
人工智能三维生成是指利用深度神经网络学习并生成物体或场景的三维模型,并在三维模型的基础上将色彩与光影赋予物体或场景使生成结果更加逼真。在应用中,生成物体或场景的三维模型称为三维建模,生成三维模型的色彩与光影称为三维渲染。
主要类型
三维生成中学习与生成的三维数据可分为显性表达数据与隐性表达数据两类,显性表达数据主要包括体素栅格、点云与网格;隐性表达数据是以神经网络参数表达的三维场景,即神经场。根据学习与生成的三维数据类型,人工智能三维生成可以分为显性数据驱动型与隐性数据驱动型。
在利用人工智能技术前,传统的三维生成工作中全部使用显性表达的三维数据,因此早期人工智能三维生成的研究同样聚焦于学习并生成显性表达的三维数据,这类人工智能三维生成可以称为原生三维型。
人工智能直接学习与生成三维数据存在诸多问题,其中的重点问题之一是可学习的三维数据量小且不满足多样性要求。为解决这一问题,许多人工智能三维生成的研究聚焦于从二维图像中学习并生成三维数据,这类人工智能三维生成可以称为二维升维型。
技术发展的关键阶段
2018年前受限于技术发展,仅有原生三维型人工智能三维生成应用,使用的模型有VAE模型、流模型、GAN模型、EBM模型、扩散模型等,其中GAN模型在生成效果方面的优势使其在2022年前一直是人工智能三维生成的主流模型,但由于训练难度极大,对硬件要求极高等问题,产业级应用发展十分受限。
由于二维图像生成技术的快速进步与应用的蓬勃发展,因此二维升维型是目前人工智能三维生成研究与应用的关注重点。
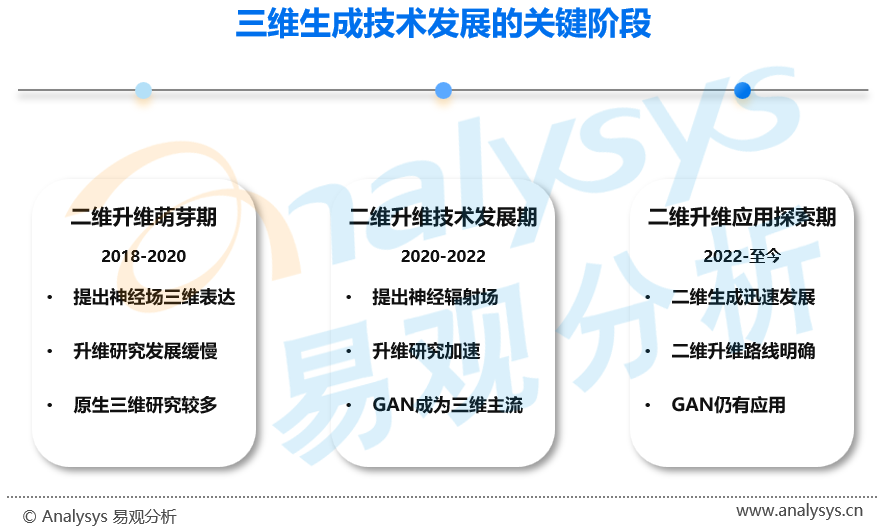
● 2018年-2020年:二维升维萌芽期
2018年,将三维内容表达为神经网络参数的神经场诞生。虽然神经场表达的仍然是三维数据,且由于缺乏学习数据在2018年至2020间其发展速度十分缓慢,但为二维升维派奠定了技术基础。
● 2020年-2022年:二维升维技术发展期
2020年,伯克利、谷歌与加大圣地亚哥分校的联合团队提出神经辐射场(NeRF)算法。神经辐射场算法可以从静态二维图像中感知其三维属性,生成内容统一但视角不同的二维图像,即具备三维感知的图像。由于生成的图像精度高且可以生成大场景的三维感知图像,因此受到广泛关注且出现大量相关研究,加速二维升维技术发展。在应用方面,由于训练难度大、对硬件要求高、生成效率低等问题,仅能进行试验性与娱乐性的小范围应用。在产业应用方面,虽然出现将显性表达与隐性表达相结合的相关研究,但除以上问题外,在与传统三维生成工作的衔接和满足产业应用要求方面仍然存在诸多问题,因此产业应用发展缓慢。
● 2022年-至今:二维升维应用探索期
2022年中,以Stable Diffusion、Dall·E为代表的二维图像生成应用快速发展,生成的二维图像质量与想象力迅速提升。得益于此,二维升维型三维生成应用的商业化价值进一步提升,产业界对其关注度因此迅速提升,技术发展再次提速。目前,二维升维型三维生成的训练难度、对硬件要求、生成效率等仍然是其应用商业化的巨大阻碍,但产业界公司加强了其与传统三维生成工作的衔接性,并尝试开发产业级应用,二维升维型三维生成应用的商业化仍然有待探索。
