
近日,CVPR NTIRE 2023 Quality Assessment of Video Enhancement Challenge比赛结果公布,来自大淘宝音视频技术团队的同学组成「TB-VQA」队伍,从37支队伍中脱颖而出,拿下该比赛(唯一赛道)冠军。此次夺冠是团队继MSU 2020和2021世界编码器比赛、CVPR NTIRE 2022压缩视频超分与增强比赛夺魁后,再次在音视频核心技术的权威比赛中折桂。
赛事介绍
CVPR NTIRE (New Trends in Image Restoration and Enhancement workshop and challenges on image and video processing) 是近年来图像和视频增强处理领域最具影响力的全球性赛事。今年(2023)的赛事包括Quality Assessment of Video Enhancement Challenge(视频质量评价,VQA)、real-time image super-resolution、image shadow removal、video colorization、image denoising等,覆盖许多图像和视频增强处理的经典任务。
由上述竞赛不难看出,视频增强处理已经在学术界大量研究并在工业界得到广泛应用。随着互联网视频化的深入,越来越多的UGC(user generated content)等非传统广电视频(包括但不限于短视频、直播等)在互联网平台上被生产或播放,并大都经过增强处理。自然地,如何有效地衡量增强处理后的视频质量就成为一项重要且紧迫的任务。
因此,VQA竞赛应运而生,并由NTIRE于今年首次举办。主办方构建了包含1,211个真实应用场景的视频的数据集 ,对其进行包括色彩、亮度、和对比度增强、去抖动、去模糊等增强处理,并对处理后的视频进行打分作为GT(ground truth)。参赛者设计方案对上述视频进行打分,与GT更为接近(使用相关性作为衡量指标,包括SRCC和 PLCC,是业界最常用的指标,更高的SRCC和PLCC表示与GT拟合程度更高)的参赛者名次更好。本次竞赛由苏黎世联邦理工学院计算机视觉实验室主办,仅有唯一赛道——无参考视频质量评价,云集了国内外几十只参赛队伍,包括字节、快手、网易、小米、Shopee等知名科技企业,北京航空航天大学、新加坡南洋理工大学等高校均有参赛。
经过激烈的角逐,大淘宝音视频技术的参赛队伍「TB-VQA」在唯一赛道夺冠,在Main Score、SRCC、和PLCC三项指标均胜出。
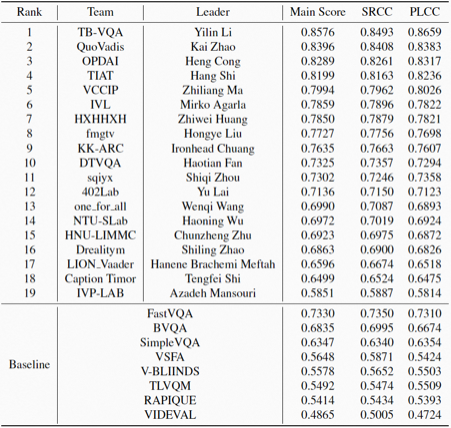
表1. CVPR NTIRE 2023 VQA比赛排行榜
值得一提的是,本次比赛的冠军是大淘宝音视频技术团队继MSU 2020和2021世界编码器比赛、CVPR NTIRE 2022压缩视频超分与增强比赛夺魁后,再次在音视频核心技术的权威比赛中取得佳绩。团队在视频编码、视频增强处理、视频质量评价、以及视频传输等视频核心技术领域均有布局,一些技术突破发表在CVPR、ICCV等计算机视觉和视频领域的顶级会议,在上述比赛取得出色成绩,也是团队长期以来持续投入和不断创新的阶段性成果。
在视频编码方面,MSU(莫斯科国立大学)世界视频编码器大赛是视频编码领域最权威的全球性顶级赛事,迄今已由MSU的Graphics & Media Lab连续举办了二十三届,其评测报告被业界广泛认可,吸引了包括Google、Netflix、Intel、Nvidia、腾讯、字节、华为等国内外知名科技企业参与,代表了行业发展的风向标。大淘宝音视频技术团队自研的奇点编码器S265和S266,相比业界流行的开源编码器x265、VVEnC等,在编码速度、编码质量、和编码延时等多方面均有明显突破,并联合阿里云视频云团队参加了MSU 2020和2021连续两届比赛,取得多个赛道第一。S265已经全面应用于包括淘宝直播、逛逛、首页信息流在内的大淘宝内容业务,经过奇点编码器压缩后,普通手机在3G网络也可顺滑播放720p的高画质,最新发布的手机甚至可支持4k 30FPS超高清直播。
在视频增强处理方面,CVPR NTIRE 压缩视频超分与增强比赛自2020年起已举办三届,在工业界和学术界均产生了重大的影响,吸引了包括腾讯、字节、华为等知名科技企业,中科院、北大、港中文、ETH等科研机构参赛,其中很多参赛者都是连续参赛,竞争激烈。CVPR NTIRE 2022压缩视频超分与增强比赛包含三个赛道,分别是:
- 赛道1:针对视频编码的高压缩比带来的失真的视频恢复问题;
- 赛道2:在赛道1的基础上,同时处理高压缩和2倍超分问题。;
- 赛道3:在赛道2的基础上,进一步探索4倍超分问题。
其中,Track1和Track2的问题已经在工业界得到广泛应用,将视频还原到理想视频的画质能够大幅提升人眼感官,吸引人们的观看意愿。经过激烈的角逐,大淘宝音视频技术团队自研的视频超分方法TaoMC2,取得了三个赛道两冠一亚(赛道3亚军)的成绩。相关视频增强技术目前已广泛应用于点淘、逛逛在内的所有大淘宝内容业务,支持直播、短视频的实时和非实时转码过程中的画质增强;相关超分辨率技术也广泛用于诸如弱网等场景下的低分辨率视频传输、保障低传输带宽下的高分辨率的用户播放画质体验。后文分享我们的具体的方案——
参考方案
视频质量评价按照对参考视频可用性一般可以分成三类:全参考视频质量评价、部分参考视频质量评价、和无参考视频质量评价 [1]。由于视频增强场景不存在完美的参考视频,因此更适合采用无参考视频质量评价方法。无参考视频质量评价作为质量评价的主要研究方向之一,在过去的几年里得到了广泛的关注。主流方法有:基于图像识别 [2] 或者图像质量评价 [3] 任务的预训练模型来提取视频的帧级特征、考虑时序上的相关性回归特征或者进一步结合时域特征 [4] 、以及针对视频失真进行端到端的特征表征学习 [5] 等。
我们提出的方法基于 [5] ,并且考虑到近年来Swin Transformer在CV领域取得巨大成功,使用Swin Transformer V2替换较为传统的卷积神经网络(CNN)骨干网络ResNet提取空域特征。同时,为了更好融合时空域特征,在时空特征融合模块中,我们引入了一个 1×1 卷积层,它加深了从预训练网络的中间阶段提取的空间特征,以弥补浅层和深层特征之间的差距。此外,为了解决常见的质量评价数据集规模过小、大模型容易过拟合的问题,我们同时在空域和时域两个维度进行数据增强,提高模型性能。
模型设计
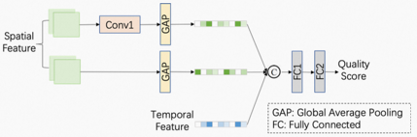
图1示出了所提出的无参考视频质量评价模型的框架,包括空域特征提取模块、时域特征提取模块、和时空特征融合回归模块。具体来说,空域特征模块提取空间失真相关特征,时域特征提取模块提取运动相关信息,并且,考虑到运动信息对失真感知的影响,我们进一步融合时空域特征,然后通过特征回归映射到最终的质量分数。
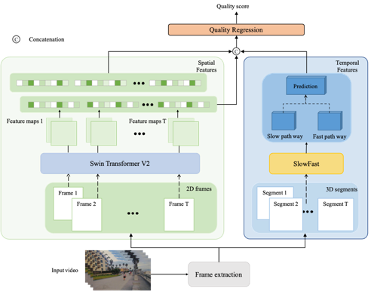
图1. VQA模型的网络架构示例。
- 空域特征提取
语义特征作为重要的空域特征经常用于质量评价,其描述图像中物体的物理特性、物体之间的时空关系、以及物体的内容信息等,属于图像的高维特征。对于不同的图像内容,语义特征会影响人眼的视觉感知:人眼通常无法容忍纹理丰富的内容(例如草坪、地毯)的模糊,而对纹理简单的内容(例如天空、墙面)的模糊相对不敏感。综上考虑,我们利用从预训练的Swin Transformer V2 [3] 网络倒数第二层Transformer模块输出的特征作为帧级的空间域特征,如图2公式所示:

图2. 语义特征。
其中,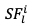 表示从第
表示从第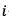 个视频片段的第
个视频片段的第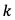 帧获取的语义特征,
帧获取的语义特征,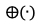 表示级联算子,
表示级联算子,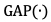 表示全局平均池化算子,
表示全局平均池化算子,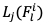 表示Swin Transformer V2最后第
表示Swin Transformer V2最后第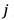 层的特征图。
层的特征图。
- 时域特征提取
手机拍摄时的抖动会导致视频发生时域失真,并且,其无法被视频空域特征有效地描述。因此,为了提高模型的准确度,我们利用预训练的SlowFast网络[7] 获取视频片段级的运动特征,作为时域特征表征,如图3公式所示:
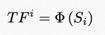
图3. 时域特征。
其中,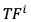 表示从第
表示从第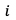 个视频片段获取的运动特征,
个视频片段获取的运动特征,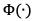 表示运动特征提取算子。
表示运动特征提取算子。
- 时空域特征融合与回归
由于不同层空域特征之间存在较大的差异,对其进行直接拼接不利于时空特征融合,因此我们先对倒数第二层输出特征进行卷积处理,然后再与最后一层输出空间特征融合以及空域特征进行融合,并通过两层全连接层回归得到视频片段级质量分数,如图4所示:
此外,我们使用时间上的平均池化来聚合视频片段质量分数作为整个视频质量分数,如图5公式所示:
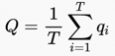
其中,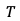 表示视频分段的数目,
表示视频分段的数目,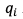 表示视频片段级分数,完整视频的质量
表示视频片段级分数,完整视频的质量 可通过对视频片段打分进行平均池化操作获得。
可通过对视频片段打分进行平均池化操作获得。
数据增强与训练
本次比赛官方提供的训练数据集有839个视频,不足以训练基于Transformer的模型。因此,我们从两个数据集增强策略和大型数据集预训练两种方法提高模型的新能。
- 数据集增强
视频质量评价方法常采用在图像中随机crop固定大小patch的方式进行空间数据增强。作为对比,我们同时考虑考虑空间和时间数据增强,如图6所示:
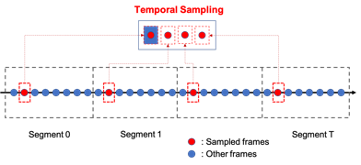
其中,整个视频会被分成T个视频片段(每秒一个片段)。提取空域特征时,每个视频片段随机抽取1帧。同时,为保留帧间的时间关联性,抽样帧之间的时间间隔保持不变。
- 大型数据集预训练
LSVQ [8] 视频质量评价数据集有38,811个视频样本,是目前最大的开源质量评价数据集。因此,我们先在LSVQ数据集上对模型进行预训练,之后基于特定的任务以相对小型的数据集微调模型。
实验结果
我们在两个公开的视频质量评价数据集KoNViD-1k和LIVE-VQC上,与现有SOTA方法进行了对比。我们使用业界最常用的Spearman Rank Order Correlation Coefficient(SROCC)和Pearson Linear Correlation Coefficient(PLCC)作为指标。更高的SROCC表示样本间更好的保序性,更高的PLCC表示与标注分数更好地拟合程度。结果如表2所示。
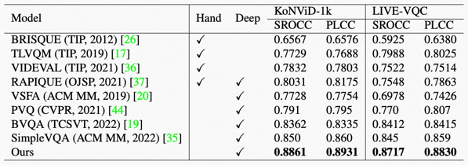
表2. MD-VQA与其他视频质量评价SOTA模型在KoNViD-1k、LIVE-VQC数据集的性能比较。
从表中可以看出,我们在所测试数据集上的SROCC和PLCC均超过了现有SOTA方法,达到了先进性能。
此外,为了探索不同优化方式对模型性能的贡献,我们进行了消融实验(ablation study),如表3所示。
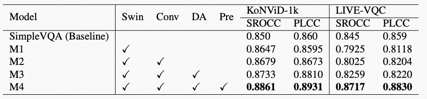
表3. 骨干网络替换(Swin)、特征融合优化(Conv)、数据集增强优化(DA)和大型数据集预训练(Pre)对于模型性能的贡献比较。
从表3中可以看出,骨干网络替换(Swin)、特征融合优化(Conv)、数据集增强优化(DA)和、大型数据集预训练(Pre)对于模型性能的领先性均有贡献。
业务应用
如前所述,随着互联网视频化的深入,越来越多的UGC等非传统广电视频(包括但不限于短视频、直播等)在淘宝直播、逛逛等平台上被生产或播放。通常,由于拍摄设备、环境、技术等各种原因,用户生产的视频画质是参差不齐的。此外,在下发的过程中,视频画质受制于到网络环境、带宽成本、用户机型差异等因素,以及对应的编解码、视频增强处理、视频传输等过程,视频画质往往不可避免地受到影响。那么,如何确保商家和用户在淘宝直播等平台极致的开播和观看体验呢?
