Roy和Kailath,1989),已经被广泛研究。基于DNN的SSL系统(如Takeda和Komatani在2016-2018的研究)受到这些方法的启发,重新使用这种特征作为其神经网络的输入。Nguyen等人(2020a)基于MUSIC算法计算了空间伪谱,然后将其用作CNN的输入特征。
另一种方法是直接向SSL系统提供“原始”的多通道信息,即在通道维度上没有任何预处理。基于DNN的SSL方法的一般精神是,网络应该能够自己 “看”,并自动提取和利用TF 谱图沿通道维度的差异,同时利用TF信号表示的稀疏性。
在几项研究中,不同STFT帧的个别频谱向量被独立地提供给神经模型,这意味着网络没有考虑它们的时间相关性。此时,网络输入是一个大小为M*K的矩阵,其中M是麦克风的数量,K是STFT频率bin的数量。Hirvonen(2015)将每个单独分析帧的八个通道的对数频谱连接在一起,并将其发送到CNN中。Chakrabarty和Habets(2019)和Mack等人(2020)使用多通道相位谱作为输入特征,忽略了幅度信息,这是因为它可以轻松地从白噪声信号生成训练数据集,作为这项工作的扩展,Bohlender等人(2021)也利用了相位谱。
当考虑到几个连续的帧时,多个时间步长和多个频段的STFT系数为每个通道形成一个二维矩阵,这些频谱图在第三维度上堆叠在一起,形成三维输入张量。如Patel等人(2020)只考虑了幅度谱。
STFT频谱图将频率间隔等分,而梅尔频谱图和bark频谱图则采用非线性子带划分表示。在几个SSL神经网络中,梅尔谱图比STFT谱图效果更好,例如,Cao等人在2019年多声部声音事件定位和检测领域的工作。在Pratik等人(2019年)的SSL系统中,也对Bark尺度进行了探索。
Ambisonics是一种多声道格式,由于其能够代表声场的空间属性,同时与传声器阵列配置无关,因此被越来越多地使用。SH分解是针对与传声器阵列同心的球体表面上测量的声压进行的。对于远场固定声源,在STFT域中的分解系数如下所示:
其中,X和Y分别代表Ω方向上的声压和SH函数。在实践中,由于组成阵列的传声器数量有限,这个积分由正交规则来近似,即假设声压在球面上是一个有限阶的函数(Rafaely,2019),其中L是最大阶数,并取决于阵列中传声器的数量。一阶Ambisonics(FOA)频谱图被Adavanne等人(2018、2019b)、Guirguis等人(2020)使用。Poschadel等人(2021)比较了基于从1到4阶的HOA频谱图的CRNN的性能,结果显示,阶数越高,网络的定位精度越好。
自2018年以来,Suvorov等几位作者提出了直接向神经网络模型提供多通道信号原始波形的想法。这种想法依赖于DNN的能力,可以在不需要手工特征或任何预处理的情况下得到最佳的SSL,这与DL朝着端到端方法的总体趋势是一致的。
基于波形特征的潜在劣势在于,利用这种数据的架构通常更加复杂,因为网络的一部分需要专门用于特征提取。此外,一些研究称,当输入信号中存在噪声时,从原始数据中学习“最佳”特征变得更加困难(Wichern等人,2019),甚至可能在某些情况下损害泛化能力(Sato等人,2021)。
一般将这些策略分为两类:分类和回归,当SSL网络被设计为分类任务时,声源位置搜索空间通常被划分为几个区域,对应不同的类别,神经网络为每个类别输出一个概率值。至于回归,其目的是直接估计声源的位置和方向。
空间被分成几个大小相似的子区域,神经网络的产出为每个子区域活动源存在的概率。这种分类问题通常通过在网络中使用前馈层作为最后一层来解决,该层的神经元数量与考虑的子区域数量相同。一般来说,有两个激活函数与最后一层神经元关联:softmax和sigmoid函数。Softmax确保所有神经元输出的总和为1,因此适用于单源定位场景。对于sigmoid函数,所有神经元输出都在0.5到1之间,彼此独立,适用于多源定位。最后一层输出通常被称为空间伪谱,其峰值为对应区域声源活动的高概率。
最终的DoA估计通常是使用拾取峰值算法得到的:如果源数量J已知,则选择J个最高峰值可以得到多源DoA估计;如果声源数量未知,则通常选择高于某个自定义的阈值的峰值,从而得到声源数量和位置的联合估计。一些预处理,如空间谱平滑或角度距离约束,可获得更好的DoA估计效果。因此,这种分类策略可以轻松地用于单源或多源定位。
在回归SSL网络中,源位置的估算是一个或多个输出神经元提供的连续值直接给出的。由于没有量化,这种方法估计的DoA更准确。但它的缺点也很明显,首先,声源数量需要已知或自行假设,因为没有办法根据定位回归来估计声源是否处于活跃状态;其次,基于回归的SSL通常面临着众所周知的信号源排列问题,该问题发生在多信号源定位时,也是基于DL的信号源分离方法的常见问题。在计算损失函数时,存在目标和实际输出之间的关联模糊性,也就是说,无法判断哪个估计应该与哪个目标相关联,一个可能的解决方案是强制SSL网络训练为包络不变量(Subramanian等人,2021b)。
