
本文基于深度视频压缩模型 DCVC 的上下文条件编码框架,在时域和空域中挖掘更加多样化的上下文信息,提出的模型 DCVC-DC 达到了 SOTA 性能。
论文标题:Neural Video Compression with Diverse Contexts
会议:CVPR 2023
作者:Jiahao Li, Bin Li, Yan Lu
论文链接:https://arxiv.org/abs/2302.14402
内容整理:陈予诺
引言
对于任何视频编解码器来说,编码效率高度取决于当前要编码的信号是否能从先前重建的信号中找到相关的上下文。传统编解码器已经证明了:更多的上下文能带来实质性的编码收益。对于新兴的深度视频编解码器 (NVC) 来说,它们所挖掘的上下文信息仍然有限,这导致其压缩性能较低。为了提高 NVC 的性能,本文提出从多个维度增加时域和空域上下文的多样性。首先,我们引导模型学习跨帧的分层质量模式,从而丰富长期且高质量的时域上下文。此外,为了拓展基于光流的编码框架,我们引入了基于组的偏移多样性,提出跨组交互以更好地挖掘上下文。此外,本文还采用基于四叉树的分区,在并行编码潜在表示时增加空间上下文多样性。实验表明,我们的编解码器相对于先前的SOTA NVC 能节省23.5%的比特率。此外,我们的编解码器在 RGB 和 YUV420 颜色空间中的 PSNR 指标都超过了正在开发中的下一代传统编解码器ECM。测试代码已公开:https://github.com/microsoft/DCVC
方法
整体框架
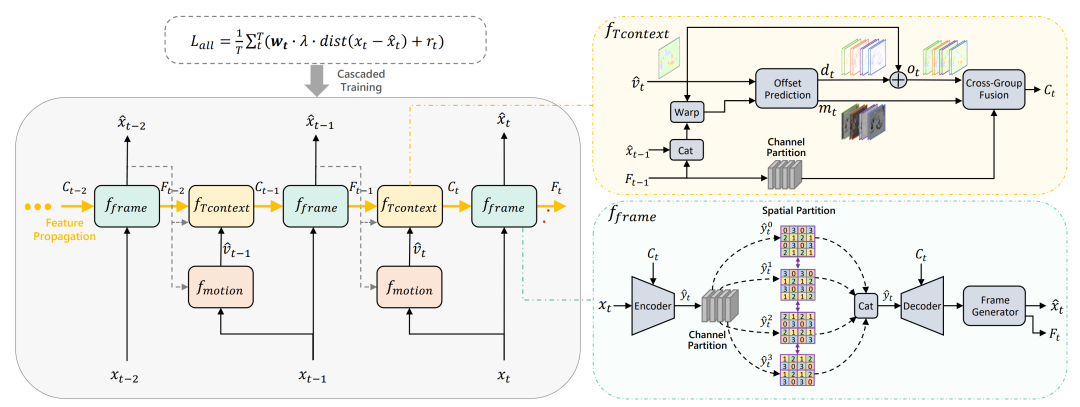
整体流程上,本文模型基于 DCVC 的 运动补偿+条件编码 框架,主要提出了三个改动:
- 用于分层质量级联训练的 Hierarchical Quality Structure,即上图中的灰色区域;
