
数据包丢失降低了视频会议的用户体验,在重传时间过长的通信场景中,恢复丢失数据包的标准方法是前向纠错(FEC)。用于实时应用的传统 FEC 方法在突发丢包的情况下效率很低。然而,突发丢包在实际中经常出现,可以通过一类新理论FEC方案称为 “流码”(streaming codes,是 convolutional codes 的一类)来更好地恢复丢包,该方案能够显著减少冗余来实现对突发丢包的恢复。Tambur 是一种新的基于流码并应用于视频会议场景的 FEC 架构,它克服了上述的限制。通过 Microsoft Teams 平台收集到的丢包数据,仿真验证了 Tambur 的效果,Tambur 将视频帧解码失败的频率降低了 26%,用于冗余的带宽降低了35%。并且在 QoE 指标上获得了提升,比如视频卡顿的次数和累计时长分别减少了 26% 和 29%。
来源: NSDI 2023
论文题目: Tambur: Efficient loss recovery for videoconferencing via streaming codes
论文链接: https://www.usenix.org/system/files/nsdi23-rudow.pdf
内容整理: 彭峰
介绍
视频会议电话的质量决定了远程会议的有效性,而远程会议现在已经无处不在了。Tambur 的工作重点是一对一的通话,视频质量取决于几个关键性能指标,如视频卡顿、带宽、丢包和延迟。
恢复丢失的数据包对于提供高质量的视频会议至关重要,即使是丢失一个数据包,也可能阻止视频帧的呈现。由于压缩视频的帧间依赖性,它还可能阻碍未来多个帧的渲染(即导致视频卡顿)。因此,视频会议应用通常在应用层面上处理数据包损失。两个广泛可行的解决方案是重传和前向纠错(FEC),这两种方法都是传输多余的数据。因此,在分配给冗余数据的带宽和传输原始数据之间存在着权衡。此外,视频会议应用必须在严格的延迟内恢复丢失的数据包——最好小于 150 毫秒,以满足实时播放的要求。