主流模型实现原理及优缺点
● Dream Fields模型
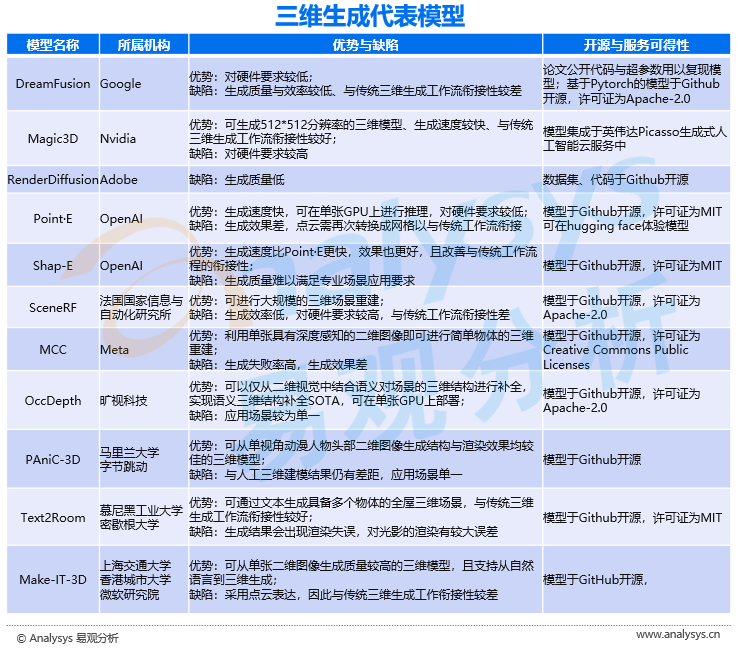
2021年末,Dream Fields模型首次将CLIP¹模型与NeRF模型相关联,利用CLIP从文本到二维图像的生成能力,结合NeRF从二维图像学习三维结构与纹理渲染的能力,实现从自然语言到三维的生成。
Dream Fields模型证明了CLIP模型可以与NeRF模型结合应用,并突破了以往三维生成模型在想象力方面的限制。但Dream Fields模型生成的三维内容的结构仍然较为简单,因此不能生成大规模的三维场景,且其三维渲染效果较差。此外,Dream Fields模型的生成效率很低,与传统三维生成工作的衔接性也较差,因此并不具备商业化价值。
注:1.请参考《AIGC产业研究报告2023——图像生成篇》
● CLIP-NeRF模型
与Dream Fields同一时期提出的CLIP-NeRF模型同样将CLIP模型与NeRF模型进行关联,与Dream Fields模型不同的是,CLIP-NeRF模型更加注重以自然语言或二维示意图对生成的三维模型与三维渲染效果进行调整。但在生成效果与商业化价值方面,CLIP-NeRF模型与Dream Field模型存在同样的问题。
虽然存在种种缺陷,Dream Fields模型与CLIP-NeRF模型展示了人工智能三维生成的应用潜力,验证了以自然语言进行三维生成的技术可行性,且探索了以自然语言改进生成结果的可能性。
● DreamFusion模型
2022年9月,Google提出的DreamFusion模型以Dream Fields模型为基础,用扩散模型得出概率密度蒸馏损失函数以替代CLIP模型,提升了从自然语言到三维内容的内容统一性,且证明可从单张二维图像生成三维模型具备可行性。
虽然DreamFusion提升了三维模型的结构准确性与渲染的真实性,提升生成效率的同时降低了对硬件的要求,但其生成的三维内容在规模、渲染与结构细节方面仍然不满足产业级应用的要求,且Dream Fusion模型在原理上即与传统三维生成工作的衔接性差,因此仍然难以进行商业化。
● Magic3D模型
2022年11月,英伟达(Nvidia)提出的Magic3D模型在DreamFusion的基础上提出了两步优化策略:首先用与DreamFusion相似的扩散模型生成低分辨率、简单渲染的哈希网格三维模型,之后再采用与传统计算机图形学相似的方法对三维模型进行更高质量的渲染。
与DreamFusion相比,Magic3D模型生成的三维模型分辨率更高,且渲染效果更好,生成效率也有了显著的提升。由于Magic3D模型的渲染方式与传统计算机图形学有非常紧密的关系,且其生成结果可以直接在标准的图像软件中进行查看,因此Magic3D模型可以更好地与传统三维生成工作进行衔接。鉴于各方面优势,Magic3D模型已经具备进行产业应用的能力基础。
