
当我们对音乐的体验不再止步于单纯的演唱与倾听,对音乐演唱及互动反馈有了更多的需求时, KTV 打分功能便应运而生。
传统的线下 KTV,通常会用在 KTV 打分系统中预先存储好每首歌曲的音轨和歌词,以及每个音符的音高、时长和节奏。当你唱歌时,KTV 打分系统会实时地录制你的声音,并将其转换成数字信号,并且 KTV 打分系统会将你的声音信号和原唱的音轨信号进行对比,计算出你的音准、节奏和音色的相似度,从而得出演唱分数。
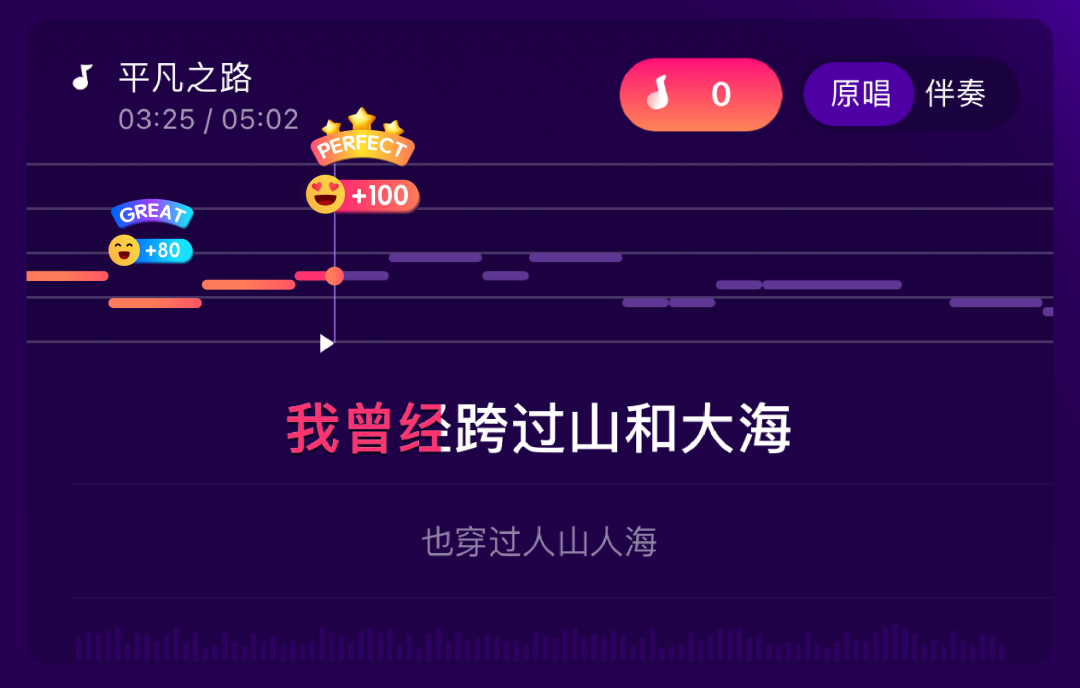
那么,当娱乐阵地逐渐从线下 KTV 转移至线上时,为了满足用户的参与感、还原线下真实 K 歌体验,“打分”这一互动玩法在线上实时互动场景中也是不可或缺的功能。
自研实时打分 音高线提取精确率高达 99%
ZEGO 自研 KTV 实时打分功能,通过分析演唱者的音高进行评判,得出演唱分数,音高线提取精确率高达 99%,增强线上社交互动的可玩性,真实还原线下 KTV 的娱乐体验。
打分功能的具体实现,主要分为以下四个步骤:
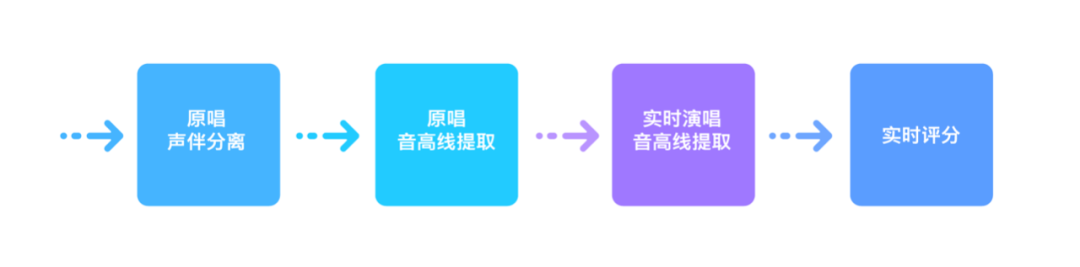
第一步:将原唱做声伴分离,将人声和伴奏分离出来;
第二步:将原唱人声转化成标准音高线,以 MIDI 音高的形式显示在 APP 中;
第三步:提取演唱者实时的人声音高线,同样也以 MIDI 音高的形式显示在 APP 中,用户可以主观体验到自己音高的准确性;
第四步:利用打分算法,根据人声和原唱的差异进行评分。在整个打分功能的实现过程中,我们需要重点关注两个技术能力点的实现:音高线的实现、打分策略算法。
1、音高提取能力高可用
要对演唱情况进行打分,首先要知道评判的标准,打分的标准就是原唱的音高线,这需要我们从各种复杂的音乐中准确地提取出原唱人声的音高线,ZEGO 自研音高线提取算法,音高线提取精确率高达 99%。
音高线的提取是一项很复杂的工作,一般有两种做法,一种是基于机器学习,直接使用卷积神经网络模型来提取音高线。由于模型是在合成数据集上训练和测试的,对于我们实际使用的音乐预料库,音色更复杂、噪声更不可预料的真实数据,这类模型的效果并不尽如人意。因此,ZEGO 使用第二种做法,先将人声从音乐中分离出来,然后基于传统的方法提取人声音高线。
