
作者提出了 LiveNAS 实时视频摄取框架,它利用超分辨率深度神经网络来增强独立于 ingest 端网络带宽的实时视频质量。LiveNAS 应用在线训练,可解决在实时视频传输环境中利用超分辨率的核心挑战。LiveNAS 引入了新颖的设计组件,包括质量优化调度器和内容自适应训练器,以充分实现在线训练的好处。LiveNAS 通过 WebRTC 在各种真实世界的网络轨迹中实现了 PSNR 相比 WebRTC 平均 1.96 dB 的整体视频质量改进,并为直播流观众带来了显着 (12%-69%) 的 QoE 改进。
作者:Jaehong Kim, Youngmok Jung 等
来源:ACM Digital Library
论文题目:Neural-Enhanced Live Streaming: Improving Live Video Ingest
via Online Learning
论文链接:https://dl.acm.org/doi/10.1145/3387514.3405856
内容整理:李江龙
引言
实时流媒体系统主要由两个主要组件组成:在摄取端,使用低延迟流协议将实时视频从原始流媒体传输到媒体服务器;在分发端,内容分发服务器使用自适应比特流来优化质量体验。然而,端到端实时媒体视频传输的流质量从根本上受到流媒体上行带宽及其计算能力限制。神经增强视频传输通过对视频帧应用神经计算来提高视频质量,为解决此限制提供了方案。本文提出了 LiveNAS,采用在线训练在实时视频背景下实现超分辨率,可以为资源受限的移动设备实现 4k 实时摄取。
LiveNAS 由两个 ingest 组件组成。首先,在媒体服务器上,在线训练和推理并行运行。它学习在线视频流的新特征,将其映射从低质量更新为高质量版本,同时使用超分辨率 DNN 增强ingest 流。其次,ingest 客户端传输由其相机捕获的高质量原始帧的小 patches 以及编码视频。这些高质量的 patches 被用作在媒体服务器上训练超分辨率 DNN 的真实标签。
本工作做出了四个关键贡献:
- 为最终用户提高视频质量:通过提高 ingest 质量,LiveNAS 为直播流的最终观众带来了显着的 QoE 改进。
- 受限环境中的 4K 直播:LiveNAS 支持 4K 流式传输,无需实时 4K 编码或对ingest客户端强加高带宽要求。
- 在线训练质量优化:LiveNAS 客户端通过在在线学习环境中平衡高质量训练标签和实时视频之间的带宽分配,最大限度地提高网络视频质量。
- 在线训练的资源优化:提出了一种新的在线训练方法,通过检测训练增益饱和度和场景转换来适应实时视频的内容。
系统总览
LiveNAS 由一个 ingest 客户端和一个 ingest 服务器组成,概览如图 1 所示。

- LiveNAS ingest 客户端的一个显着特点是它会随视频一起发送用于在线训练的高质量帧补丁。两个设计组件在客户端协同工作以最大限度地提高视频质量:质量优化调度程序,用于在训练补丁和实时视频流之间分配带宽;以及选择要传输的高质量标签的补丁采样器。
- LiveNAS 媒体服务器执行在线学习,并使用超分辨率 DNN 将原始视频流转换为更高质量。两个新颖的组件在这里运行:内容自适应在线学习引擎,它动态调整 GPU 使用以进行资源效率训练;以及支持多个 GPU 的 4K 超分辨率的超分辨率处理器。
LiveNAS 摄取客户端设计