在Magic3D模型之后,学界与业界也提出了更多三维生成模型,在生成质量、生成效率、硬件需求、场景应用等方面均进行了更深入的探讨,也有着较为明显的优势与缺陷。
影响模型应用能力的关键因素
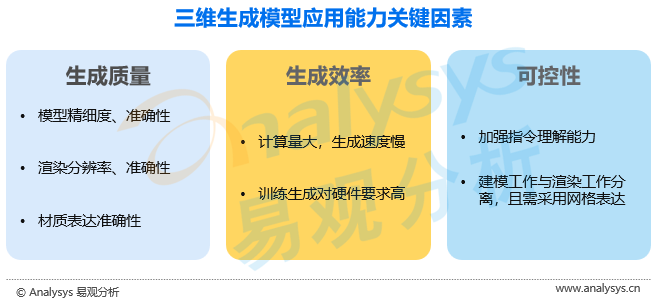
● 生成质量
三维生成的内容质量包括三维模型的精细度、模型的准确性、三维渲染的分辨率、渲染的色彩与光影的准确性、渲染对材质的表达等多个方面,在应用中对三维内容的质量有较高的要求。相比于传统三维生成,目前人工智能三维生成的生成质量仍然存在一定差距。
● 生成效率
与生成二维图像不同,三维生成由于维度的增加,生成过程中所需计算量呈指数级上升。由于庞大的计算量,目前人工智能三维生成的效率较低,多数模型的生成效率难以满足实际应用中的要求。且模型在训练与推理过程中需要占用大量存储空间,因此目前多数人工智能三维生成成本较高。
● 可控性
对三维内容的可控性主要包括是否可以生成符合要求的三维内容、是否可以根据要求对生成的三维模型与三维渲染效果进行修改。目前人工智能三维生成模型在三维内容方面可以满足应用的基本要求,但是在修改方面的表现仍然差强人意。满足应用中修改功能要求的方法有两种,一种是继续加强模型对自然语言指令与图像指令的理解能力,这种方法主要需要技术上的持续突破。但由于技术突破的不确定性,使模型可以与传统三维生成工作进行衔接的方法则更有可行性,这要求模型可以将三维建模工作与三维渲染工作分离,且生成的三维模型必须为网格数据。
典型产业应用场景
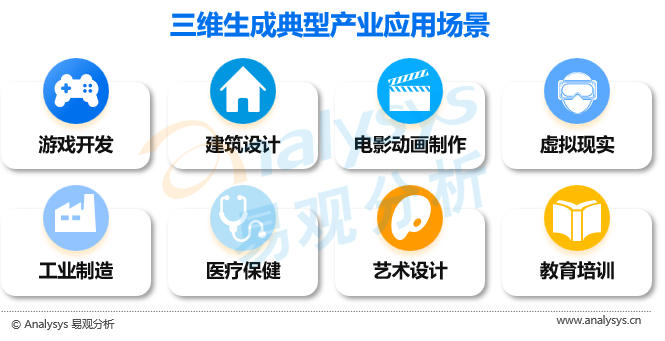
● 游戏开发
游戏开发者可以使用三维生成技术快速地创建逼真的三维场景和虚拟角色,提高游戏的真实感和沉浸感。
● 建筑设计
建筑设计师可以使用三维生成技术更快速地创建建筑模型和可视化效果图,提高设计的效率和准确性。
● 电影和动画制作
制片人可以使用三维生成技术创建逼真的三维场景和角色,并实现复杂的视觉效果,提高电影和动画的质量和观赏性。
● 虚拟现实
虚拟现实应用开发者可以使用三维生成技术创建逼真的虚拟世界和角色,提高虚拟现实的真实感和沉浸感。
● 工业制造
制造商可以使用三维生成技术更快速地创建零部件和模具,提高生产的效率和准确性,降低制造成本。
● 医疗保健
医生和研究人员可以使用三维生成技术创建逼真的人体器官模型和医疗设备,用于医疗教育、手术模拟和疾病诊断等领域。
● 艺术设计
艺术家和设计师可以使用三维生成技术创建数字艺术品、数字雕塑和其他创意作品,提高创作的效率和表现力。
● 教育培训
三维生成技术在教育培训中应用广泛。教师和学生可以使用三维生成技术更好地理解和学习复杂的科学和技术知识,提高教学效果和学习效率。
市场主流应用
传统三维生成工作流程可以大致分为生成三维模型与渲染三维模型两部分,出于产业应用对可控性的要求会将这两部分分开,因此目前市场上人工智能三维生成应用可以分为可以完成这两部分工作的应用,与仅能完成三维渲染工作的应用。
● 海外市场情况
目前海外市场的三维生成工具部分来自英伟达、Meta等科技巨头,部分来自OpenAI、Luma、Kaedim、Meshy等创业公司。