- 人声分离:音乐声伴分离的准确性、保留人声的完整性,对于后续提取人声音高线的效果影响较大。业界基于机器学习的声伴分离的模型是比较成熟的,因此 ZEGO 使用 AI 模型,在尽量保证人声完整性的前提下,分离出信噪比较高、保留较完整的人声。
- 提取音高线:由于音乐的复杂性以及歌曲语料质量参差不齐,很难提取到干净而完整的人声。另外还有很多歌曲人声包含了和声等因素的影响,使得音高线的提取相当困难。因此,ZEGO 在传统算法的基础上结合 HMM 模型选择最优路径音高线,使得音高线提取算法具备很好的鲁棒性。
2、打分策略算法,更贴合用户需求
在用户演唱结束后,演唱分数的高低决定了用户对于平台使用体验的评价高低。
一方面,我们需要在实时场景中给到用户互动的正反馈,吸引用户持续在平台上进行互动,让唱得好的人能突显出最高分数,给予正面激励;另一方面,我们也需要结合用户的心理体验,进行数值策略调整,在不打消用户互动积极性的情况下,给到一个让演唱者自信的分数。
ZEGO 打分算法主要依据用户实时演唱音高线与原唱标准音高线的差异来评判。如果只是根据差异做一个线性的评分,对于用户的体验是不佳的,因为大众用户的演唱水平其实是服从正态分布的,因此 ZEGO 在打分策略算法上,让评分也服从正态分布,对于处于中间分布的大量群体得分达到正常可接受水平,而对于少数唱的很准的顶部群体,需要凸显出高分。
玩转“打分”,先有曲库
ZEGO 在线 KTV 解决方案中配备海量正版曲库,集成多家国内知名音乐版权商,帮你解决版权纠纷问题,曲库收纳 2000 万+ 首歌曲,热门点唱 top 歌曲覆盖率超过 90%,并且对周杰伦等热门明星歌手和抖音等短视频平台的热门歌曲进行了覆盖,更支持动态更新歌曲,热门歌曲随时上,一套 SDK 实现音乐版权的快速接入!

在线 KTV 实时打分功能可以让用户在完成歌曲演唱后对自己的表现进行评价,从而提高用户的参与感和满意度,提升互动竞技性。同时,实时打分功能还可以帮助用户更好地了解自己的歌唱水平,对于想要提高唱歌技巧的用户来说,打分功能也是一个很好的参考。
目前,实时打分功能已集成在 ZEGO 在线 KTV 实时合唱解决方案中,客户可以按照需求选择进行使用,并且设置了 5 种演唱难度等级,平台可以按需调整用户演唱的得分难度。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/25108.html
