
为了在商用非专用硬件上使用来自不同供应商的元素构成可扩展的基于软件的广播系统,并避免在设施和云中的锁定,需要采用混合多云方法。作为一个案例研究,本文构建了一个可扩展的边缘平台,用于转码、人工智能(AI)推理和其他视频和音频处理。多架构、容器化应用程序使用 Kubernetes 进行部署和管理。这提供了对硬件资源(包括图形处理单元(GPU)和支持 ST 2110 的网络接口控制器(NIC))的精细分配。使用网络化媒体开放规范(NMOS)实现了服务发现和连接管理。
作者:Thomas True; Gareth Sylvester-Bradley
来源:SMPTE Motion Imaging Journal Volume: 132
文章题目:COTS (Commercial-off-the-Shelf) Platform for Media Production Everywhere
链接: https://ieeexplore.ieee.org/document/10058738
内容整理:鲁君一
引言
这项工作受到了广播公司的目标的影响,他们希望委托和发展可扩展的基于软件的广播系统,由来自不同供应商的元素组成,使用商用非专用硬件,在设施和云中避免锁定。这些软件元素需要支持通用控制、与企业管理系统集成以及足够的自动化水平。
为此,广播供应商的软件需要:
- 在任何地方运行,包括在本地或任何云服务提供商(CSP)中
- 支持精细的资源分配
- 使用标准和开放规范实现控制和传输互操作性,以集成来自多个供应商的元素
- 利用信息技术(IT)最佳实践,例如监控、安全和编排。
该案例研究演示了一个基于商用非专用硬件和开放软件架构构建的实用媒体处理平台,可以轻松地在云的边缘执行转码和AI处理。
硬件配置
这个边缘媒体处理平台是使用商用非专用硬件构建的。平台的主要组成部分包括一个或多个图形处理单元(GPU)用于转码和其他视频和音频处理,以及一个或多个网络接口控制器(NIC)用于基础类型流的网络输入/输出(I/O)。构建了两种不同的配置:一种是在数据中心中发现的典型大型边缘服务器,另一种是不需要数据中心基础设施并可安装在桌面上的小型计算系统。
大型边缘服务器
大型边缘服务器由一个典型的商用非专用服务器组成,其中有两个非统一内存访问(NUMA)节点通过英特尔Ultra Path Interconnect (UPI)或HyperTransport (HT)连接在四个机架空间单元中。除了系统中的两个中央处理单元(CPU)外,最多可以在两个NUMA节点之间分布四个GPU和两个NIC。在这个系统中,GPU和连接到同一外围组件互联(PCI)交换机的NIC之间允许直接数据传输对等直接内存访问(DMA)事务。为了冗余和扩展,两个这样的服务器在集群配置中被使用。这个系统的目标是验证可以实时处理多少个ST 2110 essence流,并且随着GPU或NIC的添加,平台如何扩展。
小型计算平台
小型平台采用基于ARM的系统芯片(SOC),配备单独的独立GPU和NIC,两者并未集成到SOC中。该系统允许直接数据传输对等DMA传输在独立的GPU和NIC之间进行。该系统的架构如图3所示。此服务器耗能更少,可以轻松安装在办公桌面环境中。该系统的目标是了解使用此类系统作为边缘媒体节点设备的可行性,并展示相同软件堆栈适用于不同尺寸的平台。
软件配置
虚拟化
软件平台基于Kubernetes,它可以将硬件资源虚拟化并分配给作为容器部署的应用程序。容器化的应用程序可以小巧轻便,不需要虚拟机(VMs)的操作系统负担。在案例研究中,使用Kubernetes和Helm将应用程序部署到本地边缘平台,但Helm chart也可以用于将应用程序部署到任何云服务提供商(CSP)。
当指定Pod时,可以选择指定每个容器需要的资源量。Pod规格可以指定每个容器的最小需求以及最大限制。最常见的资源是CPU和内存,但Kubernetes可以通过设备插件框架进行扩展,以支持其他硬件资源,如GPU和NIC。Kubernetes中的Operator框架可用于简化所需软件在群集上的初始部署,以及使用标准Kubernetes API和kubectl命令行工具在群集操作期间管理它们。
GPU operator部署适当的容器运行时、容器化的GPU驱动程序和Kubernetes设备插件。Kubernetes中的节点功能发现(NFD)用于检测主机上的硬件设备,并使用节点标签将其特性广告到Kubernetes。