英伟达作为计算机图形学领域的老牌科技公司,在三维生成领域有着优秀的产品生态与合作伙伴生态。英伟达开发的Magic3D模型既可以完成三维建模工作也可以完成三维渲染工作,且英伟达宣布其生成式AI云服务平台Picasso将上线Magic3D模型。英伟达与素材供应商Shutterstock的合作保证其三维生成在版权方面的合法性,并将与Adobe合作探索人工智能三维生成的应用场景。
Meta开源的MCC模型实现了从单张具有深度感知的二维图像即可进行三维重建,但MCC模型仅能生成简单的三维模型,且生成过程具有较高的失败率,生成效果也较差。
OpenAI开源的Point·E模型支持从自然语言到三维生成,生成速度极快,且应用中对硬件要求较低,但生成质量较差,且由于生成的三维数据采用点云表达,难以满足与传统三维生成工作流的专业应用的需求。而之后开源的Shap-E模型在生成速度与效果方面较Point·E有了较大提升,且采用网格与NeRF的双重表达,但生成质量距离专业应用要求仍有较大差距。
Luma作为专注于三维生成的人工智能创业公司,目前已经上线移动端Luma AI应用,可以仅使用移动端摄影设备实现真实的三维物体重建,同时开放从视频到三维生成功能的API接口以支持开发者将此功能接入工作流。
Meshy作为专注于三维生成的人工智能创业团队,目标是帮助游戏开发者与三维内容艺术家更快地进行创作。目前可在Discord社区内应用Meshy的三维模型渲染功能,其功能包括以自然语言生成三维渲染模型和从二维概念图生成三维渲染模型。Meshy也宣布日后将发布其人工智能三维建模工具。
● 中国市场情况
目前中国市场的三维生成工具既来自阿里云、华为云、商汤、旷视等老牌科技厂商,也来自太极图形、上海交通大学等创业团队与研究机构。
阿里云、华为云、商汤等老牌科技厂商的三维生成应用均基于行业应用场景与行业解决方案展开。如阿里云的全息空间产品侧重于对现实空间的三维还原,目前主要行业应用场景为利用建筑信息模型(BIM)还原建筑三维空间信息与在线上还原线下店铺。商汤则利用其空间三维生成产品SenseMARS为房地产营销打造线上三维看房解决方案,而其琼宇SenseSpace与格物SenseThings则是面向场景与物体两个尺度的人工智能三维生成工具。旷视开源的OccDepth模型可以通过二维视觉输入中的语义对场景的三维结构进行补全,且对硬件需求小,模型针对的应用场景为自动驾驶中的道路检测。
而中国市场的创业团队与研究机构则更加倾向于从技术底层促进三维生成应用的发展。太极图形作为一家创业型图形软件公司,其开发的Taichi并行编程语言正在支持更多三维生成模型,为三维生成应用于移动端做出贡献。来自上海交通大学、香港城市大学与微软研究院的团队提出的Make-IT-3D模型大幅提升了人工智能进行三维重建的能力,可以从单张二维图像生成质量较高的三维内容,并支持从文字生成三维内容与三维渲染调整。
商业化过程中面临的挑战
● 场景应用落地挑战
