
这篇文章提出了从预训练深度模型中提取局部深度排序先验信息。有了该约束,SparseNeRF显著提升了NeRF在稀疏视角输入场景下的表现。此外,为了保持场景的连续几何结构,还提出了一种空间连续性约束,以约束 NeRF 的空间连续性与预训练深度模型接近。
来源:arxiv
作者:Wang G, Chen Z, Loy C C, et al.
论文链接:https://arxiv.org/pdf/2303.16196.pdf
内容整理:高弈杰
介绍及相关工作
神经辐射场(NeRFs)通过对场景隐式表征,输入2D的纹理图像进行训练,训练好的模型能在新视角上完成高质量的渲染。然而NeRF十分依赖密集的视角输入,实际的很多场景并不会提供稠密的输入视角,因此有必要研究能够用少量数据学习的神经辐射场模型,并且这些模型能够从稀疏视图中学习场景,在新视角上的渲染结构不会有明显的质量降低。
直接从稀疏的输入视角学习场景是一个非常有挑战性的任务,如果直接用NeRF的颜色监督来训练,将会导致模型在新视角下的推理结果很糟糕。最近,有关研究的提出能够有效提升NeRF在稀疏视角输入下的表现。根据使用方法的不同可以分为三类,分别是:1)基于几何约束(稀疏性和连续性正则化)和高级语义来实现少样本学习的方法,如RegNeRF、InfoNeRF。2)在相似场景上进行预训练的方法,如PixelNeRF。3)使用深度先验进行深度监督的方法,如DS-NeRF,MonoSDF。
本文是在第三种方法上做进一步的优化,即从场景粗糙深度图中提取更准确的深度先验信息,帮助NeRF在稀疏视角输入下更好地对场景进行学习。本文提出从预训练的深度模型或消费级别的深度传感器估计的不精确深度图中提取深度先验信息。本文采用了采用了相对深度而非绝对深度的方式对 NeRF 进行监督,通过松弛深度约束并在粗略深度图中提取鲁棒的局部深度排序信息,使得 NeRF 的深度排序与粗略深度图保持一致。同时,为了保证几何空间的连续性,本文还在深度图上提出了空间连续性约束,使得 NeRF 模型能够模拟粗略深度图的空间连续性。通过结合来自有限视角的准确稀疏的几何约束以及包括深度排序正则化和连续性正则化等放宽的约束,SparseNeRF 最终实现了可观的新视角合成。值得注意的是,在推理过程中,SparseNeRF 不会增加运行时间,因为它仅在训练阶段利用来自预训练深度模型或消费级传感器的深度先验信息。此外,SparseNeRF 是一个即插即用的模块,可以轻松地集成到各种 NeRF模型 中。
本文的贡献可以归纳如下:
- 提出SparseNeRF,可以从预训练深度模型中提取局部深度排序先验信息。有了该约束,SparseNeRF显著提升了NeRF在稀疏视角输入场景下的表现。此外,为了保持场景的连续几何结构,本文提出了一种空间连续性约束,以促进 NeRF 的空间连续性与预训练深度模型接近。这种深度排序先验和空间连续性约束都是 NeRF研究中的新方法。
- 贡献了一个新的数据集,名为NVS-RGBD,其中包含来自Azure Kinect、ZED 2 和iPhone 13 Pro的粗略深度图。
- 在LLFF、DTU和NVS-RGBD数据集进行了广泛的实验,证明SparseNeRF 在少样本新视角合成方面取得了新的最先进性能。
方法
模型概述
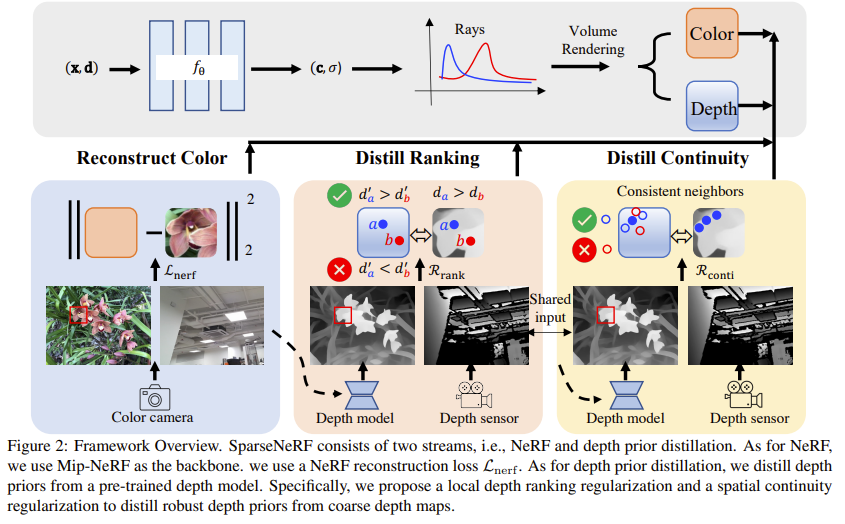
SparseNeRF 主要由四个组件组成,包括神经辐射场(NeRF)、颜色重建模块、深度排序模块和空间连续性模块。具体而言,SparseNeRF使用Mip-NeRF作为主干网络,并采用均方误差(MSE)损失函数进行颜色重建。在深度先验提取方面,可以使用预训练的深度模型来估计深度图,也可以使用消费级深度传感器捕获粗糙深度图。本文使用在大规模混合深度数据集(1.4M张图像,包含各种深度注释)上训练的视觉变换器(DPT)来生成深度先验。由于单目深度估计较为粗略,本文专门设计了局部深度排序正则化和空间连续性正则化,从粗略深度图中提取鲁棒的深度先验并应用于NeRF模型中。
局部深度排序
给定单张图像中的一对像素点,使用深度排序正则化只会考虑哪些点离得更近,哪些点离得更远。而当场景变得复杂时,深度排序正则化就会变得不靠谱,如图所示。

