
背 景 篇
AI绘画是一种使用人工智能技术来生成图像或绘画作品的技术。这种技术通过学习大量的图像数据来模拟人类的绘画风格和技巧,从而可以自动地生成具有艺术感的图像,是AIGC领域的重要应用场景。
此前艺术家曾认为AI绘画不可能,认为艺术是AI永远跨不过去的门槛,但是在2022年8月发生了变化。作品《太空歌剧院》美国科罗拉多州举办的新兴数字艺术家竞赛中获得“数字艺术/数字修饰照片”类别一等奖,而这幅画并非出自大师之手,而是由Jason Allen使用AI绘图工具Midjourney ,通过输入题材、光线、场景、角度、氛围等画面效果的关键词,是用“文字游戏”的方式完成的。自此之后AI画作开始大量涌现,越来越自然、真实。

发展简史
AI 绘图的历史可以追溯到 20 世纪 70 年代。1972 年,艺术家 Harold Cohen 编写了一套名为AARON的计算机程序,它可以使用电脑符号生成图像,不过与现代AI绘图不同的是,AARON 用画笔和颜料来进行绘画。

到了21世纪初,随着深度学习和神经网络技术的不断发展,AI绘画开始能够生成高质量的彩色图像。其中最流行的技术之一是生成对抗网络(Generative Adversarial Network,GAN),它可以使用对抗训练技术来生成逼真的图像。
2016年,引入了风格迁移技术,可以通过卷积神经网络学习两个图像之间的相似之处,将一个图像的风格应用到另一个图像上。这项技术迅速成为当时的热门课题,并在计算机绘画领域产生了革命性影响。
随着各种技术的不断进步,如随机生成和全面智能绘画等,AI绘画的应用场景也逐渐扩大,包括艺术创作、设计、娱乐等领域。AI绘画在发展中,逐渐演化成当前人和机器通过提示词互动创作的一种艺术形态。
本文在技术部分着重介绍 Stable Diffusion 这款在业界非常流行的通过文本来生成图片的绘图模型。
技 术 篇
Stable Diffusion(为描述方便简称SD)是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512×512分辨率图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像;因为有开源的预训练模型,开发者可以在自己的机器上调试它。
一个简单的SD使用效果如下所示:
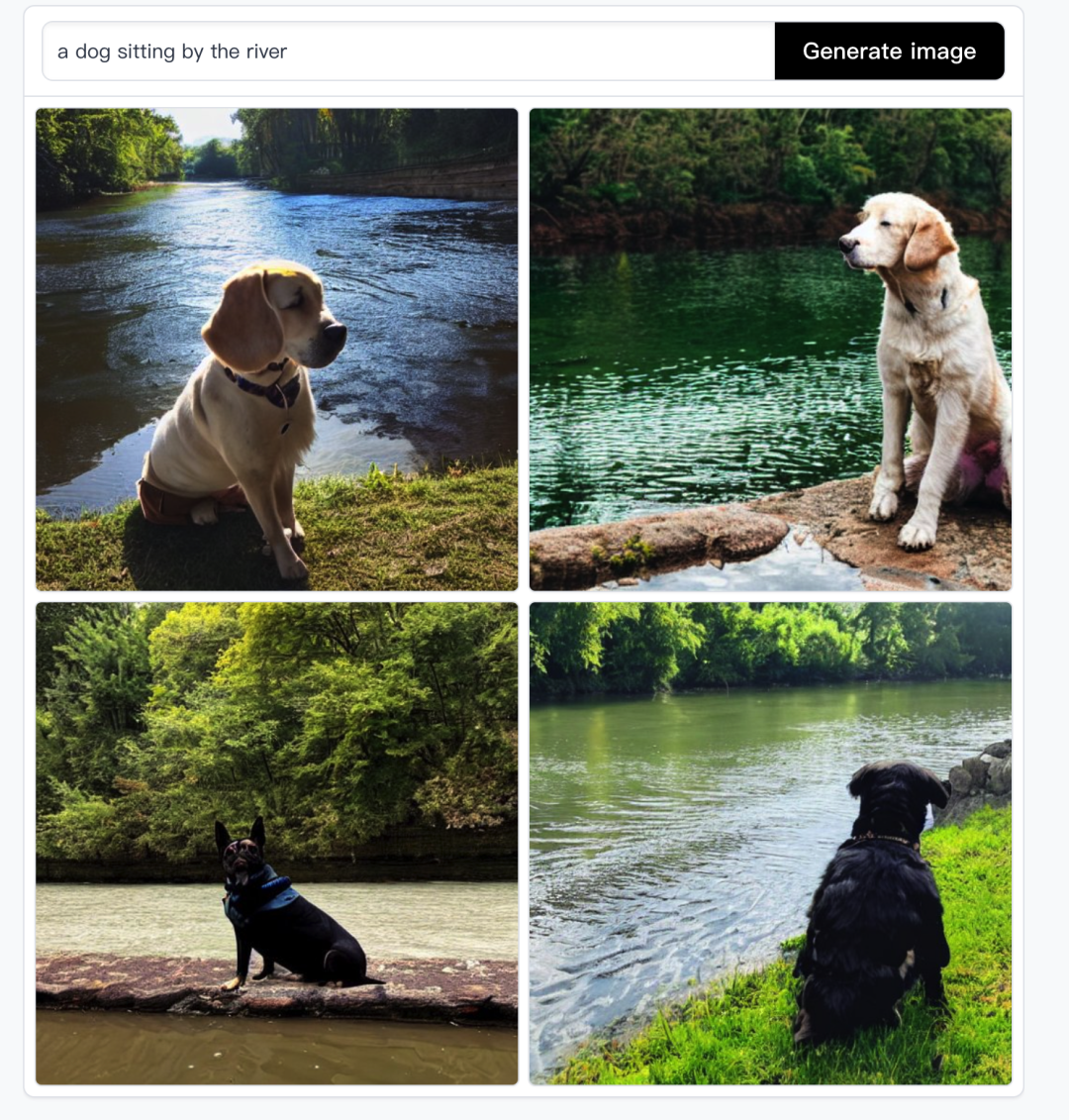
