
本工作是由上海交通大学宋利教授带领的Medialab实验室与新加坡管理大学、南安普顿大学合作产出,并被CVPR 2023录用。本文提出了一个基于diffusion model的框架,即FreestyleNet,其可以从给定的布局(layout)生成包含丰富语义的图像。传统的布局到图像生成(Layout-to-Image Synthesis,LIS)方法只能生成训练数据集中固有的语义,如COCO-Stuff中的182类物体。有没有可能在指定的布局上填入训练集外的语义(例如新的类别,属性以及风格)呢?针对这一全新的任务——自由式布局到图像生成(Freestyle Layout-to-Image Synthesis,FLIS),本文基于预训练的文生图大模型Stable Diffusion [1]构建了FreestyleNet。Stable Diffusion能够为我们提供丰富的语义,但是其只支持文本作为输入,如何将这些语义填入指定的布局是一个巨大的挑战。为此,本文引入了修正交叉注意力(Rectified Cross-Attention,RCA)层,并将其插入到Stable Diffusion的U-Net当中。通过限制文本token只在特定的区域与图像token产生交互,RCA实现了将语义自由放置在指定布局上的功能。实验表明,FreestyleNet能够结合文本和布局生成逼真的结果,进一步增强了图像生成的可控性。
标题:Freestyle Layout-to-Image Synthesis
来源:CVPR 2023
作者:Han Xue, Zhiwu Huang, Qianru Sun, Li Song, and Wenjun Zhang
论文链接:https://arxiv.org/abs/2303.14412
项目地址:https://essunny310.github.io/FreestyleNet/
引言
背景
布局到图像生成(Layout-to-Image Synthesis,LIS)是条件式图像生成研究的一个重要分支,其旨在生成符合用户所指定布局的图像。布局的表现形式有很多种,包括目标框、语义分割图和关键点等等。本文所研究的布局为语义分割图,物体需要在指定的语义区域被生成,同时和周边场景保持和谐。已有的LIS方法通常是在特定的数据集上进行学习,因此,生成的图像往往局限于训练集中的语义类别,例如COCO-Stuff中的182类物体。这种域内(in-distribution)的生成极大限制了LIS方法在现实场景中的应用,用户需要重新搜集配对的数据集进行训练才能够生成新的语义。
任务
为了探究LIS模型的域外(out-of-distribution)生成能力,本文定义了一个新的任务,即自由式布局到图像生成(Freestyle Layout-to-Image Synthesis,FLIS)。除了语义分割图,该任务还接收文本作为输入。分割图用来控制生成语义的空间分布,而文本则告诉模型应该生成什么语义。FLIS可以打破传统LIS方法的局限,生成在训练集中未曾见过的语义(包括新的类别,属性以及风格),在增强图像生成自由度和可控性的同时,在开集或长尾分割任务的数据增强上也有着极大的应用潜力。
挑战与本文做法
与LIS相比,FLIS面临的最大挑战在于如何生成训练集外的语义。大规模的预训练视觉-语言模型(例如CLIP)拥有强大的泛化能力,很多下游任务使用这些大模型均取得了很好的少样本(few-shot)甚至零样本(zero-shot)预测效果,比如可以通过CLIP寻找最相关的文本提示来实现对未见过图像的分类。受到这些方法的启发,本文选择利用预训练文生图模型中丰富的先验来实现FLIS。然而,与分类任务可以将文本和图像类别简单绑定不同,从文本生成指定布局的图像具有很大的挑战性。首先,限制文生图模型生成符合指定布局的图像很可能与其预训练的知识产生冲突,需要尽可能保留其强大的生成能力。其次,文生图模型仅仅支持文本作为输入,需要将布局作为新的条件注入预训练模型。一个已有的工作PITI [2],选择训练一个编码器将布局投影到原有的文本空间。然而PITI抛弃了文本编码器,这使得其失去了通过文本自由控制生成结果的能力。同时其新引入的编码器只在文本和布局之间做了隐式的映射,生成图像与输入布局之间的对齐较差。
为了实现FLIS,本文提出了一个简洁有效的框架——FreestyleNet,其在预训练的Stable Diffusion中插入修正交叉注意力(Rectified Cross-Attention,RCA)层,在文生图生成过程中引入了指定的布局。在RCA中,特定区域中的图像token只和相应的本文token进行交互,这保证了文本描述的语义出现在指定的区域中。与此同时,RCA没有引入新的参数,使得FreestyleNet的训练十分高效。
本文贡献
- 本文提出了一个新的任务——自由式布局到图像生成(FLIS),并基于大规模预训练的文生图扩散模型设计了一个框架,其可以同时接收布局和文本作为输入。
- 本文提出了一个无参数的RCA模块,通过将其插入预训练模型中,在充分利用生成先验的同时实现了从指定的布局生成逼真的图像。
- 丰富的实验证明了本文方法在FLIS上的有效性。如图1所示,FreestyleNet可以生成全新的语义,包括但不局限于:(1)生成训练集中未见过的物体;(2)绑定新的属性到已有物体上;(3)将图像渲染为全新的风格。

