
受人脸图像编辑方法的启发,相关研究将这些方法扩展到人脸视频编辑任务,所面临的主要挑战之一是编辑帧之间的时间一致性。为此,本文提出了一种基于扩散自编码器的新型人脸视频编辑框架,该框架可以成功地提取分解的特征:来自给定视频的身份(identity)和运动(motion)。这种建模允许通过简单地朝着希望的方向操纵时间不变的特征来编辑视频,同时保留时序上的一致性。另一个独特优势是,由于本文模型基于扩散模型(Diffusion model),它可以同时满足重建和编辑能力,与现有的基于 GAN 的方法不同,对人脸视频中的极端情况(例如遮挡)具有更好的鲁棒性。
作者:Gyeongman Kim, Hajin Shim, Hyunsu Kim, Yunjey Choi, Junho Kim, and Eunho Yang
来源:CVPR 2023
论文题目:Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
论文链接: https://openaccess.thecvf.com/content/CVPR2023/papers/Kim_Diffusion_Video_Autoencoders_Toward_Temporally_Consistent_Face_Video_Editing_via_CVPR_2023_paper.pdf
主页链接: https://diff-video-ae.github.io/
代码链接: https://github.com/man805/Diffusion-Video-Autoencoders
内容整理:曹靖宜
引言
对于给定的人脸图像,人脸编辑是指改变头发颜色、性别或眼镜等各种人脸属性,作为计算机视觉标准任务之一,由于其各种应用和娱乐而不断受到关注。特别是,随着最近生成对抗网络 (GAN) 模型的改进,只需通过操纵给定图像的潜在特征就可以完成这项任务。此外,许多基于扩散概率模型(DPM)的人脸图像编辑方法也被提出,这些方法显示出高质量和灵活的操作性能。目前已经提出了进一步的研究来扩展图像编辑方法到人脸视频编辑中,这些研究试图用其他剩余的特征和运动完整地操纵目标属性。现有方法基本上都是通过基于StyleGAN的图像编辑技术独立编辑视频的每一帧。
尽管StyleGAN在这项任务中具有一定优势,如高分辨率图像生成能力和高度解纠缠的语义表示空间,但基于GAN的编辑方法的一个缺点是真实图像的编码不能被预训练的生成器完美地恢复。特别是,如果给定图像中的人脸被某些对象异常装饰或遮挡。为了实现近似完美的重建,相关研究提出在一个或几个目标图像上进一步微调,这会带来昂贵的计算成本,并且在视频领域可能更糟,因为必须在多个帧上微调模型。
除了现有的基于 GAN 的方法的重构问题外,在视频编辑任务中考虑连续帧之间的时间一致性至关重要。为了解决这个问题,一些先前的工作依赖于原始帧的潜在轨迹的平滑度,或者通过对所有帧进行相同的编辑步骤来直接平滑潜在特征。但是,平滑度并不能确保时间一致性,相同的编辑步骤也可以为不同的帧做出不同的结果,因为它可以无意中与不相关的运动特征纠缠。例如,在下图的中间行中,眼镜会随着时间而变化,有时当男人闭上眼睛时会减少。