可以看到,对使用者来说,只需要输入对应的文本或者提示词,SD 就会自动绘制出对应的图像。流程如下图所示:

通过几句提示词就可以生成高质量的图片,相信大家一定会很好奇SD是怎么做到的。想要回答这个问题,需要先回到 SD 的定义:
“Stable Diffusion是一个文本到图像的潜在扩散模型”。
这里涉及到了几个问题:
● 什么是扩散模型?
● “潜在”是什么意思?
● 文本是如何控制图像生成的?
下面我们就一一揭开它的神秘面纱。
扩散模型
扩散模型(Diffusion Model) 是一种生成模型, 扩散模型通过在前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程,也就是说模型有一个扩散和逆扩散的过程。如下图所示:
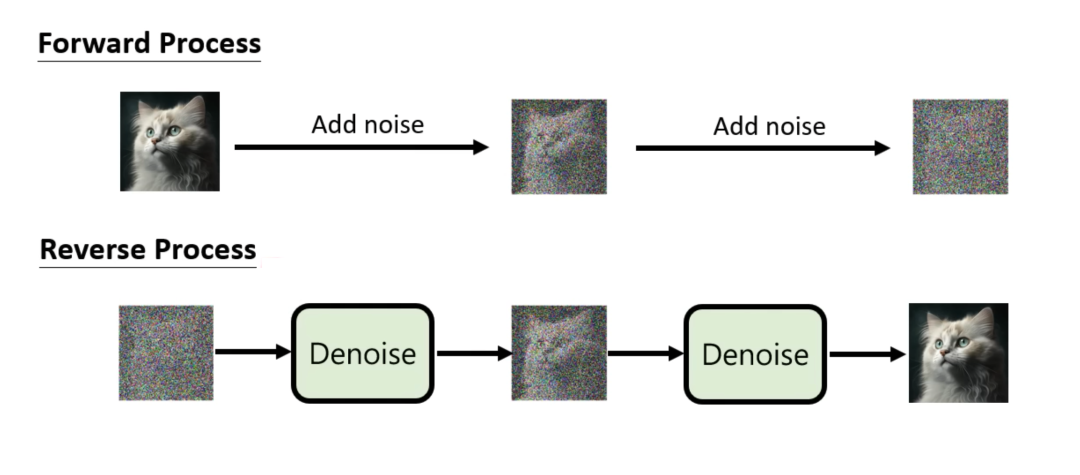
如果依然抽象,可以类比一滴墨汁在水中扩散的物理现象:当我们把墨汁滴入水中,墨汁会均匀散开,但是如何让均匀分散的墨汁变为最初的一滴墨汁呢?现实世界中,这个物理扩散过程一般不能逆转,但AI要做的就是让这个过程可逆,这个就是扩散模型。

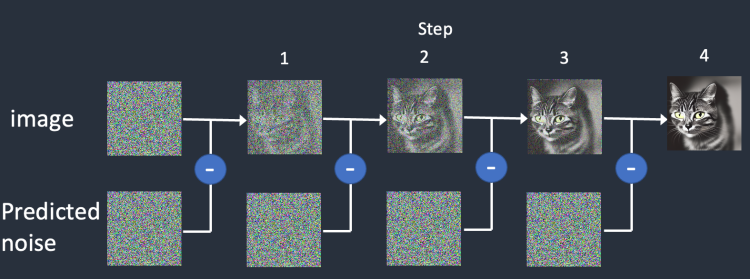
通过对海量图片进行扩散和逆扩散训练,可以得到一个噪声预测器(Noise Predictor),它是一种 U-Net卷积神经网络(一种用于图像分割的深度学习模型)。噪声预测器的输入一个完全随机的噪声图像,噪声预测器输出为一个预测的噪声图形。通过从原始噪声图像中减去这个预测的噪声图像并重复这个过程数次,我们将可以得到一只小猫的图像。
潜在空间
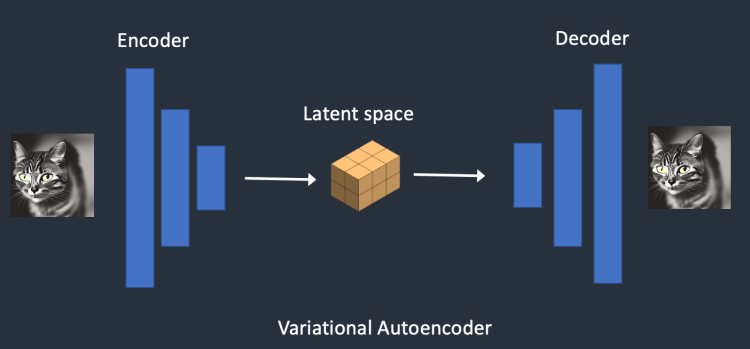
上文提到扩散模型会对图片不停增加噪声然后最后通过减噪来生成图片,这个操作都是在像素空间操作的,也就是说所有的训练都是在原始图片上进行处理,这个可能会带来一些性能问题,导致生成图片缓慢。例如一张 使用 RGB编码(基于红绿蓝像素)的512×512 分辨率的图片就是一组 512 * 512 * 3 的数据,如果直接对图片进行学习,相当于 AI 要处理 786432 维的数据,这对算力、计算机性能要求很高。CompVis 的研究人员提出,可以将高维的图片映射到低维的潜在空间(Latent Space)后进行扩散和逆扩散学习。比如音乐是一个高维的复杂格式,但是乐谱却是一个更低维度的表示,这个乐谱就是音乐的潜在空间。AI 就是通过学习找到了一个图片潜在空间,每张图片都可以对应到其中一个点,相近的两个点可能就是内容、风格相似的图片。