目前人工智能三维生成模型在生成质量、生成效率与可控性方面仍然存在诸多问题,而在短时间内问题无法解决的前提下,人工智能三维生成需要寻找合适的应用场景才能实现应用落地。
目前,三维生成的应用场景可以大致分为面向专业人士的场景与面向普通消费者的场景。面向专业人士的场景必然需要人工智能三维生成的能力满足工业产线级的应用要求,如高质量的生成、高度的可控性,另外也需要满足专业场景的特殊应用需求,如游戏与电影行业的三维生成需要具有想象力现实化的能力,工业、建筑业与医疗需要三维生成具有高度的准确性等等。而面向普通消费者的应用场景对人工智能三维生成的生成质量与可控性要求相对较低,但面向普通消费者的应用却普遍对生成效率有着较高的要求。
无论是哪类应用场景,更重要的问题是如何应用人工智能三维生成可以带来更高的经济效益,而目前人工智能三维生成能力上的不足也大幅减少其可以商业化落地的场景。
● 版权挑战
版权问题是从二维图像生成实现商业化应用以来一直困扰AIGC产业的问题,而这一问题也将从二维图像生成延续至三维生成。目前许多人工智能三维生成应用仍然需要大量的文本数据与二维图像数据作为训练模型的基础。如果这些数据来源于版权受保护的资产,那么使用这些数据进行商业化行为就容易涉及版权问题。
● 技术革新挑战
目前许多人工智能三维生成的有机会商业化的应用场景,如电影制作、产品概念设计、游戏三维资产制作等,在实际应用中用户接受的仍旧是二维图像。此类应用场景目前仍然应用三维生成的原因是需要保证画面内容在不同视角下的统一性,因此目前三维生成在这些场景下仍然具有其独特的应用价值。
但二维图像生成的技术进步速度较快,若在此类应用场景中,二维图像生成应用可以保证用户接受的二维图像在不同视角下的内容统一性,那二维图像生成在此类应用场景中将大范围取代三维生成。
除此之外,若人工智能语言生成发展迅速,则可以训练专用于操作传统三维生成工具的语言模型,也可能全面取代人工智能三维生成模型。
前沿探索与趋势展望
随着技术的进步,人工智能三维生成模型的生成质量、生成效率与可控性均有望实现大幅提升。可控性方面,人工智能三维生成与传统三维生成工作流程的衔接性将更强,将有越来越多的模型采用逐级生成,每级生成内容均可于传统三维生成工作软件中查看与修改再返回模型的能力,提升人工智能三维生成在专业应用场景中的辅助作用。在此过程中,需要开源技术社区的大量贡献,也有可能与语言生成应用结合使用以增强自然语言对三维生成结果的操控性。
而随着生成质量与生成效率的提升,一站式的人工智能三维生成也将进入更多消费应用场景,加速数字孪生与元宇宙的发展。而人工智能三维生成也将拓展其能力,如学习不同材质的物理属性、组织的生物特性、分子的化学特性等,提升其在工业、建筑与医疗等专业领域的应用价值。
AIGC产业研究报告系列共分为六个部分,包括语言生成篇、图像生成篇、音频生成篇、视频生成篇、三维生成篇、分子发现与电路设计篇,并将在本月陆续发布,欢迎关注并与我们共同探讨AIGC产业发展。
作者:陈一墨 易观分析
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
