
本文提出了一种新方法来利用封装在预训练的文本到图像扩散模型中的先验知识来实现盲超分 (SR)。具体来说,通过使用 time-aware enoder,可以在不改变预训练生成模型的情况下获得较好的修复结果,保留生成先验的同时并最小化训练成本。为了弥补扩散模型固有的随机性导致的保真度损失,引入了一个可控的特征包装模块,允许用户通过在推理过程中调整一个标量值来平衡质量和保真度。此外,还设计了一种渐进式聚合采样策略来克服预训练扩散模型的固定大小限制,从而能够适应任何分辨率。
论文题目:Exploiting Diffusion Prior for Real-World Image Super-Resolution
论文链接:https://arxiv.org/pdf/2305.07015.pdf
作者:Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C.K. Chan, Chen Change Loy
来源:arxiv
内容整理:张雨虹
方法
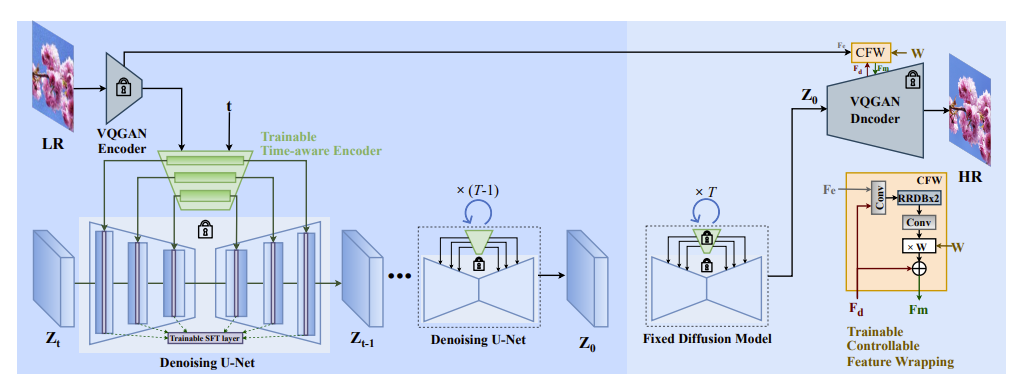
受 Stable Diffusion 生成能力的启发,将其作为先验用于 SR。StableSR 的主要部件是一个 time-aware encoder,与一个冻结参数的稳定扩散模型一起训练,基于输入图像进行调节。为了根据用户偏好实现真实性和保真度之间的权衡,我们遵循 CodeFormer 引入可控的 feature wrapping 模块。
整体框架如上图所示:首先微调连接到固定的预训练 Stable diffusion 模型的 Time-aware Encoder。特征与可训练的空间特征变换 (SFT) 层相结合。这种简单而有效的设计能够利用图像 SR 的丰富先验扩散。然后,保持扩散模型固定,受 CodeFormer 启发,引入了一个可控 Feature Wrapping (CFW) 模块,给定LR 特征 Fe 和固定 VQGAN decoder 的特征 Fd,以残差方式获得调整特征 Fm。通过可调系数 w,CFW 可以实现质量和保真度之间的权衡。
Guided Finetuning with Time Awareness
为了利用 Stable Diffusion 的先验知识,设计了如下约束条件:
- 在 LR 输入条件下,模型需要输出合理的 HR 结果。
- 模型对原始 Stable Diffusion 进行最小的改动以防止破坏原始模型中的先验知识。

Time-aware Guidance:利用编码器中的 time-embedding 层合并时间信息可以显著提高生成质量和保真度,并且可以自适应的调整 LR 特征条件的强度。从信噪比的角度对这种现象进行了分析:
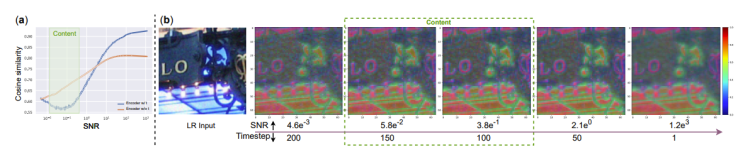
在生成过程中,生成图像的信噪比随着噪声去除而逐渐增加,当 SNR 接近 5e-2 时,图像内容会迅速填充。根据这一观察,提出的 encoder 旨在为 SNR 达到 5e -2 的范围内的扩散模型提供相对较强的条件,在此阶段生成的内容会显著影响超分辨率性能。为了进一步证实这一点,使用 SFT 前后稳定扩散特征之间的余弦相似度来衡量 encoder 提供的条件强度。不同时间步长的余弦相似度值如上图 (a) 所示,可以观察到,余弦相似度在 5e -2 的 SNR 附近达到其最小值,表明编码器施加了最强条件。此外,图 (b) 中描述了从encoder 中提取的特征图,5e -2 的 SNR 点周围的特征更清晰并且包含更详细的图像结构,因此假设这些自适应特征条件可以为 SR 提供更全面的指导。
Color Correction:扩散模型有时会出现颜色偏移,为解决这一问题,对生成图像进行颜色归一化,使其均值和方差与 LR 输入的均值和方差对齐,公式如下:
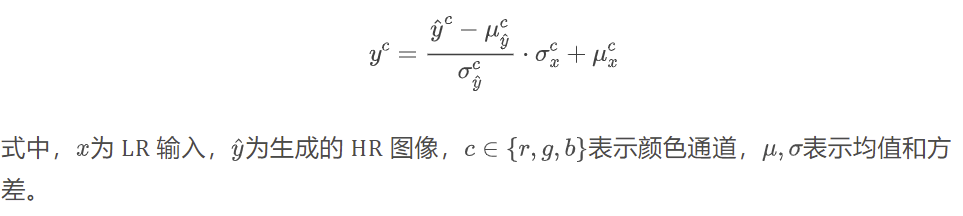
Fidelity-Realism Trade-off
由于扩散模型具有随机性,生成可能会偏离基础,因此引入 Controllable Feature Wrapping (CFW) 模块来实现真实性和保真度的平衡。