在 SD 中,会通过一个称为 VAE( Variational Autoencoder ,变分自编码器)的神经网络将图片编码压缩到潜在空间。VAE 包含两个部分,一个是编码器,一个是解码器。编码器用于将高维的图像压缩到低维的潜空间,解码器用于从潜在空间恢复图像。
SD的潜在空间是4x64x64,比图像像素空间小48倍(3 * 512 * 512 / (4 * 64 *64) = 48)。和普通扩散模型不同的是,SD 中的所有扩散和逆扩散实际上都是在潜在空间中完成的。因此,在训练过程中,它不是生成一个有噪声的图像,而是在潜空间中生成一个随机张量(潜噪声)。它不是用噪声破坏图像,而是用潜在噪声破坏潜在空间中的图像表示。这样做的原因是,由于潜在空间较小,所以速度会快很多。
文本控制图像生成
在扩散模型中,我们通过多次使用噪声预测器,最终生成了一张小猫的图片。但是存在一个很大的问题:生成的过程无法控制,无法预测最终会生成一只猫还是一只狗,所以,需要文本来来引导图片生成。在 SD 中, 会通过 openAI 开发的 CLIP (Contrastive Language-Image Pre-Training)模型来完成对文本的处理。
CLIP模型包含一个图像编码(Image Encoder)和一个文本编码(Text Encoder),可以分别对图片和文字编码,编码的结果为一个称为embedding的向量。如果图片编码后的embedding向量和文本编码后的embedding向量比较相似(余弦相似度接近于1),就可以认为图片和文本是相匹配的。简单来说,给 CLIP模型一张图片和一段文本描述,CLIP 就可以检测出图片和文本描述是否匹配。
通过对海量的图片和文本进行训练,CLIP模型将计算机视觉和人类语言这两个原本不相干的信息成功关联在了一起,让二者拥有了统一的数学表示。你可以将文本通过一个Text Encoder转换成图片信息,也可以将图片通过Image Encoder转换成文本信息,二者就能够相互作用了。这也是SD中可以通过文字生图片的秘密所在。
文本生成图片流程