重传能够实现最小的冗余数据,因为它只发送丢失的数据包。因此,只要通信的往返时延允许,重传是最理想的方案。然而,由于视频会议应用有严格的实时延迟要求,重传只适用于往返时间短的情况,对于所有其他情况,视频会议应用依靠 FEC 在可接受的延时内恢复丢失的数据包。
Block codes(分组码)是目前生产系统中最常见的 FEC 形式。在分组码下,k个 “数据包”被用来创建 r 个冗余数据包,当其中一些数据包丢失时,k个数据包仍然可以被恢复,有r个额外的数据包,所以额外的带宽开销是(r/k)×100%。分组码的例子包括 Reed-Solomon (RS) 和 fountain 等,在随机丢包的情况下,数据包的丢失情况是独立的,所以分组码是一个很好的选择,因此分组码被广泛使用,例如 Microsoft Teams 就使用了 RS 码。
视频会议应用通过多个数据包发送编码视频帧的数据,我们把在一个或多个连续帧中连续丢失几个数据包称为“突发”丢包,突发丢包可能由于各种原因而发生,包括持续的 Wi-Fi 干扰和网络拥堵(例如当应用程序溢出路由器缓冲区并导致相关丢包)。论文对 Teams 的数千个视频呼叫的数据包跟踪分析表明,视频会议应用程序实际情况中突发丢包非常普遍。
如果要在实时延迟要求下从突发丢包中恢复时,分组码的带宽消耗效率非常低,相比之下,一个相对较新的理论上的FEC框架,即流码(streaming codes),可以有效地恢复突发丢包。流码期望能够在视频播放的期限之前恢复视频帧的数据包,而分组码则希望在最早期限一次性恢复出所有丢失的数据包,从而浪费了一部分冗余数据包,以前的研究探讨了流码的实际应用,但仅限于 VOIP。
