
文本引导的生成扩散模型解锁了强大的图像创建和编辑工具。虽然这些已经扩展到视频生成,但当前编辑现有素材内容同时保留结构的方法需要对每个输入进行昂贵的重新训练,或者依赖于跨帧图像编辑的容易出错的传播。论文提出了一种结构和内容引导的视频传播模型,该模型根据所需输出的视觉或文本描述来编辑视频。用户提供的内容编辑和结构表示之间的冲突是由于这两个方面之间的分离不够充分。作为解决方案,论文展示了对具有不同细节级别的单眼深度估计的训练可以控制结构和内容保真度。论文的模型是在图像和视频上联合训练的,这也通过一种新颖的指导方法公开了对时间一致性的明确控制。我们的实验证明了各种各样的成功;对输出特征的细粒度控制,基于一些参考图像的定制,以及用户对模型结果的强烈偏好。
来源:arxiv 2023
题目:Structure and Content-Guided Video Synthesis with Diffusion Models
作者:Patrick Esser 、Johnathan Chiu 、Parmida Atighehchian、Jonathan Granskog 、Anastasis Germanidis、 Runway等人
链接:https://arxiv.org/pdf/2302.03011.pdf
内容整理:胡玥麟
简介
视觉效果和视频编辑在现代媒体领域无处不在。因此,随着以视频为中心的平台的普及,对更直观、更高效的视频编辑工具的需求也在增加。然而,由于视频数据的时间特性,以这种格式进行编辑仍然是复杂且耗时的。最先进的机器学习模型在改进编辑过程方面显示出巨大的希望,但方法通常需要在时间一致性与空间细节之间取得平衡。
由于引入了在大规模数据集上训练的强大扩散模型,用于图像合成的生成方法最近在质量和流行度上迅速飙升。文本条件模型,例如 DALL-E 2 和 Stable Diffusion,使新手用户能够仅在输入文本提示的情况下生成详细的图像。
潜在扩散模型特别提供了在感知压缩空间中通过合成生成图像的有效方法。
受扩散模型在图像合成方面的进展启发,论文作者研究了适合视频编辑中交互式应用的生成模型。他们的目标是规避昂贵的每个视频训练和对应计算,以实现对任意视频的快速推理。
论文提出了一种可控结构和内容感知视频扩散模型,该模型在无字幕视频和成对文本图像数据的大规模数据集上进行训练。作者选择用单眼深度估计来表示结构,并用预训练神经网络预测的嵌入表示内容。
论文的方法在其生成过程中提供了几种强大的控制模式。首先,类似于图像合成模型,作者训练模型使得推断视频的内容,例如外观或风格,匹配用户提供的图像或文本提示。其次,受扩散过程的启发,作者将信息模糊过程应用于结构表示,以便能够选择模型对给定结构的坚持程度。最后,作者还通过受无分类器指导启发的自定义指导方法调整推理过程,以控制生成的剪辑中的时间一致性。
总之,论文贡献如下:
• 通过将时间层引入预训练图像模型并联合训练图像和视频,将潜在扩散模型扩展到视频生成。
• 提出了一种结构和内容感知模型,可以修改由示例图像或文本引导的视频。编辑完全在推理时执行,无需额外的每个视频训练或预处理。
• 展示了对时间、内容和结构一致性的完全控制。首次表明,对图像和视频数据的联合训练可以实现对时间一致性的推理时间控制。为了结构的一致性,对表示中不同细节级别的训练允许在推理过程中选择所需的设置。
• 表明我们的方法在用户研究中优于其他几种方法。
• 展示了经过训练的模型可以进一步定制,以通过微调一小组图像来生成更准确的特定主题视频。
相关工作