通过上文的介绍和描述,我们大致知道了SD利用了扩散模型训练出了一个名为噪声预测器的 U-Net神经网络模型、利用 VAE将图片压缩到了潜在空间来提高性能、用CLIP模型将和图片和文本进行了关联,但是对完整的一个文本生成图片流程还不够清晰,下文将解释一个完整的文本生成图片的过程。具体的过程如下所示:
步骤1:SD在潜在空间中通过随机种子生成一个大小为4x64x64的随机张量,可以将其理解为潜在空间中的随机噪声图像。
步骤2:将步骤1生成的随机噪声图片作为潜在图像、通过CLIP处理后的提示文本(即embedding向量)一起传入到噪声预测器(Noise Predictor),噪声预测器会输出预测噪声。预测噪声同样位于潜在空间中,也为一个4x64x64的张量。
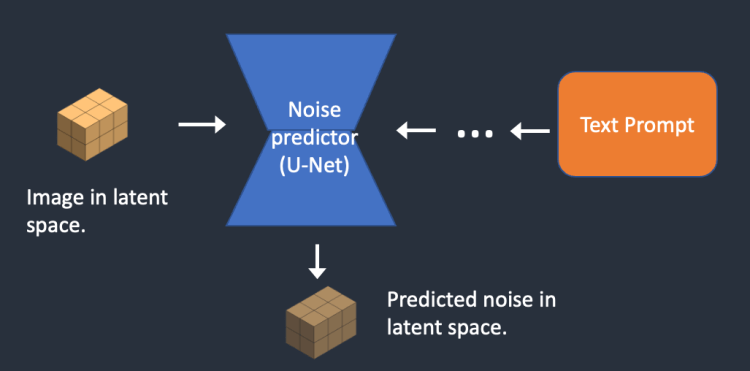
步骤3:从潜在图像中减去预测噪声信息,得到新的潜在图像。

步骤4:将步骤2和步骤3重复 N次,N代表采样次数,例如N=20次。
步骤5:将步骤4得到的潜在图像传入 VAE, 通过VAE 解码后,就可以得到512×512分辨率的图片。
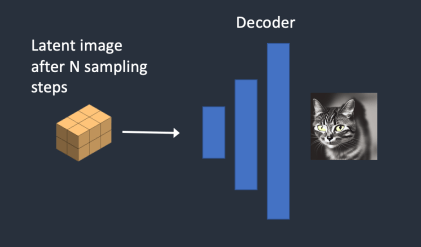
至此,就完成了整个由文字生成图片的过程。一个可视的效果如下所示:
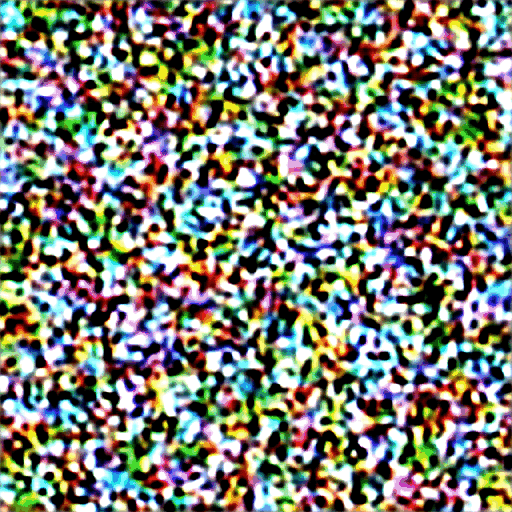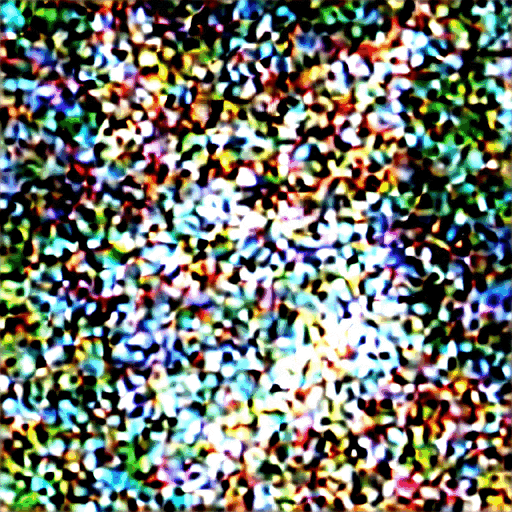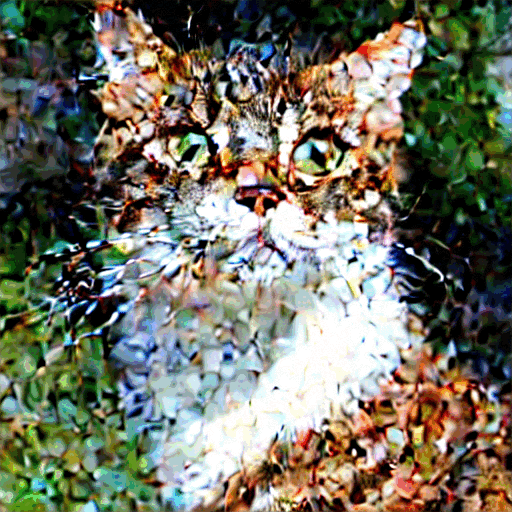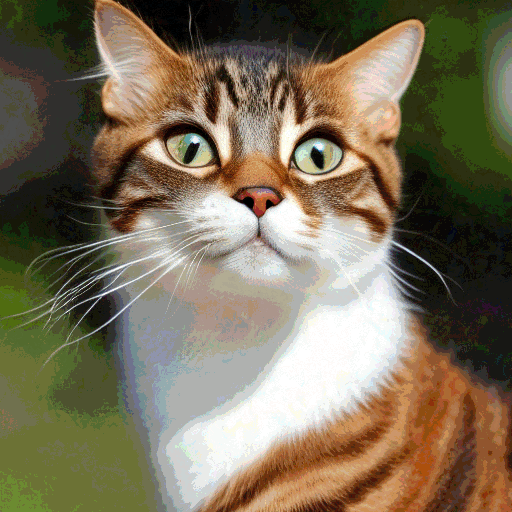
和传统模型相比SD的优势
SD是一种比较新的生成模型,和传统模型相比有如下优势。
训练稳定:传统的GAN和VAE在训练过程中往往会遇到模式崩塌等问题,导致生成结果质量不稳定。而SD采用了比较稳定的扩散过程设计,可以大幅减少训练过程中的崩塌问题。
易解释性:传统模型生成的图像有时候难以解释和理解,因为它们的生成方式比较抽象。而SD生成的图像是按照时间步骤逐渐生成的,每一步生成的结果均可依据前一步进行解释。
鲁棒性强:SD的扩散过程具有可重复性和鲁棒性,例如比较稳健的热身(Warm-up)策略和可重复的抽样过程并使得我们在抽样上有更细致的控制。
易用性高:传统模型相对较难训练,需要调整许多的超参数才能得到较好的结果,而SD可以通过非常少的超参数搭建起模型并训练,使用简单。
应 用 篇