质量优化调度器
LiveNAS 使用来自底层传输层的可用带宽估计值,给出 t 时刻的可用带宽 Ct ,LiveNAS 调度程序在高质量标签 pt 和直播视频 vt 之间分配其使用。该模块的目标是找到高质量标签和实时视频之间的带宽分配,以最大限度地提高整体质量。将优化目标表示为视频质量和由于在线训练而产生的未来折扣预期质量增益的总和:

其中 α 是步长。在每个时间步结束时,LiveNAS 客户端采用新的补丁带宽分配 pt+1,并使用该带宽传输高质量的训练补丁。
估计 DNN 增强的梯度

估计视频质量的梯度

更新频率和步长
补丁码率频率必须足够长才能观察在线训练的效果。并且足够短以响应影响视频质量的网络条件和场景变化的变化。因此,我们将更新频率设置为与在线训练时期相同的顺序。我们使用经验确定的 5 秒训练时期和 1 秒更新频率。最后,我们将更新步长设置为 α = 100kbps,并将初始补丁速率设置为 100kbps。这反映了显示前几个 epoch 的在线训练增益所需的最少训练数据量。如果可用带宽 Ct 低于 WebRTC 强制执行的最小编码比特率(200 kbps),我们不会传输任何训练补丁,系统将回退到普通 WebRTC。
验证案例研究
使用来自 3G 网络的真实网络轨迹 和来自 YouTube 的视频流,我们进行了一个案例研究来演示算法在实践中的工作原理。图 3(顶部)显示了 WebRTC 和 LiveNAS 在补丁和实时视频带宽之间分配的可用带宽。补丁带宽从梯度每秒更新一次,如图 3(底部)所示。平均而言,LiveNAS 为补丁比特率分配了 8.9% 的可用带宽。为了进行比较,我们还展示了我们通过在 5 秒的时间窗口内以 25 Kbps 的增量进行详尽搜索而获得的离线最佳补丁带宽分配。我们发现 LiveNAS 非常接近于最大化整体视频质量的离线优化策略。
补丁选择
LiveNAS 客户端发送大小为 120×120 像素的训练补丁,以匹配我们基于补丁的超分辨率 DNN 的维度,每个补丁是整个帧的一小部分。质量优化调度器的带宽限制通常只允许每个训练时期传输几个训练补丁,实际上补丁的选择会影响训练增益,因为某些补丁提供的训练增益比其他补丁更高。因此,补丁选择的目标是在给定补丁带宽下选择训练补丁,使在线训练增益看起来尽可能大且尽可能快。
补丁选择的标准是:首先,补丁应提供更大增益而不引入大偏差;其次,避免对冗余数据进行采样。以此为标准,ingest 客户端从非重叠补丁的网格中随机采样帧中的一个补丁。仅当补丁的编码质量低于整个帧的质量时才进行传输,否则丢弃补丁。基本原理是将更难以编码的补丁作为训练集包含在内将提供更大的好处。不断迭代此过程,直到我们选择少量的补丁(大约 10 个)进行传输。此采样方法在在线训练的五分钟内将平均 PSNR 比随机采样提高了 0.1 到 0.3 dB。
采样补丁必须以高分辨率发送,但原始 RGB 补丁非常大 (43 KB)。因此,我们需要使用压缩来平衡质量和大小。LiveNAS 通过使用有损压缩进行了更好的权衡。我们的实现使用质量级别为 95 (最高质量为 100)的 JPEG。这将补丁大小平均减少到 1/10,而不会导致训练质量显着下降。
在传输补丁时,我们将其时间戳及其在相应帧中的位置包含在内。这使媒体服务器能够为在线训练的最新补丁分配更大的权重,并从编码的视频流中找到低分辨率的对应物。最后,LiveNAS 根据分配的补丁带宽传输补丁传输缓冲区的内容。当补丁传输缓冲区为空时,我们调用重新填充缓冲区的补丁采样器。