与 GPU operator 类似,network operator 简化了 Kubernetes 的规模化网络设计,通过自动化网络部署和配置的方面,减少了需要手动完成的工作。它在每个需要它们的集群节点上加载适当的驱动程序、库、设备插件和容器网络接口(CNIs)。
媒体处理
在此平台上运行的媒体处理应用程序被打包为容器,它们利用通过 Kubernetes 公开的虚拟化资源,包括 CPU、GPU、内存、网络和存储。这些容器是为多种架构(x86、ARM)构建的,因此它们可以部署在所有受支持的服务器上。
示例应用程序是使用软件组件构建的,这些软件组件在虚拟化 GPU (v GPU) 和虚拟化 NIC (v NIC) 上的表现与在裸机硬件上的表现一样好。
这些软件组件共同支持将低代码 ST 2110 和压缩视频/音频处理构建为容器化应用程序。但是,由于这些组件是作为特定应用程序容器的一部分部署的,因此每个应用程序开发人员都可以自由使用不同的方法。
每个媒体处理应用程序的多个实例可以同时部署,以适应需求的变化。
部署
数据平面
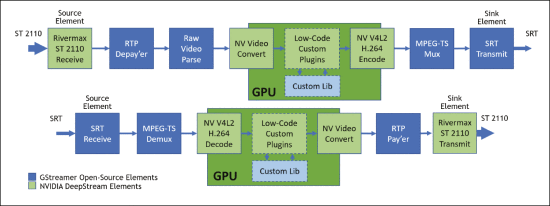
本案例研究的示例容器化媒体处理应用程序实现了在未压缩的ST 2110-2031视频流和经过H.264压缩的安全可靠传输(SRT)32流之间进行基于GPU的转码。
当配置为处理高速网络中的未压缩流时,应用程序使用DeepStream管道,通过Rivermax API将捕获的ST 2110-20帧图像包有效载荷数据放入GPU设备内存。然后,管道使用CUDA和NVENC通过V4L2(Video4Linux 2)直接在GPU上处理这些缓冲区,将压缩帧数据放回到GPU设备内存中。使用开源的GStreamer元素生成MPEG传输流(TS),并通过网络传输SRT流。
当配置为处理来自广域网的压缩流时,应用程序使用DeepStream管道,通过NVDEC和CUDA通过V4L2处理压缩帧。然后使用Rivermax API从GPU设备内存中检索未压缩的数据并构建ST 2110-20传输流,在符合ST 2110-2134时序限制的情况下控制NIC将数据包发送到线上。
在两种情况下,可以轻松地在管道中插入其他插件元素以执行硬件加速视频处理,例如图像缩放、色彩空间处理、用于视频分析和增强的AI推理以及屏幕显示等。DeepStream SDK包括一个模板插件,提供了一个自定义库钩子接口,使得低代码自定义插件元素成为可能。管道体系结构如下图所示。
控制平面
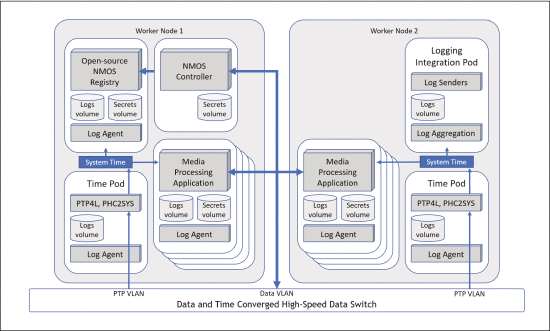
在平台上部署了一个开源、容器化的NMOS注册表,同时还部署了一个第三方NMOS控制器,每个pod都由上面描述的容器化linuxptp应用程序提供PTP同步。
注册表的查询API使NMOS控制器能够发现网络中的发送器和接收器。通过AMWA IS-05连接API从NMOS控制器到媒体处理应用程序的NMOS节点的连接请求会自动处理,并导致应用程序重新配置管道源或汇元素。
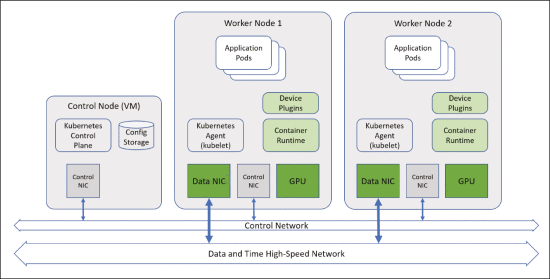
集群架构
为使用大型边缘服务器实现的边缘处理平台,使用两个如之前章节描述的服务器创建了一个双工作节点 Kubernetes 集群,如下图所示。
控制节点使用虚拟机,下图显示了工作节点上部署的应用服务。
与此同时,使用小型服务器实现边缘处理平台时,采用单节点方案。
资源用量
在实现示例媒体处理应用程序的速度极限时,遇到了一些瓶颈。通常情况下,在一个部分消除瓶颈可能会揭示另一个部分的瓶颈。通过在所有系统约束条件之间做出妥协,可以实现最佳的能力/成本。
总结
本案例研究展示了一个实用的媒体处理平台,基于 COTS 硬件和开放软件架构,可以轻松在云边缘执行转码和 AI 处理。本案例研究中使用的两种配置展示了相同的软件堆栈可以轻松部署在大型边缘服务器上,该服务器运行在数据中心中,也可以部署在类似设备的小型设备上,该设备放置在办公室或网络分支机构工作室中,可以进行虚拟化或裸机部署。
在平台上开发的新应用程序使用共享内存和 GPU 直接远程 DMA (RDMA) 优化不同媒体处理 pod 之间的数据传输。NIC 将被数据处理单元 (DPU) 取代,以将 PTP 时间服务从主机 CPU 卸载到 DPU 上的 ARM 核心,并加速其他功能,例如网络遥测和安全服务,使更多的主机 CPU 周期用于媒体处理。39 对 GStreamer 流水线和元素的进一步优化将允许在 GPU 上进行更多处理,并减少 PCIe 数据传输,从而实现最优的系统资源利用率。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