随着人工智能技术的不断发展,越来越多的艺术家和企业开始使用AI绘画技术进行创作,带来了全新的艺术风格和商业应用模式。
艺术领域
在艺术领域,通过AI绘画以辅助艺术家完成创作过程,提高创作效率和创作品质,也可以生成新的艺术作品,创造出各种令人惊叹的艺术形式。AI绘画技术还能够模拟不同艺术家的风格,并通过深度学习对不同艺术风格进行学习和迁移,帮助创作者实现快速创作和创新。
创作辅助和创作支持
可以作为创作辅助,帮助艺术家实现创作目标。例如,可以使用AI工具帮助自己更快地进行草图绘制,快速检索想要的颜色或对结构进行更加细致的调整。这可以提高创作效率,并使得作品的质量更加高。
另外,艺术家可以通过将AI技术与传统绘画工具结合使用,来创建全新的艺术表现力。例如,美国艺术家Ian Cheng通过AI绘画技术创作了一个名为”Emissaries”的黑暗生命体系列艺术作品。这些作品利用了计算机生成的3D模型和算法,向观众展示一个神秘的、充满生命力的世界。Cheng关于认知进化历史的Emissary三部曲,每一章都模拟了不同的“实时数字仿真”场景。在这些数字景观中,由AI驱动的微型卡通人物漫无目的地游荡,仿佛它们摆脱了更大的叙事背景。它具有些许复古游戏的美感,被一种神秘感缠绕着,对于图形的迟钝感开始变得越来越有意义,成为在无边的模拟记忆和身份世界中迷失的象征神话。

创造出新的艺术形式
AI绘画技术还能够创建多种新型的艺术形式,例如“机器人绘画”,将一个机器人装配上AI造型追踪技术,使其可以在纸张上或者其他材料上自由绘画。AI绘画技术还可以生成各种不同形式的艺术品,比如自动生成的图像、雕塑等等。
通过深度学习生成各种不同的艺术风格
使用AI绘画技术生成各种不同的艺术风格。这些技术通常利用深度学习算法,模拟出不同的艺术家的创作风格,让AI程序可以自己创建出类似的艺术品。
例如,英国公司Jukedeck发明了一种名为”Flow Machines”的AI绘画技术,这种技术可以学习和模仿不同音乐家的风格来创作新歌曲。同样的,普林斯顿大学的研究人员使用AI技术来模拟出画家毕加索的作品,让人们可以生成出皮卡索风格的艺术品。
总之,AI绘画技术在艺术领域中的应用极其广泛,为艺术家和大众带来更多的乐趣和新颖的体验。
商业领域
在商业领域中,AI绘画通过提高生产效率、个性化创意、定制化服务以及创新商业模式等方面,提供了更为高效、便捷、经济、个性化的解决方案,具有广泛的商业价值,可应用于广告设计、游戏设计、室内设计、时尚设计等众多领域,对于提升市场竞争力和赢得商业成功有着重要作用。