- 用于光流运动补偿增强的 Group-Based Offset Diversity,即上图中的黄色区域;
- 更加有效的熵编码 Quadtree Partition-Based Entropy Coding,即上图中的绿色区域。
Hierarchical Quality Structure
传统编解码器广泛采用分层质量结构,即将帧分配到不同的层级并使用不同的QP(量化参数),这样一方面可以减轻误差的传播和累计,在帧间预测时,高质量的参考帧使编解码器能够在运动估计过程中获得更精确的 MV。另一方面,由于多参考帧选择和加权预测机制的支持,最近的参考帧和远距离高质量参考帧的组合可以使预测更加多样化。
对于 NVC 而言,一个直接的解决方案是在NVC的推理过程中直接分配分层 QP。然而,与传统编解码器使用明确定义的规则执行运动估计和运动补偿(MEMC)不同,NVC通常在特征域中使用神经网络进行运动补偿。这种设计的缺点是对于分布外的质量模式(out-of-distribution quality pattern),其鲁棒性和泛化能力较差。因此,如果直接在测试期间提供分层 QP 给 NVC,它可能无法很好地适应分层质量模式,MEMC也可能表现出次优性能。为此,我们建议在训练期间引导NVC学习分层质量模式。具体而言,我们在失真率损失函数中为每个帧添加权重 wt :
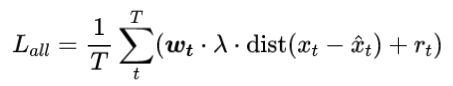
本文在使用 Vimeo-90k 训练的时候,以4帧为一组,分配权重 wt 为 (0.5, 1.2, 0.5, 0.9)。