鉴于带宽的宝贵和丢包恢复的双重重要性,流码在视频会议场景中具有巨大的吸引力,然而其应用有两个调整。首先,现有的流码和视频会议应用之间存在着差距。大多数实用的流码的变体仅限于输入数据的大小在一段时间内是一个固定的常数的情况,但在视频会议中,编码的视频帧的大小是变化的,并且现有的流码用理论信道模型的一个参数来设定冗余量,而这在实践中是未知的。其次,流码对于改善真实世界视频会议应用的 QoE 的有效性还没有在真实世界的数据上进行测试。
论文提出了 Tambur(意为 Tame burst),主要的贡献在于:
- 分析从大型商业视频会议应用中获取的数千条视频通话丢包记录,并确定其是否适合使用流码。这是第一项利用大规模、真实世界的数据来评估流媒体代码潜力的工作。
- 提出Tambur,它通过(a)设计一个非常适合视频会议的新码和(b)将其与一个轻量级的ML模型相结合,对分配给流媒体代码的带宽进行预测性决策。
- 实现一个新的基准平台,使视频会议 FEC 的研究可以用一个通用的评估平台,此外,用C++实现Tambur、Block-Within和Block-Multi,并使用接口将它们纳入基准平台。
- 通过仿真对Tambur进行评估,表明它同时降低了不可恢复帧的频率和带宽开销,分别为26.5%和35.1%。
- 在仿真网络上评估Tambur,显示出与端到端QoE相关的关键指标的显著改善(例如,将卡顿频率降低26%,将卡顿的累积时间降低29%,如图一所示)。
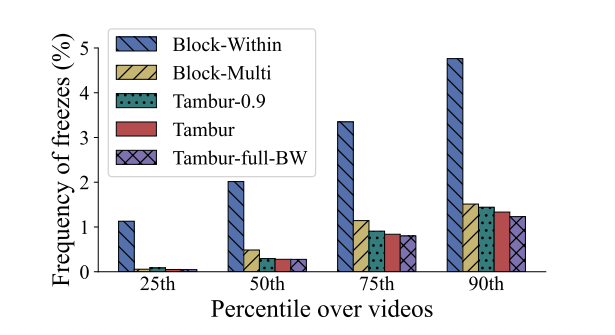
背景和动机
传统 FEC 方案及其在视频会议中的挑战