广告设计
在广告设计领域,AI绘画技术被广泛应用。广告商可以使用AI绘画技术来制作广告图像,并在广告中使用。例如,一家健身房可以使用AI图像生成技术,生成一些身体健康和锻炼的图片来吸引目标群体,也可以使用AI绘画技术来制作广告的视频和动画。此外,AI技术也可以帮助广告商根据用户信息来创建个性化的广告,从而更好地吸引和留住客户。
游戏设计
AI绘画技术在游戏设计领域也被广泛应用。游戏公司可以通过使用AI绘画技术来创建各种游戏画面、人物形象、场景布局等。例如,一款叫”灵魂之城(Soul City)”的游戏,利用AI技术生成了城市的3D模型,同时还能够根据用户输入的参数和设计要求,进行场景的生成和优化。

室内设计
AI绘画技术在室内设计领域的应用也非常广泛。设计师可以使用AI技术生成不同方案的3D模型,并进行不同场景的渲染,并对不同颜色和质感进行定制和选择,以帮助他们更好地为客户设计合适的空间和装饰方案。这些工具可以让设计师更快地获得反馈,从而更为快速地完善设计方案并进行调整和修改。
时尚设计
AI绘画技术在时尚设计领域的应用也是越来越流行的。能够使用AI绘画技术创建和设计各种时尚单品,如时装、鞋子、手袋、珠宝等。它们可以对最新的时尚趋势进行追踪,并为设计师提供创作灵感和图像,从而帮助他们更好地设计和制作出符合市场需求的时尚品。
AI绘画技术在商业领域中的应用范围非常广泛,AI技术可以帮助企业更好地发掘潜在市场、提高效率和创造更多的商业价值。
展 望 篇
AI绘画是处在快速发展阶段的技术,未来有着广阔的发展前景。
发展前景
应用领域广泛:AI绘画将为诸如美术、设计、工程等领域提供更好的解决方案。它可以被应用于各种场景,如电影、视觉效果、游戏、衣着和化妆品设计等多个领域,未来可能继续拓展。
提高生产效率:传统的美术设计通常需要大量的时间和人力,而使用AI绘画技术可以根据需要快速生成设计,从而节省时间和成本,挖掘更多的潜在价值。
用户体验升级:AI绘画技术的应用能够为用户量身定制作品,或者用户直接参与产品制作,让用户体验到更个性化的服务。
产生新的商业模式:为创新提供更多的想象空间和创造性的可能性,从而创造出新的商业模式,如AI交互游戏等。
面临的挑战