通过这种分层失真损失,高质量的重建帧 xt 和包含许多高频细节的特征 Ft 会被周期性地生成。它们对于提高MEMC的有效性非常有帮助,缓解了其他 NVC 模型所遇到的错误传播问题。此外,通过跨多帧的级联训练,形成了特征传播链。对后续重建更加重要的高质量上下文会被自动学习并长期保存。因此,对于 xt 的编码,Ft-1 不仅包含从 xt-1 提取的短期上下文,而且还包含了来自前序帧的长期的、持续更新的高质量上下文。这样的 Ft-1 有助于进一步利用多帧之间的时间相关性,从而提高压缩比。
上图展示了 H.266-VTM 17.0 和 DCVC-DC 中的分层质量结构的效果。这个例子来自 HEVC D 数据集中的 BasketballPass 视频。H.266的 bpp 和 PSNR 分别为 0.056 和 35.10,DCVC-DC 的 bpp 和 PSNR 分别是 0.045 和 36.13。
Group-Based Offset Diversity
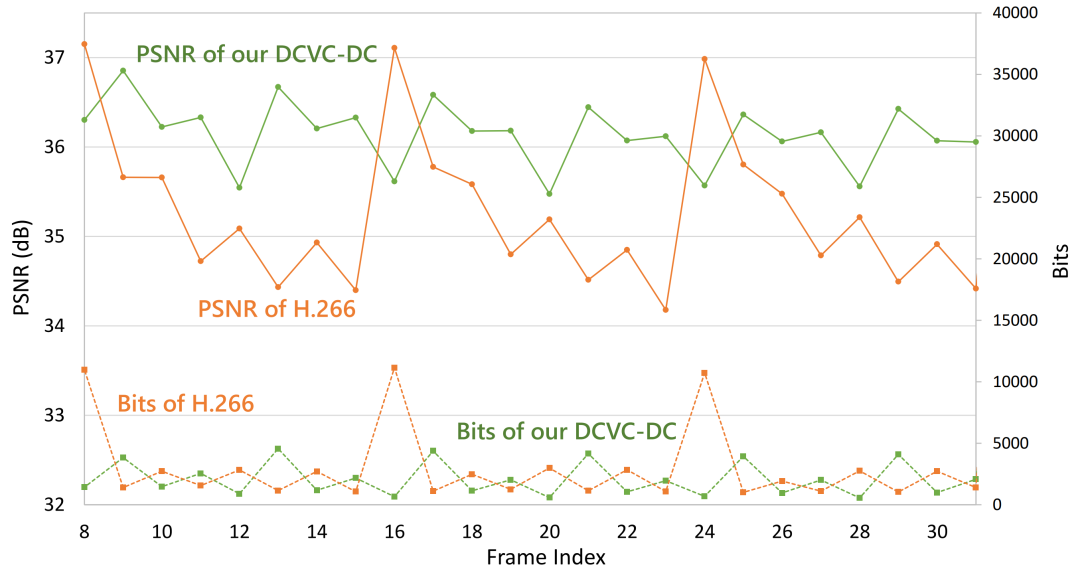
在大多数现有的 NVC 中,运动补偿仅利用单个运动矢量/光流进行 warp。这种基于单个运动的对齐方法对于复杂的运动或遮挡不具有鲁棒性。而在可变形卷积中每个位置都有多个偏移量来捕捉时间对应关系,然而,可变形卷积的训练不稳定,偏移量的溢出也会降低其性能。此外,偏移量的数量受限于可变形卷积核的大小。因此,本文采用了更灵活的设计,称为偏移量多样性 offset diversity。同时,解码的光流被用作基础偏移量,以稳定训练。
如图所示,整个运动补偿由两个核心子模块组成:偏移预测和交叉分组融合。首先,偏移预测使用解码的 MV 来预测残差偏移 dt,其中 xt-1 和 Ft-1 也被 warp 并用作辅助信息,dt 加上基础偏移 MV 成为最终偏移 ot。同时,偏移预测还生成调制掩码 mt,可以看作是反映偏移置信度的注意力权重图。值得注意的是, Ft-1 沿通道维度被分为 G 组,每组有单独的 N 个偏移。因此,总共有 G×N 个偏移可学习。多样的偏移互补,有助于编解码器处理复杂的运动和遮挡。