方法
基于 Stable Diffusion,本文提出了一个自由式布局到图像生成框架——FreestyleNet,整体结构如图2所示。Stable Diffusion使用CLIP的文本编码器从输入得到文本嵌入,进而通过交叉注意力将它们注入到去噪U-Net网络中,经过T步的去噪后得到生成图像。为了令Stable Diffusion能够生成符合指定布局的图像,本文提出了一个修正交叉注意力(RCA)层,以在计算交叉注意力时引入布局,使得语义被放置在指定的区域。
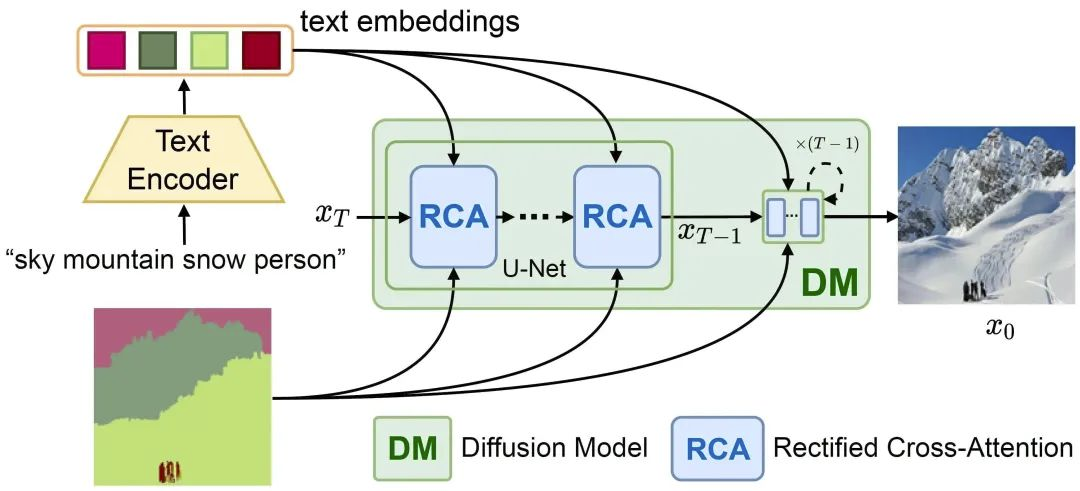
如何表征语义?
Stable Diffusion 能够把文本转换为逼真的图像,为了尽可能保留这一强大的生成先验,本文也选择通过文本来表征语义。具体来说,本文将布局中所出现的所有语义对应的文本堆叠成一个句子(如图2中的“sky mountain snow person”),接着送入到CLIP的文本编码器中得到文本嵌入,作为下一步生成图像所需的语义。
RCA是如何工作的?
有了语义和布局,RCA 需要做的便是将每个语义放置在布局指定的区域中。RCA 的设计思想来源于对 Stable Diffusion中交叉注意力(Cross-Attention,CA)机制的观察。CA接收文本嵌入(text embeddings)和图像特征(image features)两个输入,计算出两者之间的注意力图(attention map),最终输出对文本值(text values)的加权和。注意力图中的每个通道都对应着一个文本嵌入,举例来说,对于输入文本中的一个单词 “cat”,我们可以找到其在注意力图中的那个通道,并且该通道和最终生成图像中猫的空间分布是类似的。因此,通过改变该通道的激活值,我们便可以操纵这只猫在生成图像中的形状和位置。RCA便是利用这一点,通过限制注意力图的空间分布,使得最终生成图像的空间分布和输入布局一致。
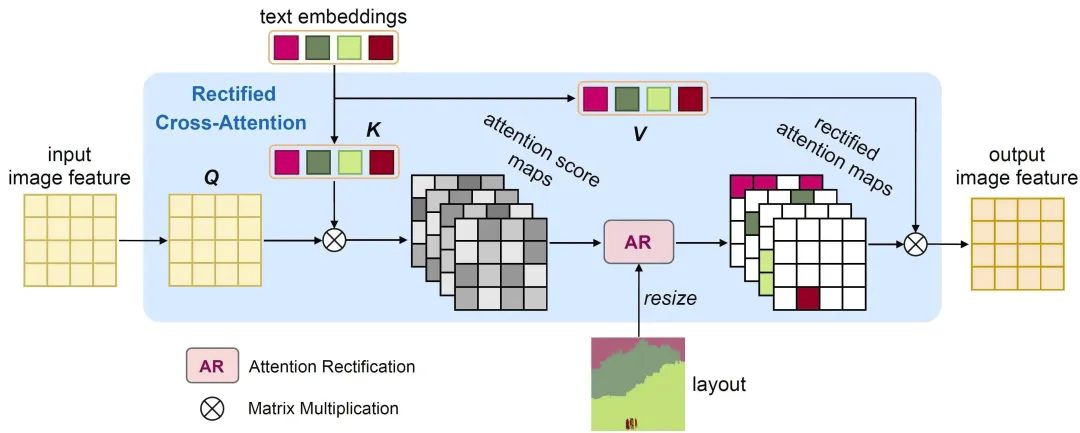