可控视频编辑和媒体合成是一个活跃的研究领域。在这一部分,我们回顾了相关领域的先前工作,并将论文方法与这些方法联系起来。
无条件视频生成的生成对抗网络(GAN)以学习根据特定训练数据合成视频。这些方法在优化过程中经常与稳定性作斗争,并产生固定长度的视频或更长的视频,其中伪像会随着时间的推移而累积。某些研究使用自定义位置编码和利用编码的对抗训练模型以高细节合成更长的视频,但训练仍然仅限于小规模数据集。还有针对无条件视频生成的自回归变换器。然而,论文的重点是为用户提供对合成过程的控制,而这些方法仅限于对类似于其训练分布的随机内容进行采样。
用于图像合成的扩散模型(DM)最近引起了研究人员和艺术家的关注,由于能够合成详细的图像,并且现在正被应用于内容创作的其他领域,例如运动合成和3D形状生成。
其他作品通过改变参数化、引入高级采样方法、设计更强大的架构或以附加信息为条件。基于来自CLIP或T5的嵌入的文本调节已经成为一种特别强大的方法,可以对模型输出进行艺术控制。潜在扩散模型(LDM)在压缩的潜在空间中执行扩散,减少内存需求和运行时间。论文通过在架构中引入时间连接并通过对视频和图像数据进行联合训练,将LDM扩展到时空域。
用于视频合成的扩散模型最近已应用于文本条件视频合成。与某些研究类似,论文通过将时间连接引入预先存在的图像模型,将图像合成扩散模型扩展到视频生成。然而,论文的目标不是从头开始合成视频,包括它们的结构和动态,而是提供对现有视频的编辑能力。虽然扩散模型的推理过程可以在某种程度上进行编辑,但论文证明在结构上具有显式条件的模型更受欢迎。
视频翻译和传播的图像到图像翻译模型,例如pix2pix,可以处理视频中的每个单独的帧,但由于模型缺乏对时间邻域的认识,可以处理视频中的每个单独的帧,但是由于模型缺乏对时间邻域的认识,这会在帧之间产生不一致。在重新利用图像合成模型时,考虑视频中的时间或几何信息(例如流)可以提高帧间的一致性。
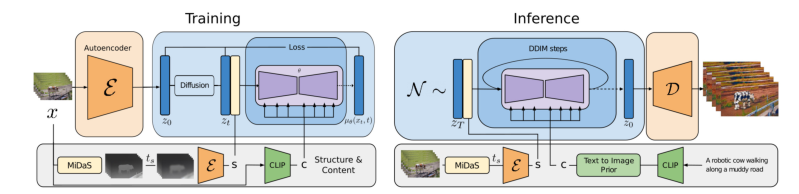
如上图所示,E 编码为 z0 并扩散到 zt。论文通过对使用 MiDaS 获得的深度图进行编码来提取结构表示 s,并通过使用 CLIP 对其中一个帧进行编码来提取内容表示 c。然后,在 s 和 zt 以及通过交叉注意块提供的 c 的帮助下,模型学习反转潜在空间中的扩散过程。在推理过程中(右),输入视频的结构 s 以相同的方式提供。为了通过文本指定内容,论文通过先验将 CLIP 文本嵌入转换为图像嵌入。
视频风格迁移的方法采用参考风格图像,并将其风格统计应用于输入视频。相比之下,论文的方法在受提取的结构数据约束的同时,应用了来自输入文本提示或图像的样式和内容的混合。通过从数据中学习生成模型,论文的方法产生语义一致的输出,而不是仅匹配特征统计。Text2Live允许通过将视频分解为神经层,使用文本提示编辑输入视频。
一旦可用,分层视频表示将提供跨帧的一致传播。SinFusion可以通过优化单个视频的扩散模型来生成视频的变化和外推。同样,Tunea-Video在单个视频上微调转换为视频生成的图像模型以启用编辑。然而,昂贵的每个视频训练限制了这些方法在创意工具中的实用性。因此,论文选择在大规模数据集上进行训练。
论文方法
对于论文的目的而言,从内容和结构的角度来考虑视频会很有帮助。通过结构,论文指的是描述其几何和动力学的特征,例如对象的形状和位置以及它们的时间变化。论文将内容定义为描述视频外观和语义的特征,例如对象的颜色和样式以及场景的照明。论文模型的目标是在保留其结构的同时编辑视频的内容。