在回归模式中也可以使用神经网络来估计中间量,然后由非神经网络算法来预测最终的DOA。Pertila €和Cakir(2017)提出使用CNN在回归模式下估计TF掩码,然后将该掩码应用于嘈杂的多声道频谱图,以获得干净的多声道频谱图的估计,接下来使用经典的SRP-PHAT方法检索最终的DoA。Wang等人(2019)使用双向LSTM网络进行了另一种TF掩码估计,以改进传统的DoA估计方法。Pak和Shin(2019)训练了一个MLP来消除IPD输入特征的伪影。Huang等人(2018-2019)使用神经网络对多通道波形进行处理,将其按照特定候选源位置的延迟时间进行移位,以估计原始信号,然后计算所有候选声源位置的估计干信号之间的CC系数之和,总和峰值对应的位置就是估计的结果。Jenrungrot等人(2020年)提出了一种联合定位和分离方案,神经网络被训练成在一定的角度窗口估计来自某一方向的信号,其参数被作为输入注入到每一层,使网络像雷达一样扫描所有方向,然后逐步减小角度窗口,直到达到所需的角度分辨率。
对于任何深度神经网络来说,数据集的数量和质量都起着重要作用。对于室内的家庭或办公室环境,噪声和混响在现实世界的信号中很常见。
为了模拟真实的数据,考虑到混响,需要模拟房间声学特性,这通常通过合成虚拟源-麦克风对的声音传播模型的RIR来完成。然后,将干信号与此RIR卷积,以获得模拟的传声器信号。SSL实现的基础是声源相对于传声器阵列的位置信息被隐含地编码在(多通道)RIR中,而SSL DNN学习从样本中提取和利用这些信息。因此,必须使用多种不同的干信号和大量不同应用场景下的RIR来合成数据。此外,可能还需要考虑其他因素的影响,例如房间尺寸和混响时间。这种方法的一个优点是存在许多干信号数据集,至于RIR模拟,存在几种方法和声学模拟软件,感兴趣的读者可以查阅相关参考资料( 例如Rindel, 2000; Siltanen 等人, 2010; Svensson 和Kristiansen, 2002)。
类似地,训练和测试双耳SSL系统需要直接将干信号与BIRs卷积。考虑真实场景中的房间声学特性,通常将BIR与RIR相结合。这不是通过简单地级联BIR和RIR滤波器来实现的,因为BIR取决于源的方向,这意味着需要将其与来自许多方向的RIR组件进行整合(Bernsch€utz,2016),称为双耳室内脉冲响应(BRIR)。
Cristoforetti等人(2014)提出的用于鲁棒家庭应用场景的远距离语音交互(DIRHA)模拟语料库已被用于模拟基于真实RIRs的麦克风语音信号。
TIMIT语料库是由麻省理工学院、德州仪器公司和SRI国际公司合作开发的。TIMIT语料库以语音数据为基础,用于训练和评估语音识别系统。TIMIT记录了使用8种不同方言的美式英语的630名不同说话人的语音,每段录音包含10个不同的句子。该数据集由70%的男声和30% 的女声组成。
SOFA数据集由音频工程协会(AES)监管,提供相应的平台来存储空间导向的声学数据。
近年来的挑战赛也构建了数据集用于对系统进行评估。例如在2019年( Adavanne等人)、2020年(Politis等人)和2021年(Politis等人)为DCASE挑战的SELD任务创建的数据集。
声源定位和跟踪(LOCATA)挑战一直是针对语音源定位的最全面的挑战之一。该记录使用了以下几种类型的传声器阵列:Brutti等人(2010)的平面阵列、Em32 Eigenmike球形阵列、助听器和安装在机器人头上的一组传声器。这个数据集已被用于许多研究工作中,以验证在真实场景中所使用的方法的有效性。
总体来说,深度学习技术在声源定位中具有非常重要的应用前景。它可以避免传统声源定位方法中需要进行复杂的信号处理和时间同步的问题,同时也可以提高声源定位的准确性和稳定性。随着深度学习技术的不断发展,我们相信深度学习在声源定位中的应用前景会越来越广阔。
1、Grumiaux PA, Kitić S, Girin L, Guérin A. A survey of sound source localization with deep learning methods. The Journal of the Acoustical Society of America. 2022 Jul;152(1):107.
2、M. Ahmad, M. Muaz and M. Adeel, “A Survey of Deep Neural Network in Acoustic Direction Finding,” 2021 International Conference on Digital Futures and Transformative Technologies (ICoDT2), Islamabad, Pakistan, 2021, pp. 1-6.
作者:宋芳葶、黄君如
来源: 21dB声学人
原文:https://mp.weixin.qq.com/s/mPUopk84n4bHRuTIKCDqZQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。