传统的 FEC 方案基于分组码,通常使用几个数据包生产冗余数据包。在视频会议场景中,一个编码后的视频帧被打包为多个数据包发送,如图 2 所示,FEC 的方案会针对一个帧或者是多个帧的数据包生产冗余数据包。在突发丢包的情况下,针对单帧的机制可能会出现丢包过多无法丢包恢复,或者没有发生丢包,冗余包没有被利用,造成带宽浪费。尽管针对多帧数据包进行冗余的机制可以避免上述的问题,但是由于实时场景的时延要求,帧的数目也有要去从而保证时延,并且当冗余包一次性在末尾发送时,由于数量大,可能会造成网络拥塞甚至超过路由缓存大小限制。
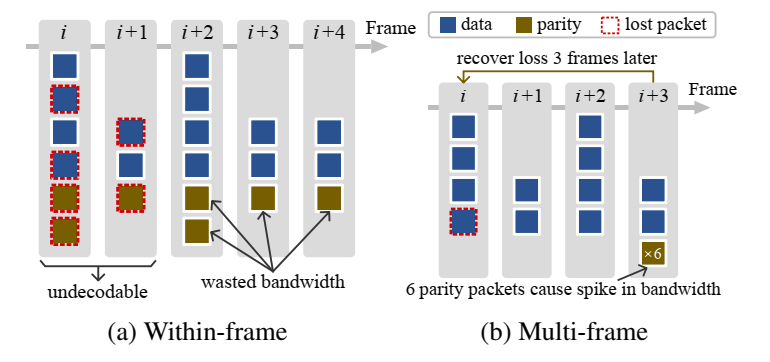
流码(Streaming codes)
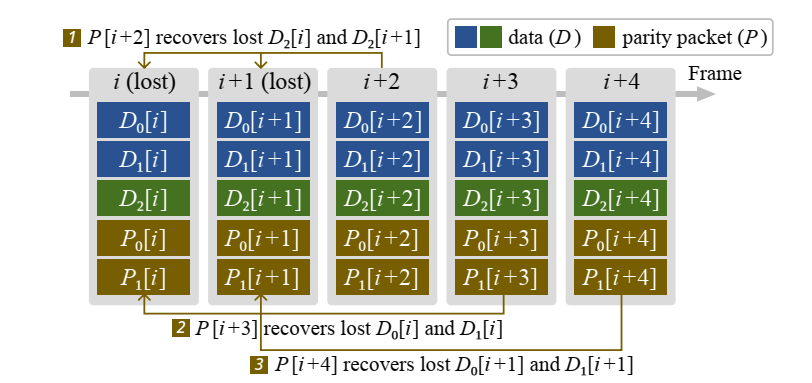
“流码”是一类专门解决突发丢包问题的编码方式,流码通过以下方式避免了帧内和多帧的限制:(a)在每一帧中发送奇偶校验包(冗余包);(b)使用在突发的最后一帧的播放期限前收到的所有奇偶校验包来恢复丢包。
流码的框架有几个方面:1) 生产冗余包的发送端;2)丢包信道,该信道存在长度(并不是至丢包个数)为 b 的丢包,但在丢包之后会有一个不丢包的保护期(guard spaces of packet receptions);3)接收端对丢包恢复的时间要求,例如一个本该在时间单位 i + τ 到达的数据包丢失了,接收端要求数据包必须在 内被恢复。文章中给出了一个帮助理解的例子如下。

将 streaming codes 应用视频会议的挑战
以往的工作对真实场景的假设过于强,例如编码的视频帧数据包一致,如何将 streaming codes 应用到真实场景是一个挑战。其次大规模的验证也是另外一个挑战。
真实世界的丢包情况分析