针对这个问题,大淘宝音视频技术团队自研了针对UGC视频的无参考视频质量评价模型 —— MD-VQA(Multi-Dimensional Video Quality Assessment),综合视频的语义、失真、运动等多维度信息,来衡量视频绝对质量的高低。MD-VQA已经全面应用于包括淘宝直播、逛逛在内的大淘宝内容业务,“量化”并监控视频业务的大盘画质变化,快速、精准地筛选出不同画质水位的直播间和短视频,配合自研S265编码器、视频增强算子集STaoVideo、以及《电商直播高画质开播指南》[9] 等,帮助提升平台内容画质。此次比赛的冠军方案,就是基于MD-VQA探索出的新方法。
具体来说,以淘宝直播为例,MD-VQA提供分钟级的在线质量监控能力,能够快速、精准地筛选不同画质水位的直播间,协助线上低画质badcase的挖掘分析,实时提醒主播画质问题方面的瓶颈问题,配合《电商直播高画质开播指南》,提供改进措施,使得淘宝直播主播画质满意度显著提升:在收到过提醒的主播中,75%+希望保持和完善实时提醒服务。
此外,MD-VQA在整个阿里集团内部也在支撑越来越多的画质评价相关业务,比如钉钉直播、ICBU直播和支付宝直播,协助监控视频相关业务的画质体验。
参考文献
- Shyamprasad Chikkerur, Vijay Sundaram, Martin Reisslein, and Lina J Karam. Objective video quality assessment methods: A classification, review, and performance comparison. IEEE Transactions on Broadcasting, 57(2):165–182, 2011.
- Dingquan Li, Tingting Jiang, and Ming Jiang. Quality assessment of in-the-wild videos. In Proceedings of the ACM International Conference on Multimedia, pages 2351–2359, 2019.
- Yilin Wang, Junjie Ke, Hossein Talebi, Joong Gon Yim, Neil Birkbeck, Balu Adsumilli, Peyman Milanfar, and Feng Yang. Rich features for perceptual quality assessment of UGC videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13435–13444, 2021.
- Bowen Li, Weixia Zhang, Meng Tian, Guangtao Zhai, and Xianpei Wang. Blindly Assess Quality of In-the-Wild Videos via Quality-aware Pre-training and Motion Perception. IEEE Transactions on Circuits and Systems for Video Technology, 32(9):5944–5958, 2022.
- Wei Sun, Xiongkuo Min, Wei Lu, and Guangtao Zhai. A deep learning based no-reference quality assessment model for UGC videos. In Proceedings of the ACM International Conference on Multimedia, pages 856–865, 2022
- Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12009–12019, 2022.
- Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6202–6211, 2019.
- Zhenqiang Ying, Maniratnam Mandal, Deepti Ghadiyaram, and Alan Bovik. Patch-VQ:’patching up’the video quality problem. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14019–14029, 2021.
- 《服贸会在京举行|淘宝直播携手佳能佳直播联合发布《电商直播高画质开播指南》让品质直播触手可及》
团队介绍
代表阿里巴巴参加本届NTIRE比赛夺魁的参赛团队,出自大淘宝音视频技术团队,负责音视频算法和相关基础技术。团队同时支持大淘宝内容业务,致力于打造业界领先的音视频体验,尤其是视频画质和流畅度,通过视频编码器S265、视频增强方案STaoVideo、无参考视频质量评价模型MD-VQA、以及媒体处理系统TMPS,并通过接入低延时传输网络GRTN,为直播和短视频提供底层核心技术。通过持续的技术打磨和算法创新力求高质量、低成本赋能大淘宝内容业务,助力淘宝内容化战略,所沉淀的平台技术和产品能力亦可被集团其它业务复用。
团队自研的MD-VQA综合视频的语义、失真、运动等多维度信息衡量视频绝对质量的高低,已经全面应用于大淘宝内容业务,“量化”画质,快速、精准地筛选出不同画质水位的直播间和短视频,帮助提升平台内容画质。此次比赛的冠军方案:视频语义、失真、运动多维信息融合方案就是团队同学在日常业务研发中探索出的新方法。
内容化是当前大淘宝的五大战役之一。淘宝内容业务包含多样化的真实场景,具备足够的技术挑战,为团队同学提供了持续迭代技术,实时赋能业务,创造价值的舞台,团队亦可籍此沉淀技术领先性。依托当前技术储备,适当投入高水平的国际赛事,对团队来说是一个很好的练兵和面向业界前沿学习和交流的机会。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