为实现这一目标,论文的目标是学习视频的生成模型,以结构表示为条件,用内容表示。论文从输入视频中推断形状表示,并根据描述编辑的文本提示对其进行修改。首先,论文将生成模型的实现描述为条件潜在视频扩散模型,然后描述论文对形状和内容表示的选择。最后,论文讨论了模型的优化过程。
潜在扩散模型
扩散模型学习逆转一个固定的前向扩散过程,它被定义为:


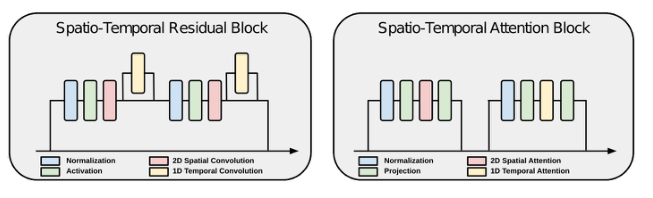
上图展示了论文所用到的时间扩展:通过在其构建块中添加时间层,将基于图像的 UNet 架构扩展到视频。我们在其残差块(左)中的每个 2D 空间卷积之后添加一个 1D 时间卷积,并在其每个 2D 空间注意块(右)之后添加一个 1D 时间注意块
Temporal Control 时间控制

时间控制:通过联合训练图像和视频模型,我们通过时间指导尺度 ωt获得对编辑视频的时间一致性的明确控制。在左侧,通过连续帧的 CLIP 余弦相似性测量的帧一致性随 ωt 单调增加,而随光流扭曲的帧之间的均方误差单调减少。在右边,较低的比例(中间行中的 0.5)实现了具有“手绘”外观的编辑,而较高的比例(底行中的 1.5)导致更平滑的结果。顶行显示原始输入视频,两个编辑使用提示“一个人看着相机的铅笔素描”。

其方法支持范围广泛的视频编辑,包括改变动画风格(例如动漫或粘土动画)、改变环境(例如时间或季节)以及将角色(例如人类变为外星人或将场景从自然界移至外太空)。
优化过程
论文的模型在一个包含240M图像的内部数据集和640万视频剪辑的自定义数据集上进行训练。作者使用了大小为9216的图像批次,分辨率为320×320、384×320和448×256,以及具有翻转纵横比的相同分辨率。图像批次以12.5%的概率进行采样。对于主要训练,他们使用包含8帧的视频批次,采样间隔为4帧,分辨率为448×256,总视频批次大小为1152。
作者分多个阶段训练他们的模型。首先,基于预训练的文本条件潜在扩散模型初始化模型权重。他们将条件从CLIP文本嵌入更改为CLIP图像嵌入,并仅对图像进行15k步微调。之后,他们引入了第一节中描述的时间连接,并在图像和视频上联合训练75k步。然后,他们在固定的结构s上添加条件,并训练25k步。最后,恢复训练,其中结构参数在0到7之间均匀采样,再进行10k步。
性能测试
为了评估上述的方法,论文使用来自 DA VIS的视频和各种素材。为了自动创建编辑提示,我们首先运行字幕模型 以获得原始视频内容的描述。然后使用 GPT-3 生成编辑提示。
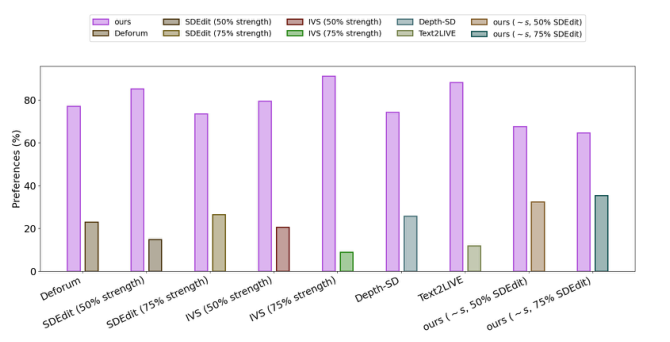
用户偏好:根据用户研究,论文模型的结果优于基线模型。
结论
论文中的潜在视频传播模型在给定结构和内容信息的情况下合成新视频。通过以深度估计为条件来确保结构一致性,同时内容由图像或自然语言控制。通过模型中的额外时间连接以及联合图像和视频训练,可以获得时间稳定的结果。此外,一种受无分类器指导启发的新型指导方法允许用户控制输出的时间一致性。通过对具有不同保真度的深度图进行训练,论文展示了调整结构保留级别的能力,这被证明对模型定制特别有用。定量评估和用户研究表明,论文的方法优于相关方法。未来的工作可以调查其他调节数据,例如面部标志和姿势估计,以及额外的 3D 先验以提高生成结果的稳定性。作者们不打算将该模型用于有害目的,但意识到其中的风险,并希望进一步的工作旨在打击对生成模型的滥用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