论文使用了 Microsoft Teams 平台的数据进行分析,其收集了大量的视频通话连接的丢包情况,具体收集了 9700 次有网络丢包会话的最后一分钟的丢包情况,有丢包的情况(即这9700次)占统计总数的 16%。只针对有丢包的 trace 进行分析的主要情况如下:
现有 FEC 方案的效果:
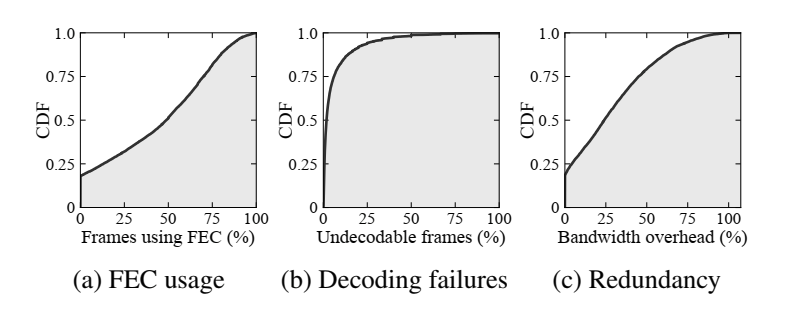
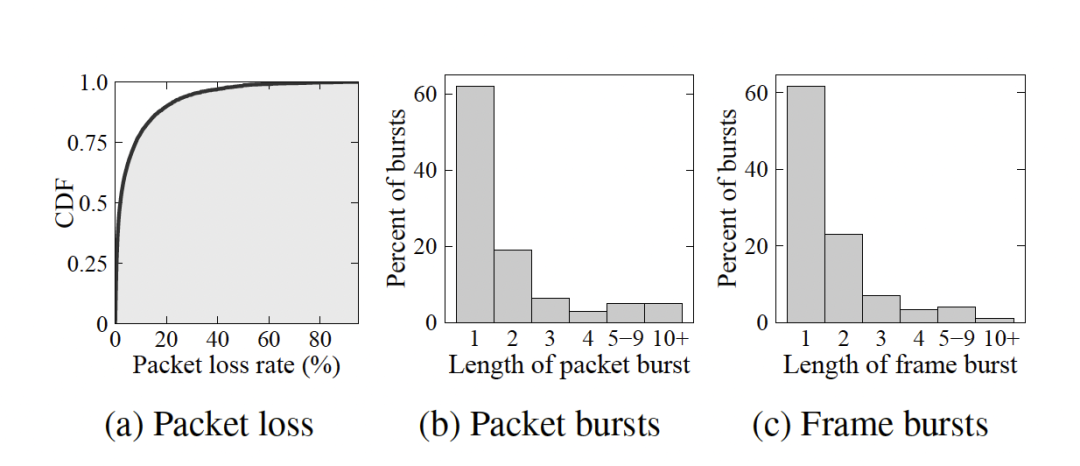
Microsoft Teams 使用 RS 码对每一帧做冗余,效果如图 4 所示。
丢包情况分析
从 Microsoft Teams 平台收集数据的丢包分析情况如图 5 所示,说明丢包情况普遍,突发形式的丢包占比高。
streaming codes 的优势
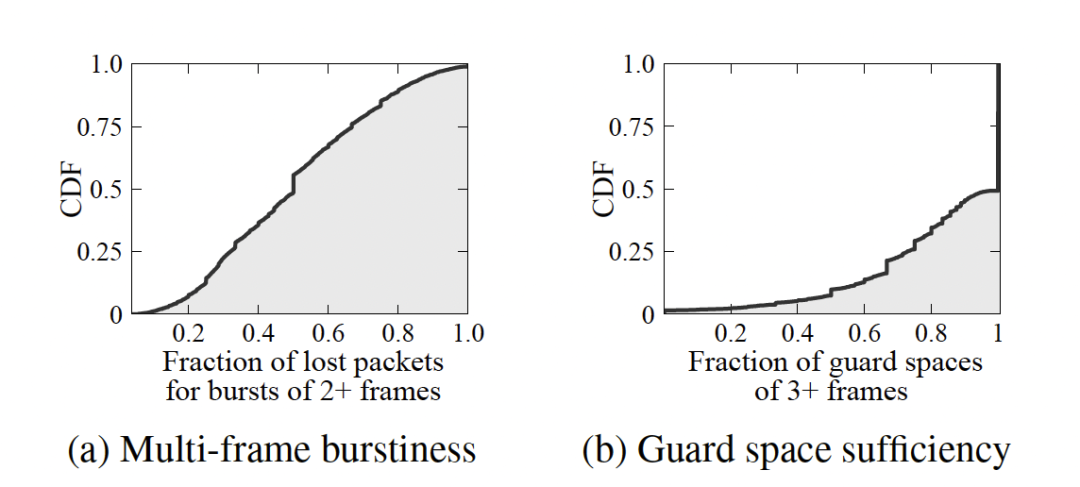
streaming codes 在突发丢包且设计到多帧到数据包,并且丢包之后有一段时间的无丢包保护期情况下效果最好,为了 streaming codes 能够实际应用,文章定义了如下两个量。
- 多帧突发(Multi-frame burstiness):
假设一个突发事件发生在两个或更多的帧,i到j,在这些帧上发送的数据包。如果s数据包中的l个丢失,多帧突发被定义为l/s。
- Guard space sufficiency:
-guard spacesufficiency是指在一个或多个丢包的帧之后,至少有个连续帧经历无损传输的情况。
两个量的统计结果如图 6 所示,表明 streaming codes 的适用性。
Tambur 设计
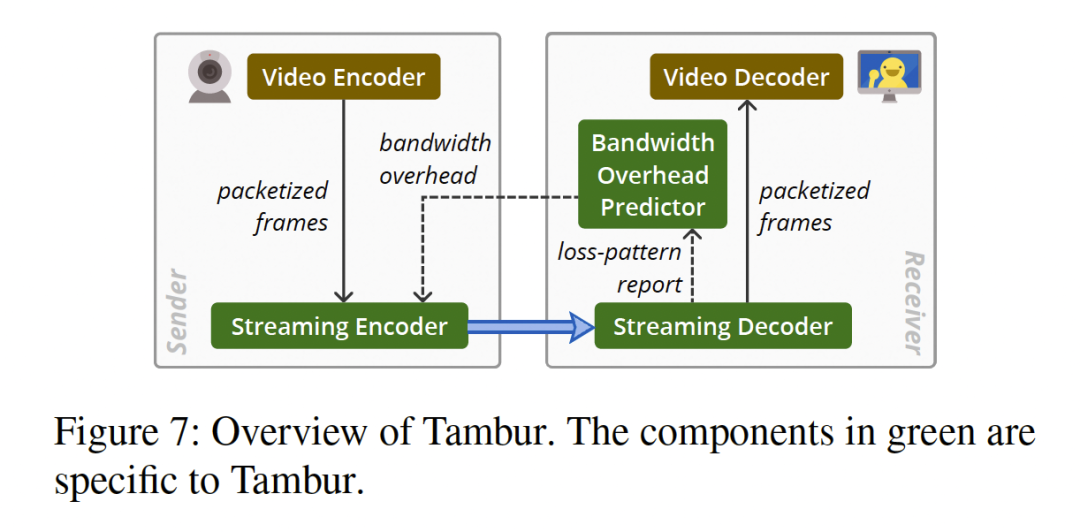