接下来的融合操作将每 N 个连续的 group 融合成一个群组。因此,在此过程中,group reorder 可以在不增加复杂度的情况下实现更多的跨群组交互。这种设计也享有类似于传统编解码器中不同参考帧的加权预测的好处。通过跨群组融合,引入了更多从不同群组提取时间上下文的多样组合,并进一步提高了偏移多样性的有效性。
Quadtree Partition-Based Entropy Coding
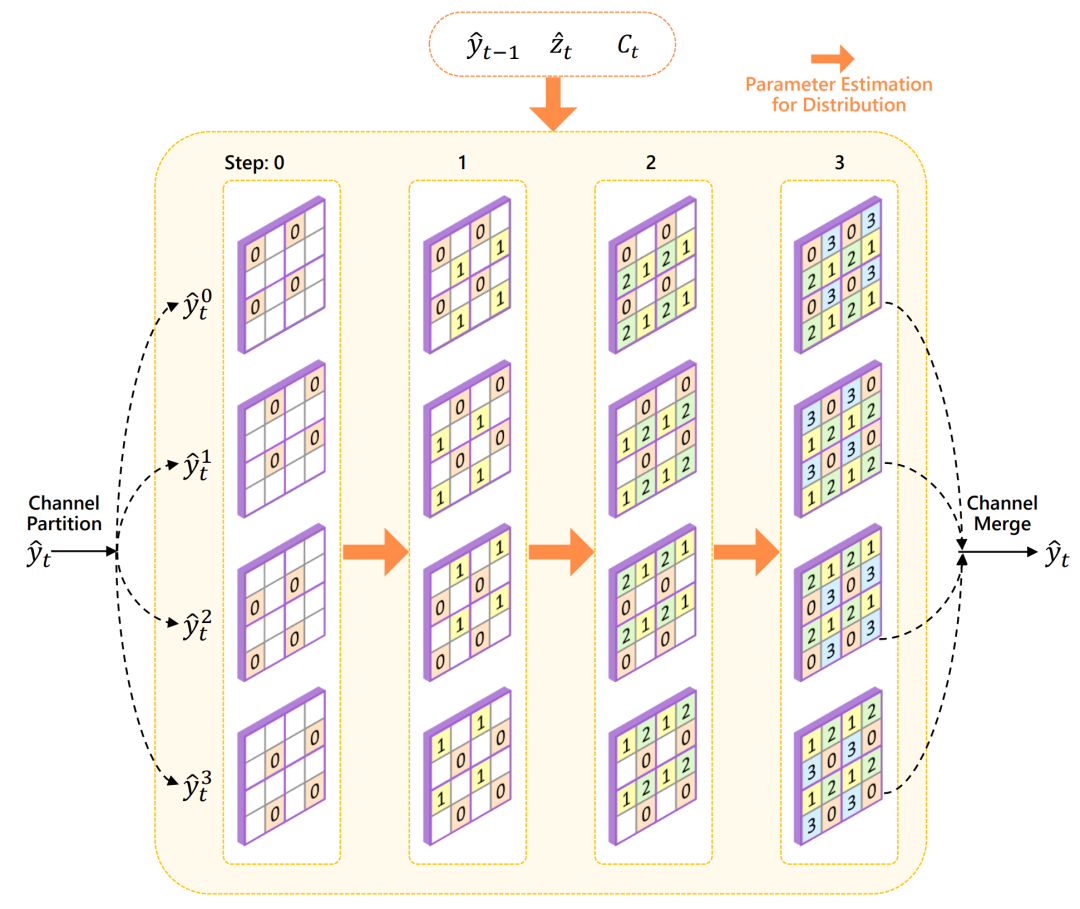
许多深度编解码器采用自回归模型作为熵模型,然而它会严重降低编码速度。相比之下,棋盘模型提出先编码 yt 的偶数位置,然后并行地使用它们来预测奇数位置的PMF。最近的双空间模型利用通道维度上的相关性对其进行了改进。然而,棋盘模型中用于熵建模的参考点位仍然比较有限。因此,本文提出了一种更精细的编码方式,通过四叉树分区利用多样的空间上下文来改进熵建模。
如图所示,我们首先沿着通道维度将 yt 分成四个组。然后,每个组在空间维度上被划分为不重叠的2×2块。整个熵编码分为四个步骤,每个步骤对应上图中相应索引的不同位置进行编码。在第0步,所有块的所有索引为0的位置同时进行编码。需要注意的是,对于四个组,索引为0的位置彼此不同。因此,对于每个空间位置,有四分之一的通道(即一个组)进行编码。在随后的第1、2和3步中,所有在先前步骤中编码的位置都被用于预测当前步骤中编码的位置的PMF,并且在每个步骤中不同的组会在不同的空间位置进行编码。
实验
RGB 空间性能
PSNR 性能
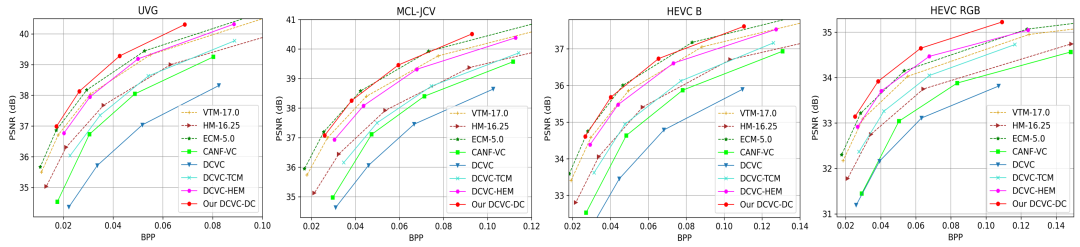