LiveNAS 媒体服务器设计
内容自适应在线学习
在线学习方法展示了 GPU 训练成本和视频质量增益之间的权衡。实际的权衡取决于直播视频的内容。对于场景变化不频繁的视频,由于大量跨帧冗余,在线训练增益随着时间的推移显示收益递减并最终饱和。场景频繁变化的视频始终受益于在线学习,因为内容会随着时间而变化。利用这一点,可以通过动态适应最近帧的实时超分辨率增益来提高资源效率,这是在线学习方法相比于预训练模型的优势。为了提高资源效率,我们仔细监控实时超分辨率 (SR) 增益并检测增益饱和度和场景变化,以适应 GPU 使用情况进行训练。当我们观察到 SR 增益饱和时,我们暂停在线训练以节省资源。当当前模型不再为最近的帧提供显着的质量改进时,在线训练将恢复,表明需要进行训练。图 5 的算法总结了我们的设计,该设计使用于训练的 GPU 节省了 65%。
到目前为止,我们假设在线训练从使用标准基准数据集训练的通用超分辨率 DNN 开始。但是,运营商可以选择保留和重用在线学习的结果,用于流行主播的未来流媒体。这重用了先前会话的学习结果,类似于预训练,但保持在线学习仍具有两个好处:1)它仍然受益于资源高效的内容自适应训练;2)即使发生剧烈的场景变化,也能保证显着的质量增益。
超分处理器
- 低延迟和 4K 支持
我们使用的超分辨率 DNN 提供高达 1080p 的实时超分辨率,并以串行方式逐帧完成。LiveNAS 使用多个 GPU 进一步实现实时 4K 超分辨率。当启用多 GPU 推理时,LiveNAS 将一个帧分成多个相等大小的片段,并在不同的 GPU 上为每个片段执行超分辨率,从而实现帧内并行。 - 使用实时数据进行在线学习
由于训练数据不断更新,数据越早添加到数据集中,它就越能接受训练。这是不利的,因为最新收到的补丁通常能更好地反映实时视频的当前状态。为了减轻这种不平衡,我们的在线训练器在组成用于训练的 mini-batch 时对最近的 𝐾 个补丁赋予更大的权重。对于我们的评估,我们使用 𝐾 = 150 并赋予它们四倍于其他旧补丁的权重。这导致 PSNR 有 0.07-0.28 dB 的适度改善。 - 支持多 GPU 训练
LiveNAS 支持多 GPU 训练以加快在线学习速度,从而进一步提高生成的视频质量。聚合多个梯度以同步模型时,我们对用最近的补丁计算的梯度给予更大的权重。当使用三个 GPU 时,我们的多 GPU 学习在 PSNR 方面提供了 0.77 dB 到 1.1 dB 的额外改进。
实现
LiveNAS 是在最先进的开源 ingest 框架 WebRTC 之上实现的。
WebRTC 集成
为了将 LiveNAS 与 WebRTC 集成,我们向 libWebRTC 添加了新的 API。我们在 python 中实现了 LiveNAS 服务器和客户端,以利用 Pytorch 框架和图像处理模块。由于 libWebRTC 是用 C 实现的,我们使用 python C ++包装器来集成 LiveNAS 和 WebRTC。我们通过修改 libWebRTC 中的 call.cc 添加自定义 API,以获得估计的网络带宽、每帧的时间戳、原始解码帧和编码帧。最后,为了从 WebRTC 检索估计的网络带宽,我们扩展了在网络带宽变化时触发的回调。
训练和推理