Aggregation Sampling
尽管具有完全卷积的性质,但当与训练设置不同分辨率时,Stable Diffusion 往往会产生较差的输出。常见解决方法是将较大的图像拆分为几个重叠的小块,然后单独处理每个块,但在扩散迭代过程中,块之间的差异会被复合和放大。采用了一种渐进patch 聚合采样算法来处理这一问题,首先将低分辨率图像编码为潜在特征图,然后将其细分为多个重叠小块(64×64,与训练分辨率相匹配),在反向采样时,每个 patch 单独处理。为了整合处理结果,使用中心高斯核为每个 patch 生成大小为 64×64 的权重图,对重叠像素进行加权处理。
实验
细节
基于 Stable Diffusion 2.1-base ,time-aware encoder 与去噪 Unet 的部分结构类似,但是更轻量(~105M,包括 SFT 层)。finetune Stable Diffusion 117epochs,batch size192,prompt 固定为空。学习率 5e-5。训练 512× 512 分辨率在 8 8 NVIDIA Tesla 32G-V100 GPU 进行。推理阶段采用 DDPM 采样 ,时间步长为 200。为了处理任意大小的图像,对超过 512×512 的图像采用了聚合采样策略。对于512×512以下的图像,我们首先使用零填充将LR图像放大到512×512,生成后去除填充部分。
训练 CFW,首先按照 Real-ESRGAN 中的退化方式生成 100k 个分辨率为 512×512 的合成 LR-HR 对。然后采用微调后扩散模型在给定 LR 图像作为条件的情况下生成相应的潜在代码 Z0。训练损失与 VQGAN 基本相同,但是使用固定的对抗损失权重 0.025。
结果


消融性实验
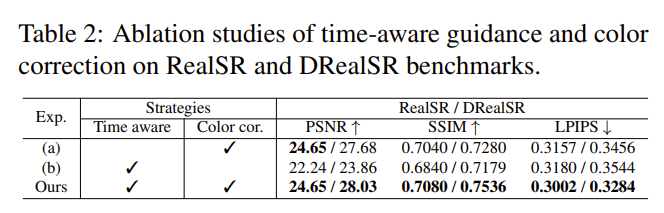
Importance of Time-aware Guidance and Color Correction:如表 2 所示,移除Time-aware Guidance (即移除时间嵌入层)或颜色校正都会导致 SSIM 和 LPIPS 性能的降低。此外,下图中(a)为没有 time-aware guidance 的结果,会导致纹理的模糊;(b)中没有应用颜色校正,会导致颜色偏移,证明了时间感知指导和颜色校正的有效性

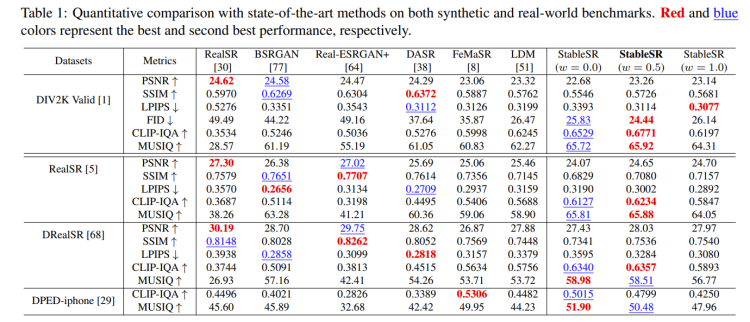
Flexibility of Fidelity-realism Trade-off:CFW 模块可以实现 Fidelity-realism 权衡。给定可控系数 w ∈ [0,1],w 较小时 CFW 倾向于生成逼真的结果,而 w 较大时 CFW 会提高保真度。如表 1 所示,与 StableSR (w = 0.0) 相比,StableSR (w = 1.0) 在所有三个基准测试中均实现了更高的 PSNR 和 SSIM,表明保真度更高。相比之下,StableSR (w = 0.0) 具有更高的 CLIP-IQA 分数和 MUSIQ 分数,实现了更好的感知质量。在下图中也可以观察到类似的现象:

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