本文使用 BT.709 将颜色转换 RGB 域,上图展示了RD曲线对比。从曲线中可以看到, DCVC-DC 在较宽的比特率范围内实现了 SOTA 性能。
以下表格数据都使用 VTM-17.0 作为 anchor。
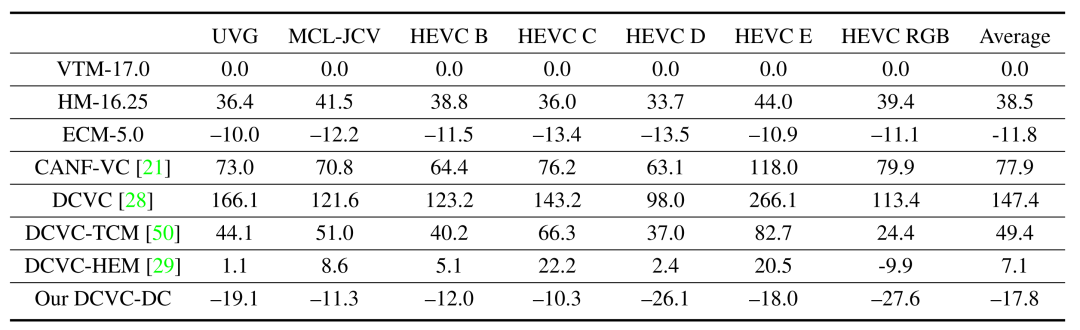
由下表可见,DCVC-DC 的性能优于 ECM。如果使用 ECM 作为 anchor,则平均可节省 6.4% 的比特率。
MS-SSIM 性能
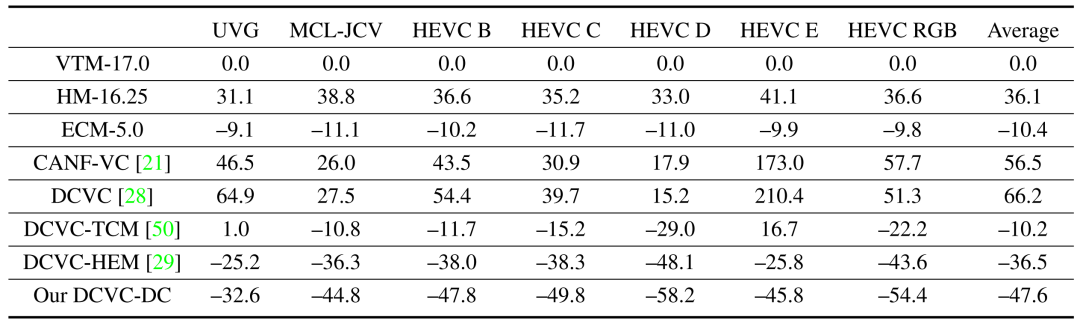
当使用 MS-SSIM 作为质量指标时,DCVC-DC 显示出更大的提升。如下表所示,DCVC-DC 比 VTM 平均节省 47.6% 的比特率。相比之下,ECM 相对于 VTM 的 码率节省仅为 10.4%。
YUV 空间性能
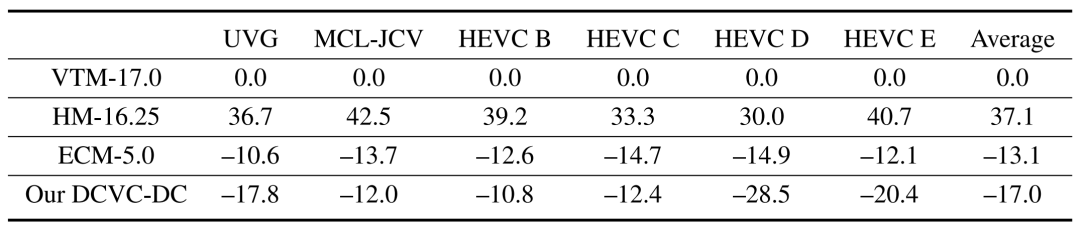
传统编解码器主要是在 YUV420 上进行优化的,因此在 YUV420 上的比较对于评估 NVC 相对传统编解码器的进展也非常重要。如上表所示,该表中的PSNR 数值是使用YUV的三个分量的加权计算的,权重是(6,1,1)/8。由于大多数 NVC 方案没有发布针对YUV420的模型,因此上表仅报告了DCVC-DC的数据。
DCVC-DC相对于VTM平均可节约17.0%的码率。仅考虑Y分量时,相对于VTM平均可实现15.3%的码率节约。平均而言,DCVC-DC 在 YUV420 方面同样优于ECM。
值得注意的是,DCVC-DC 对于 RGB 和 YUV420 颜色空间使用了相同的网络结构,仅在训练期间进行不同的微调。这显示了 DCVC-DC 在针对不同颜色空间的输入进行优化方面的简单性和强大的可扩展性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