我们在 Pytorch 中将在线训练过程和推理过程作为一个单独的过程来实现。我们使用来自 NAS 的模型来实现超分辨率。超分辨率输出为 1080p 或 4K,输入可以是 270p、360p、540p、720p 或 1080p。训练补丁到达 LiveNAS 服务器时,与从 lib-WebRTC 检索到的视频中的解码帧一起输入到在线训练过程中。在线训练器利用 ADAM 优化器来优化 DNN 参数。一个 epoch 的迭代次数、小批量大小、输出补丁大小和学习率分别设置为 50、64、120 和 10-4。训练使用单精度,但为了速度,推理是用半精度完成的。在每个训练时期结束时,推理过程是同步的。最终输出被传递到分发端的多比特率编码器。
评估
在媒体服务器上使用两个 Geforce RTX 2080 Ti GPU,一个用于推理,另一个用于训练。使用 2019 年 FCC 美国宽带上行链路测量中的 25 条真实网络轨迹。根据整个数据集的带宽分布对轨迹进行采样,不包括平均上行链路带宽超过 10 Mbps 的部分,以模拟带宽受限的环境。流式传输时,我们根据每个轨迹的平均带宽选择原始 ingest 分辨率,遵循 YouTube 直播设置,如图 6 所示。当原始分辨率为 360p 或 540p(720p 或 1080p)时,LiveNAS 将其放大为1080p (4K)。
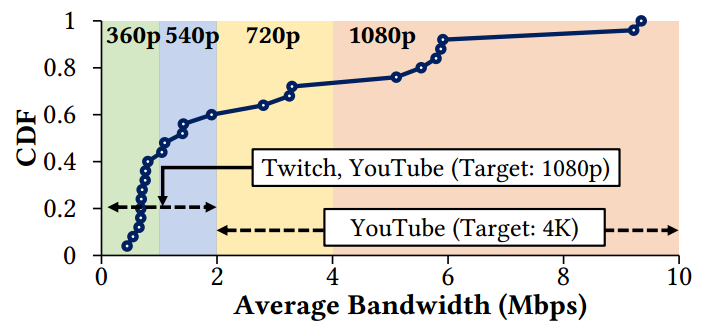
使用 Mahimahi 的网络仿真将网络跟踪应用于 LiveNAS 和 WebRTC 流。使用来自 Twitch 和 YouTube 的流。对于 Twitch,选择五个类别的流媒体,原始质量是 1080p。对于 4K 视频,我们在 YouTube 上搜索四种流行的直播视频类型(Podcast, Sports, Live event, Food/cooking)并选择长度接近的高质量(比特率 >16.8 Mbps)的 4K 视频。视频平均长度为95分钟。9 个视频跨越 25 条轨迹进行流式传输,总流式传输时间为 366 小时。编解码器使用 WebRTC 的默认编解码器 VP8。使用峰值信噪比 (PSNR) 和结构相似性指数(SSIM)指标来衡量视频质量并测量延迟。
视频质量提升
将 LiveNAS 与三种替代设计进行了比较,分别是:
- WebRTC 不使用 DNN,而是使用双线性插值来扩展到目标分辨率。
- 通用超分辨率 使用在 DIV2K 基准数据集上训练的超分辨率 DNN。
- 具有预训练模型的超分辨率 使用来自同一流送器的先前流(如果可用)来预训练模型。对于 Twitch 直播,我们会在其播出时间前的五天内手动挑选与当前直播非常相似的最佳先前直播。为了公平比较,我们使用与 LiveNAS 相同数量的 GPU 进行训练。
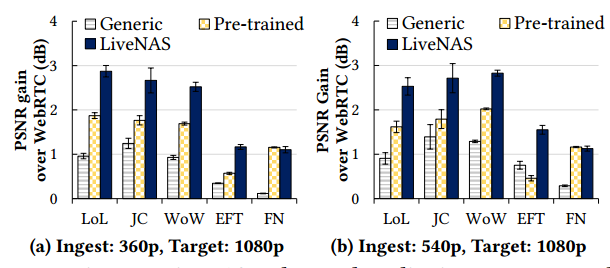
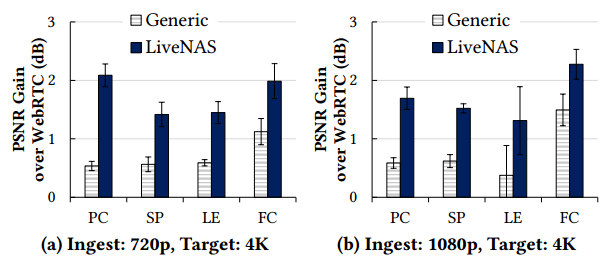
LoL: League of Legends, JC: Just Chatting, WoW: World of Warcraft, EFT: Escape from Tarkov, FN: Fortnite
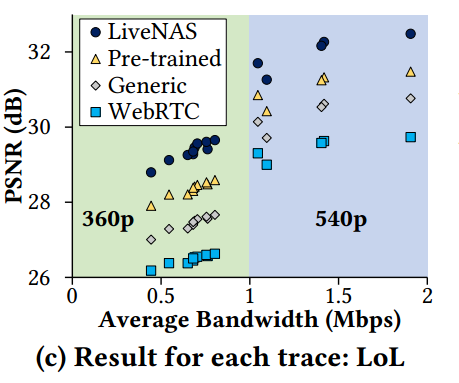
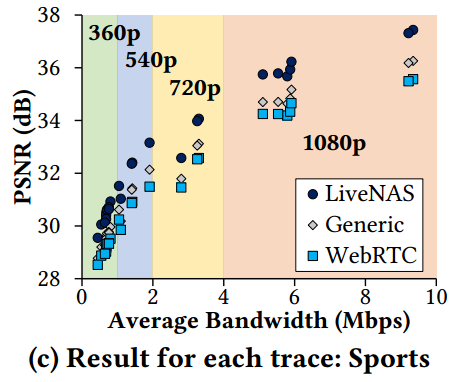
每个网络轨迹的视频绝对质量如图 9,图 10 所示:
LiveNAS 的资源效率
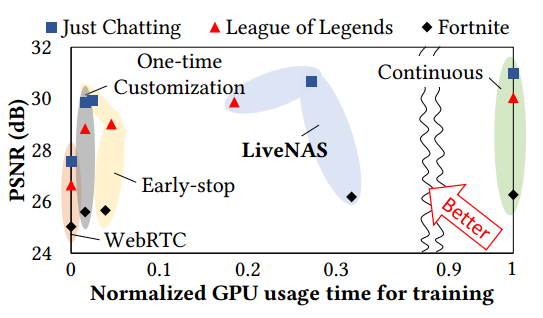
我们将 LiveNAS 与三种基线训练方法进行了比较:
- 一次性定制在流的前 60 秒预先训练 DNN。
- 使用提前停止训练 DNN 在线学习一次,时间由我们的增益饱和检测动态选择。之后,即使检测到场景变化,它也不会在整个流中恢复训练。
- 持续在线学习在整个流中不断训练DNN,没有任何暂停。训练时间与流媒体时间相同。
在线学习效率
图 11 和 12 显示了与流长度相比在线训练的 GPU 使用情况。平均而言,LiveNAS 仅在 35% 的流媒体时间中执行在线学习。
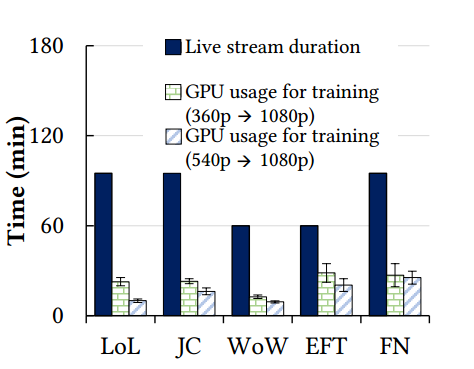
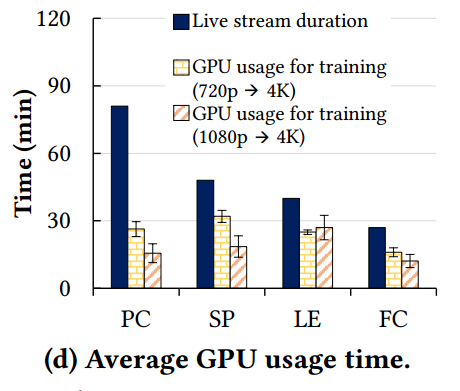
图 13 比较了训练中的 GPU 使用时间以及每个视频和方案的最终视频质量。与持续训练相比,LiveNAS 提供几乎相同的质量,同时使用 25% 的 GPU 资源。然而,提前停止和一次性定制会导致质量显着下降,因为它跟不上场景变化。
成本
我们量化计算成本,假设 ingest 带宽遵循评估时使用的分布,ingest 服务器位于公共云,成本在大量实时流上分摊,以及跨分布式 GPU 的模型更新开销是不可忽视的。一个 GPU 用于训练,多个 GPU 用于确保 4K 的实时推理。在 Google Cloud 上使用带有四个 Nvidia Tesla V100 GPU 的 16 个 vCPU 机器,每个流每小时的平均成本为 4.69 美元。
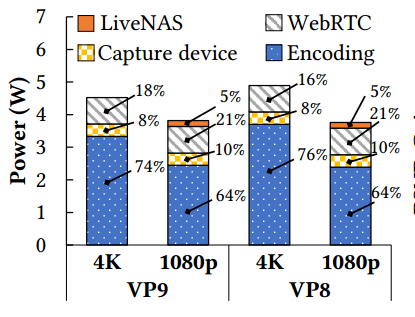
LiveNAS 客户端的能效
LiveNAS 消耗更少的能量,因为客户端可以在较低的分辨率下执行编码,这要归功于 ingest 服务器的超分辨率。我们使用 NVIDIA 的 Jetson TX2 将客户端与 WebRTC 的功耗进行比较,我们将 9.5 Mbps 的 WebRTC 上的 4K 流与提供相同质量的 LiveNAS 进行比较,后者以 7 Mbps 的速度提供 1080p 实时ingest。图 14 显示了功耗。LiveNAS 分别为 VP9 和 VP8 编码节省 16% 和 23% 的电量,同时提供相同的质量。这主要是因为 4K 编码比 VP9 和 VP8 的 1080p 编码消耗的功率分别多 36.3% 和 54.7%。
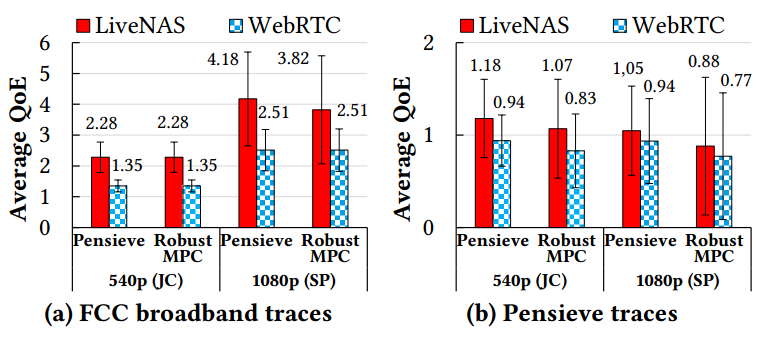
在分发端提升 QoE
图 15 显示 LiveNAS ingest 比 WebRTC ingest 使 Twitch 流的平均 QoE 提高了 27%-69%,YouTube 视频的平均 QoE 提高了 12%-66%。改进来自两个原因:1) LiveNAS 提供更高分辨率的块,使拥有充足带宽的观众受益。2) 每个编码块都具有更好的质量,因为 LiveNAS 提高了ingest视频质量。FCC 宽带迹线(图 15a)的改进远大于 Pensieve 迹线(图 15b),因为前者具有更高的带宽,可以接收质量更好的更高分辨率块。
来源:媒矿工厂第一时间发布最新最有料的媒体技术资讯。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
