
本文提出了 FloRen,一种用于实时、高分辨率自由视角人体合成的新型系统。在FloRen中,首先恢复粗略级别的隐式几何作为初始化,然后通过基于外观流的神经渲染框架进行处理。基于外观流的渲染框架由三个步骤组成,即视图相关的深度细化、外观流估计和遮挡感知的颜色渲染。通过这种方式,FloRen解决了图像平面中的视图合成问题,在图像平面中,2D卷积神经网络可以有效地应用,有助于提高高速性能。对于鲁棒的外观流估计,明确地将数据驱动的人体先验知识与多视图几何约束相结合。精确的外观流能够实现从输入视图到新视图的精确颜色映射,极大地促进了高分辨率新视图的生成。
文章来源:SIGGRAPH Asia 2022
论文链接:FloRen: Real-time High-quality Human Performance Rendering via Appearance Flow Using Sparse RGB Cameras (acm.org)
作者:Ruizhi Shao, Liliang Chen等
内容整理:王睿妍
引入
新视图合成是计算机图形学和计算机视觉中的一个基本问题,它为视觉体验开辟了一条新的途径。随着元宇宙的迅速传播,这个领域从未像今天这样受到关注。人类自由视点渲染作为其子领域之一,被认为是元宇宙中许多交互应用的基本技术,如全息通信和沉浸式社交。
现有的新视图合成方法大致可以分为两类:一类侧重于基于图像的渲染,另一类更注重几何建模。基于图像的渲染方法通过直接复制输入图像中的像素来渲染新颖的视图。如果没有场景几何的先验知识,可用的基于图像的渲染技术需要对视图进行密集采样,并且无法在稀疏的视点设置下生成逼真的渲染。与基于图像的渲染技术不同,基于几何的方法侧重于使用纹理图显式 3D 几何模型重建,以使用传统的图形管道渲染新的视点。为了获得高质量的纹理映射,他们必须计算精确的场景几何模型,这通常是一个耗时的过程,并且依赖于复杂的密集摄像设备、主动照明或复杂的深度传感和融合。只考虑稀疏视图 RGB 相机,这些方法会出现几何重建误差,这些误差会立即反映在合成图像上。
在过去几年神经场景表示的快速发展的推动下,构建更轻量级的系统来实现人类表现的即时自由视图渲染已经成为可能。关键是利用人体的数据驱动先验进行稀疏视图三维形状推理。在基于几何的方法方面,PIFu及其后续工作能够以占有场的形式实现高效的 3D 人体重建。一旦提取出来,重建的模型就可以立即呈现在新颖的视图中。另一方面,神经辐射场(Neural Radiance Fields)的首次亮相激励研究人员提出了许多新的人体自由视图渲染技术,两种工作都对空间进行密集采样,以构建用于形状推理的 3D 占用/密度场。这样的框架需要很高的计算成本,这限制了实时系统中可能的操作分辨率。此外,操作分辨率的降低导致表面定位精度的直接损失和渲染质量的退化。因此很难使用这些神经场景表示同时实现实时性能和高质量渲染。
贡献
- 一种结合数据驱动先验和极线约束的平稳外观流量估计方法,显著提高了高分辨率实时绘制的速度。
- 统一的网络架构设计,以端到端的方式结合了 DepthNet 、 FlowNet 和 ColorNet,为高分辨率 RGB 输入带来高效的几何细化和颜色渲染。
- 一种新的系统,结合了粗略级别的隐式几何重建和高效的基于 CNN 的视图相关渲染,仅使用稀疏 RGB 相机即可实时实现高质量的新视图合成。
实现方法
作者认为 360° 渲染不必完全在 3D 场中实现,依据《 Post-rendering 3D warping 》中表明的,改变 3D 对象的渲染视点相当于沿着一些特定的极线移动像素。因此,如果可以掌握描述像素如何移动的“外观流”,即从源视图到目标视图的对应关系,则不再需要3D场重建,并且可以在 2D 图像平面中高效地进行自由视图渲染。FloRen 采用高质量的外观流估计,而不是高分辨率 3D 几何体,因为通过 3D 空间中的密集采样点直接重建高分辨率人体模型需要耗费大量内存和时间。基于流的渲染方法利用了每个单独图像中的几何线索和相邻视图之间的立体约束,实现了高质量的自由视图渲染,并且可以在 2D 域中高效执行。
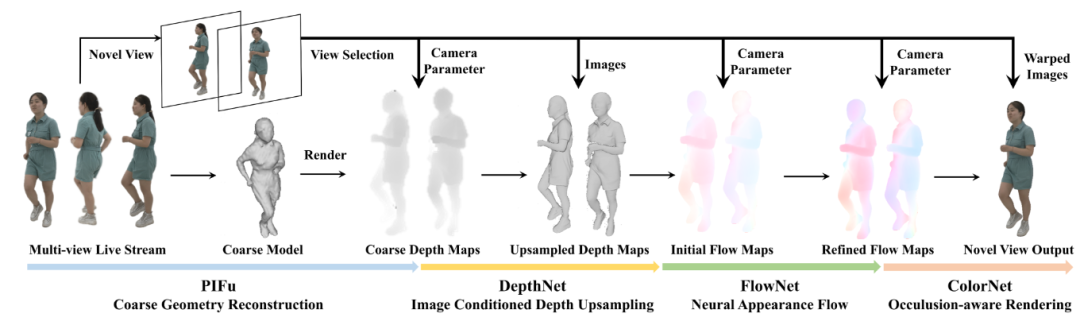
如上图 Pipeline 所示,针对稀疏视图 RGB 图像的实时流,系统首先在低分辨率下重构粗糙几何模型。然后将粗模型渲染为粗深度图,由 DepthNet 进行上采样和细化。在此之后,将细化的深度图转换为表示外观流的流图进行视图插值。这些流图由 FlowNet 进行细化,然后由 ColorNet 根据细化的外观流对输入图像进行变形扭曲后生成最终渲染。
粗略几何初始化
基于 N 个 RGB 图像 Ⅰ1,…,ⅠN 从稀疏视图,首先采用多视图 PIFu 来预测低分辨率粗略 SDF 体积()。首先需要低分辨率的 SDF 体素将输入图像降采样到分辨率 128𝑥128,同时通过使用一个 hourglass 堆栈并将特征通道的基数减少到 16,来减少 PIFu 中 Hourglass network 的参数。FloRen 还从多视图分割 Mask 中构建视觉外壳,以排除人类之外的点,并采用 PIFu 来仅预测剩余点的 SDF 值。在获得粗略的几何体后执行视图选择并渲染粗略的深度贴图。
视图选择