深度估计模型很容易地就能比较出绿色和蓝绿色点的深度关系,但是很难判断绿色点和红色点哪个点更近。这意味着深度排序的难度会随着空间距离的增加而增加,而这也是局部深度排序的提出的出发点。

空间连续性约束
局部深度排序约束保证了NeRF估计的深度图与DPT生成的深度图一致,但它并不约束深度图的空间连续性。本文从深度模型DPT中提取了空间连续性先验,这允许跨越多个深度像素的大位移。如果DPT生成的深度图中相邻像素点的深度连续,也会约束NeRF在相应的像素位置的深度连续,公式如下:
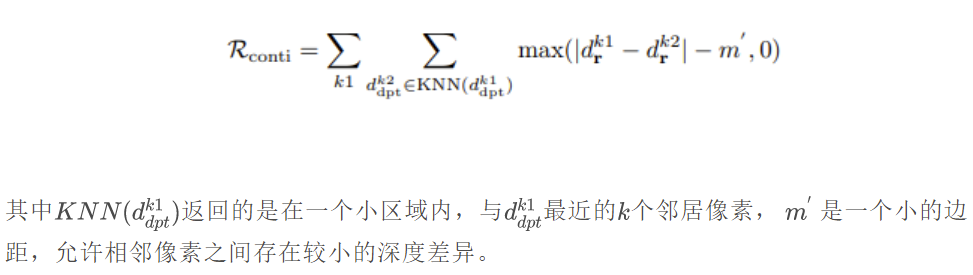
损失函数

实验
实验细节
选择LLFF、DTU、NVS-RGBD(本论文提出的)这三个数据集。评估指标选择PSNR,SSIM,LPIPS和深度误差这四个。使用JAX实现了SparseNeRF算法,选择Adam优化器,使用指数学习率,初始学习率为,衰减到。batchsize大小为4096。对于每个场景,使用一块GPU-v100进行训练和推断,与之前的方法使用相同的骨干网络和采样点。在一块GPU V100上训练一个场景大约需要1.5小时。
实验结果
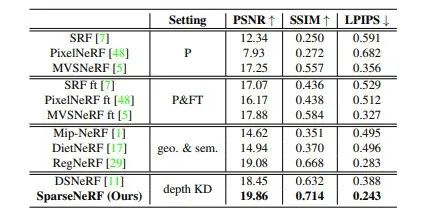
在LLFF数据集上的实验结果

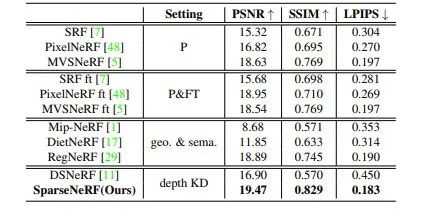
在DTU数据集上的实验结果

在NVS-RGBD数据集上的实验结果

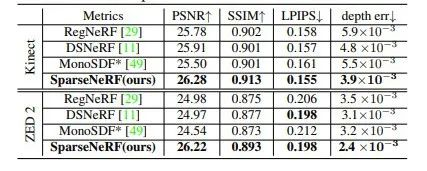
从以上实验结果中可以看出,SparseNeRF在上述数据集的测试集上的推理结果均超过了现有针对稀疏视角输入场景的NeRF模型。
结论
本文提出了一种SparseNeRF框架,用于在稀疏视图输入的场景下合成新视图。为了解决少样本NeRF的欠约束问题,本文提出了一种局部深度排序正则化方法,从粗糙的深度图中提取深度排序先验。为了保留几何学的空间连续性,还提出了一种空间连续性正则化方法,从深度连续性先验中提取空间连续性先验。使用所提出的深度先验,SparseNeRF在三个数据集上实现了最新的最佳性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