AI学习能力的限制:AI学习能力当前面临着数据质量、算法优化和可解释性等挑战。可以通过数据清洗、去重、填充缺失值、异常值处理等方法提高数据质量;可以通过平衡准确性和效率,进一步优化算法;通过数据可视化手段提高模型可解释性。
算力上的挑战:AI绘画在算力上面临着挑战,模型训练和生成绘画都需要大量的计算资源。未来可以基于算力网络强大的计算能力,加速AI绘画算法的运行速度和效率,从而实现更高质量的图像生成。
知识产权问题:AI绘画技术是基于大量的已有作品作为学习资料的,会带来版权和知识产权方面的问题,需要健全对应的政策和法律保护。
人工智能伦理问题:人们对人工智能的伦理和安全有着普遍的担忧,如用于训练资源导致的算法偏见等。因此需要制定相关的规范和标准和必要的监管,以确保技术的安全。
机会与挑战并存,相信随着技术的不断发展和社会的需求日益增长,AI绘画技术会成为美术设计领域的重要组成部分,为我们带来更多的惊喜和创新。
作者:赵磊、毕蕾
审核:单华琦
1. An introduction to Stable Diffusion (https://medium.com/sogetiblogsnl/an-introduction-to-stable-diffusion-efd5da6b3aeb)
2. The Illustrated Stable Diffusion (https://jalammar.github.io/illustrated-stable-diffusion/)
3. Stable Diffusion、DALL-E、Imagen 背後共同的套路(https://www.youtube.com/watch?
v=JbfcAaBT66U&t=6s&ab_channel=Hung-yiLee)
4. stable diffusion 原理是什么(https://www.nolibox.com/creator_articles/principle_of_stablediffusion.html)
5. How Do AI Text-to-Image Generators Work? (https://www.zmo.ai/how-do-ai-text-to-image-generators-work/)
6. https://labs.openai.com/
7. https://stablediffusionweb.com/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。