Tambur 的框架图如图 7 所示,其中包含一个 Streaming Encoder 用于生成冗余包,Streaming Decoder 利用收到的数据包和冗余包进行丢包恢复,Bandwidth Overhead Predictor 预测冗余包数据该分配带宽的比例。
Streaming Encoder 和 Streaming Decoder
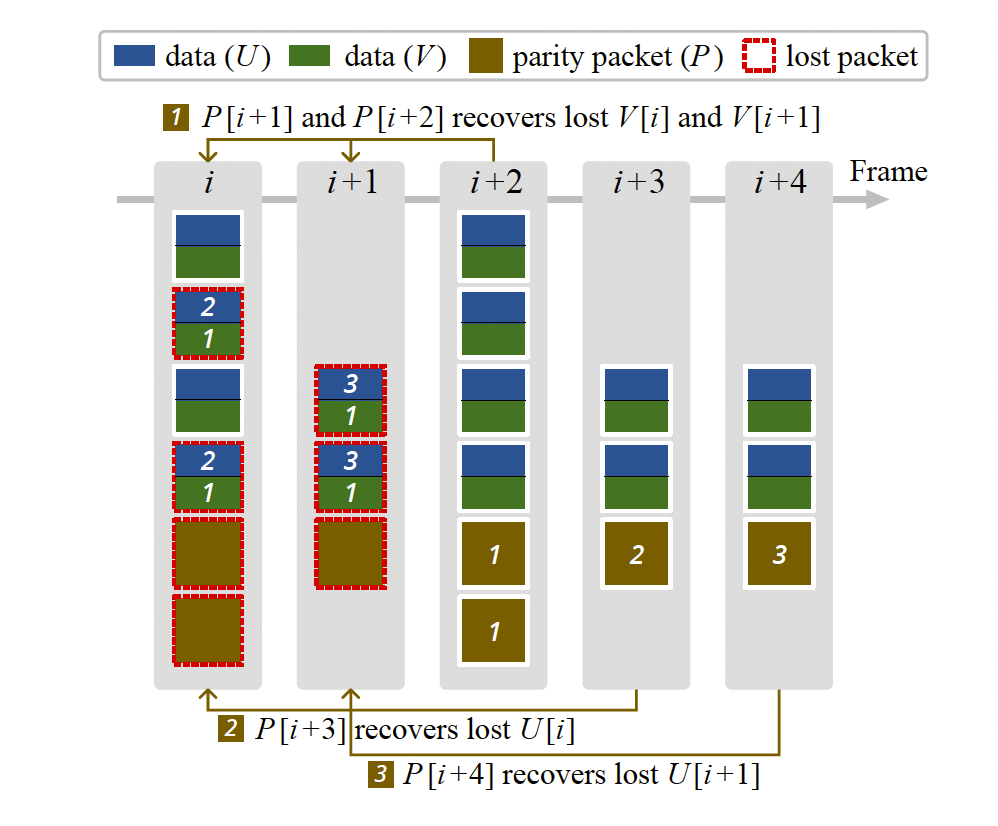
主要的思想是将冗余包分散在后续帧后发送,因为只要在给定期限(文中给定 150ms)恢复出丢失包,冗余包可以同时保护多帧的数据包,从而可以相比传统方式能够在更小的带宽消耗下,实现较好的丢包回恢复效果。
Bandwidth Overhead Predictor
该模块作用为更具网络丢包情况预测对视频帧冗余包的带宽分配,其通过收集到的网络丢包信息进行离线训练,将和丢包有关的 13 个量作为输入,通过有一个全连接层的神经网络,输出带宽分配比例的离散值,文中称 ground truth 是按照丢包情况,在 streaming codes 场景下计算出的最优值,但并没有给出最优的说明。在使用交叉熵作为损失函数的情况下,在损失函数中对没有恢复出完整帧的预测赋予 0.999 的权重,恢复出了完整帧但是过多分配了带宽的情况赋予 0.001 的权重。
系统实现和验证
论文使用的测试系统 和 Tambur 的实现 均进行了开源。主要设置了以下六组对比:
- Block-Within:使用 RS 码对单帧进行冗余保护,是 Teams 使用的机制
- Block-Multi:使用 RS 码对 4 帧的数据进行保护
- Tambur-full-BW:Tamebur 的变形,训练时以 Block-Within 的冗余带宽分配比例为训练目标
- Tambur-0.9:对 Tamur 的损失函数权重修改,即将没有恢复完整帧的情况的权重从 0.999 调整到 0.9,模型更倾向节约带宽