本文提出了一种新的人脸视频编辑框架,称为扩散视频自编码器,解决了先前工作的局限性。首先,引入了基于扩散的面部视频编辑任务模型,基于最近提出的扩散自编码器 (DiffAE),本文模型学习了一个语义上有意义的潜在空间,可以完美地恢复原始图像并直接编辑。不仅如此,本文首次作为视频编辑模型,对视频的分解特征进行编码:1)所有帧共享的身份特征,2)每一帧中的运动或面部表情的特征,以及 3)由于方差较大,无法具有高级表示的背景特征。对于一致的编辑,只需为所需属性(每个视频的单个编辑操作)操作单个不变特征,与之前需要编辑所有帧的潜在特征的工作相比,这在计算上也是有益的。
本文主要贡献如下:
- 设计了基于扩散自编码器(DiffAE)的扩散视频自编码器,将视频分解为时间一致特征和每一帧时间变化特征。
- 基于扩散视频自编码器的分解表示,可以通过仅编辑单个时间不变的身份特征并将其与剩余的原始特征一起解码来进行人脸视频编辑。
- 由于扩散模型的重建能力近乎完美,本文框架可同时用于编辑面部被遮挡的异常情况和正常情况。
- 除了现有的预定义属性编辑方法外,本文还提出了一种基于文本的身份编辑方法,该方法基于局部方向 CLIP 损失实现人脸视频编辑。
Diffusion Video Autoencoders
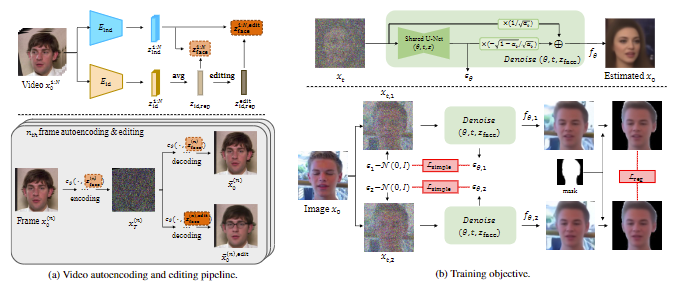
解纠缠的视频编码


视频编辑框架

包含以下两种编辑方式:

实验
重建
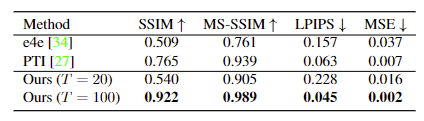
为了定量地比较重建能力,使用VoxCeleb1测试集中随机选择的20个视频进行测试,包括SSIM、多尺度 (Multi-scaled) SSIM、LPIPS和MSE常用指标。作为基线,将本文模型与基于GAN的反演方法e4e和PTI进行了比较。由于基于 StyleGAN 的方法处理大小为 1024 x 1024 的高分辨率图像,我们将重建结果调整为 256 x 256 进行比较。改变扩散步骤 T 的数量以观察计算成本和图像质量权衡, T = 100 扩散视频自编码器显示出最好的重建能力,并且在只有 T = 20 的情况下仍然优于 e4e。
时序一致性
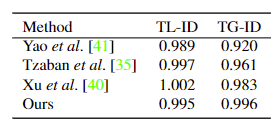
对比结果如下图所示,具体来说,Yao 等人的方法由于 GAN 反转的限制,未能保留原始身份;Tzaban 等人的结果中,根据唇部运动,胡须的形状和数量不断变化。尽管Xu等人的方法表现出更好但不完全的一致性,但这些运动无意中随着副作用而改变。

此外,下表定量评估了的时间一致性。尽管视频的时间一致性没有完美的指标,但 TL-ID 和 TG-ID 分别表示相邻帧和所有帧之间身份的局部和全局一致性。这些指标可以解释为与原始指标的值接近 1 时一致,本文方法大大提高了全局一致性。Xu 等人的 TL-ID大于 1,是因为编辑结果的动作缩小,以便相邻帧变得比原始帧更接近。
分解特征分析
为了证明扩散视频自编码器是否充分分解特征,作者通过改变分解特征的每个元素来检查合成图像。为此,对两个不同视频的帧进行编码,然后生成具有随机噪声的样本,或者在下图中相互交换各自的元素。当使用高斯噪声而不是原始噪声xt解码语义时zface,它具有与原始视频不同的模糊背景,而身份和头部姿势被大大保留。这个结果意味着 xt 仅包含背景信息的那样。此外,具有切换身份、运动和背景特征的生成图像证实,即使特征的新组合,特征也被正确地分解,扩散视频自编码器也可以生成逼真的图像。

结论
为了解决编辑人类面部视频的时间一致性问题,本文提出了一种新颖的框架,该框架具有新设计的视频扩散自编码器,它以解开的方式对身份、运动和背景信息进行编码,并在编辑单个身份特征后进行解码。通过解耦视频特征表示,本文框架最有价值的优势是可以只搜索一个帧的所需编辑方向,然后通过移动具有代表性的视频身份特征来编辑具有时间一致性的剩余帧。此外,对于不规则或有遮挡的视频可以基于扩散模型的优势实现更好的效果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