粗略深度图生成

基于图像条件的深度贴图上采样
为了获得视图合成所需的几何信息,作者直接使用卷积神经网络 DepthNet 来预测高分辨率深度图 Ch 而不是密集地预测 3D 空间中的SDF/占用值。这种策略更适合高分辨率需求,并显著降低了时间和内存成本。具体而言,给定两个选定视图的粗略深度图和高分辨率RGB图像,首先将粗略深度图上采样到与 RGB 图像相同的分辨率。然后采用 DepthNet 𝑓𝐷 以预测具有图像条件的上采样深度图:
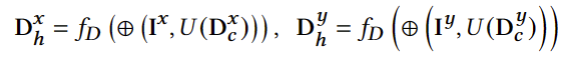
其中,𝑈 是上采样操作。DepthNet 减少了很多时间成本,因为它以前馈的方式预测整个深度图,只需一次推理。通过多视图重建获得的粗略深度图解决了深度模糊性,并且高分辨率图像条件提高了上采样深度图的质量。在预测所选视图的上采样深度图之后,通过一种快速而直接的策略计算新视角的深度图
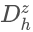
神经外观流

FloRen 还在流量估计中加入了立体约束,以更好地保持不同视点之间的一致性。具体地说可以约束每个像素位置在其极线上的流动。通过采样极线上的两个点并计算它们之间的差来获得从所选视图到新视图的核线方向。由于已经对极线上的一个点进行了采样,即F(i,j)+o,因此通过向深度贴图添加固定的平移并使用摄影机参数对其进行变换来对另一个点进行采样:

遮挡感知色彩渲染
ColorNet 是一个 2D 卷积网络,可以有效地融合两个选定视图的变形图像。首先将新视图的深度图转换为世界坐标,并将每个点投影到两个选定的视图。然后将所选视图的上采样深度图上投影点的 Z 值与其对应的深度值进行比较。假设一个点被遮挡,如果它 𝑍 值大于其深度值。对于新视图中的每个位置都设置了一个软遮挡阈值𝛼 并如下计算遮挡遮罩:
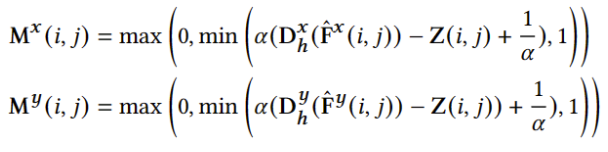
然后将变形的图像和遮挡遮罩输入到 ColorNet 中𝑓𝐶 渲染新颖视图的最终图像I𝑧。
实验
实验模型是根据合成数据训练的。从 Twindom 数据集中收集了 1700 次人体扫描,并将其随机分为 1500 次扫描的训练集和 200 次扫描的测试集。对于每次扫描,渲染大小为 1024×1024 的高分辨率图像和深度图。使用 Twindom 测试集,从公共数据集 THuman2.0 中随机选择 100 次扫描进行评估,作者还从商业数据集 RenderPeople 中选择了一些扫描进行可视化。
损失函数
DepthNet
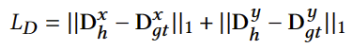
FlowNet
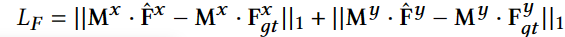
ColorNet
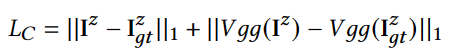
定量结果
下图是外观渲染和运行速度的定量结果。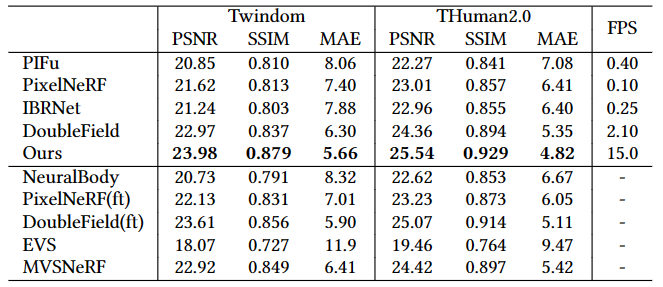
下图是流估算的定量结果。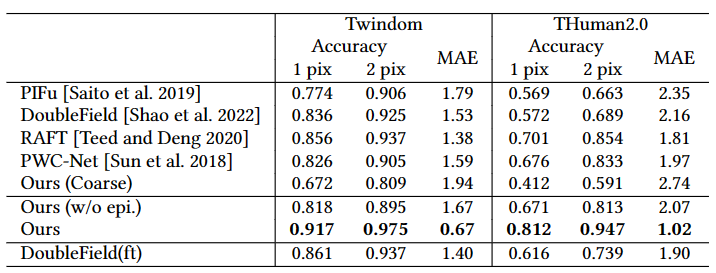
定性结果
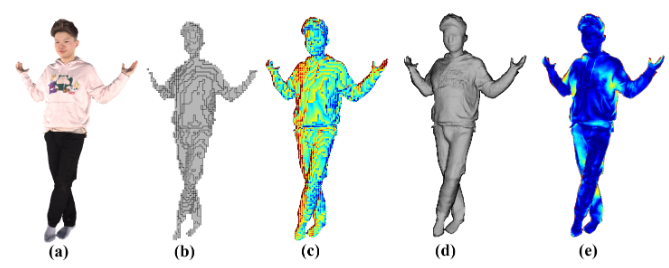
下图是 FloRen 与 PIFu、PixelNeRF 和 DoubleField 等最先进的方法相比,FloRen可以合成具有更清晰细节的新颖视图。

限制
尽管 FlowNet 可以在一定程度上纠正立体校准的误差,但希望多摄像机校准尽可能准确,以获得最佳性能。由于流估计假设了漫反射的人体表面和均匀的照明,因此方法中视景相关的效果也受到限制。此外仍然需要精确的人体前景 mask 来进行重建和渲染。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