- Tambur-low-BW:以 Block-Within 的冗余带宽分配比例的 50% 作为目标
- Oracle:在能恢复出所有丢包的情况下,在 Tambur-full-BW、Tambur-low-BW 和 Block-Within 三者中选择带宽消耗最少的
离线验证结果
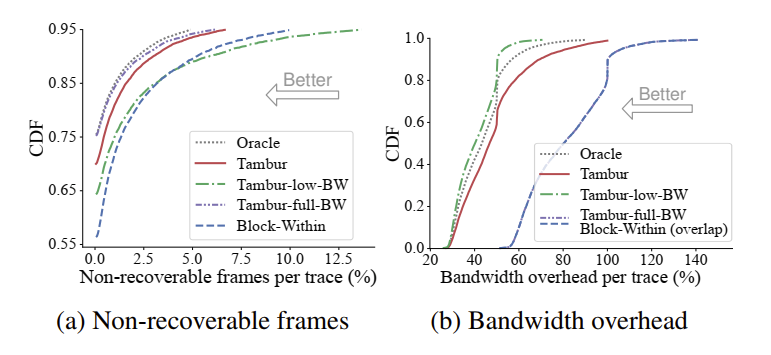
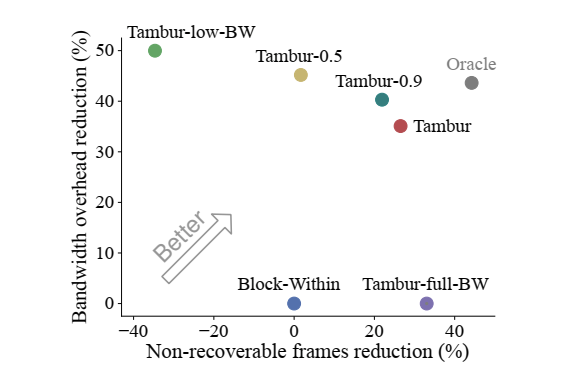
论文主要使用了 Teams 平台收集到的丢包 trace 进行离线测试,其中 Oracle 每次都选择最优,所以也只能离线验证。实验结果如图 9 和图 10 所示,可以看到 Tambur 实现了较好的丢包恢复能力并且冗余数据占用了和最优选择 Oracle 接近的带宽。
在线验证结果
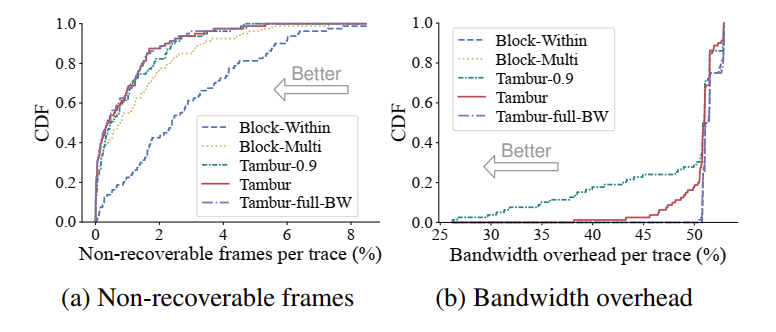
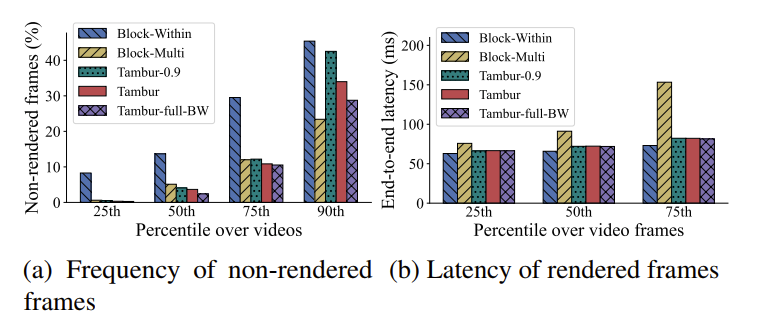
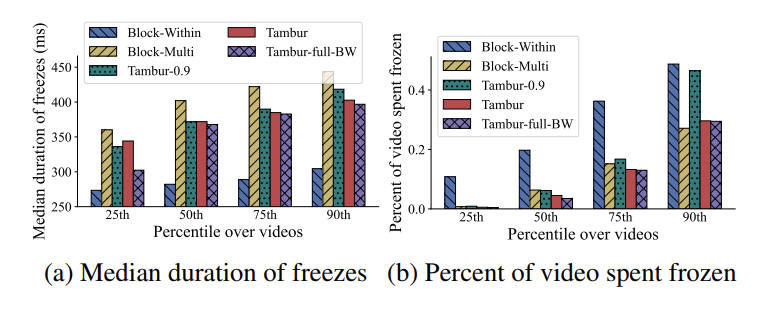
使用收集到的丢包 trace 和 GE 信道模型生成的丢包 trace,用 mahimahi 工具在论文实现的平台上实验。实验结果如下图所示,其中图 11 说明 Tambur 实现了较好的丢包恢复能力,并且节约了 FEC 使用的带宽。图 12 说明 Tambur 对帧丢包的恢复能力强,并且 FEC 恢复时延没有影响渲染时延。图13 说明尽管Tambur 单次卡顿的时间较长,但是累计时间很小。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