经过 softmax 之后,修正的交叉注意力便成为了和输入布局在空间分布上类似的图,令每个语义仅仅影响输入布局所指定的空间区域。
模型训练
将 CA 替换为 RCA 后,模型便可以在有布局标注的数据集上进行微调了。微调所用的目标函数和 Stable Diffusion 预训练时所用的保持一致,即:

实验结果
自由式布局到图像生成(FLIS)
图 4 展示了 FreestyleNet 在 FLIS 任务上的效果,其中 in-distribution 表示输入文本仅仅包含训练集中的语义(COCO-Stuff 中的 182 个物体类别),而 out-of-distribution 的输入文本则有着训练集外的多样语义。可以看出,FreestyleNet 能够(a)给目标绑定新的属性,(b)指定图像的风格,(c)生成全新的物体。生成图像均有着较高的保真度,同时在保证符合输入布局的前提下忠实反映了输入文本中包含的语义,使得用户可以自由地创造图像。

传统布局到图像生成(LIS)
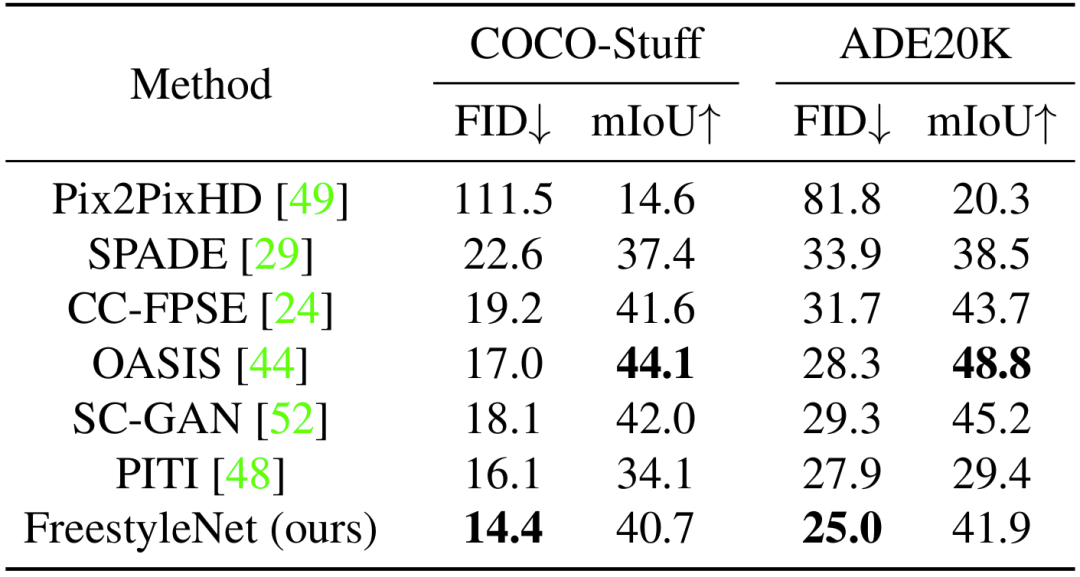
我们也将 FreestyleNet 与传统的 LIS 模型在 in-distribution 的设置下进行了对比,所使用的数据集为 COCO-Stuff 和 ADE20K。定量指标选择了常用的 Fréchet Inception Distance(FID) 和 mean Intersection-over-Union(mIoU),它们分别用来衡量生成图像是否真实以及是否实现了与输入布局的对齐。图 5 和表 1 展示了对比结果,可以看出,FreestyleNet 在 LIS 上也有着优良的表现。

RCA的有效性
为了更加直观地证明 RCA 的有效性,我们在图 6 中给出了两个例子。在第一行的例子中,如果我们令 “sky” 和 “drawn by Van Gogh” 共享同一个修正注意力图(AM),则只有天空的区域被渲染成梵高画的风格。第二行的例子表明我们还能够通过交换两个目标的修正注意力图来实现外貌的交换。它们都说明了RCA 可以让文本描述的语义出现在布局指定的区域中。

结论
本文提出了一项新任务——自由式布局到图像合成(FLIS),旨在给定布局上生成文本所描述的语义(包括训练集外的新语义)。为此,我们充分利用了一个预训练文生图扩散模型(即 Stable Diffusion)的生成先验,提出了一个新的模型—— FreestyleNet。在插入了修正交叉注意力(RCA)模块后,FreestyleNet打破了已有的布局到图像合成(LIS)模型只能进行 in-distribution 生成的限制,能够将输入布局转换为具有各种新颖语义的高保真图像。
参考文献
[1] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, pages 10684–10695, 2022.
[2] Tengfei Wang, Ting Zhang, Bo Zhang, Hao Ouyang, Dong Chen, Qifeng Chen, and Fang Wen. Pretraining is all you need for image-to-image translation. arXiv:2205.12952, 2022.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
