
图像分割是计算机视觉中的一项任务,涉及将特定图像划分为多个片段,其中每个片段代表图像中的对象或区域。这项任务对于对象检测、图像识别和自动驾驶等应用非常重要。
TensorFlow 是一个开源框架,用于构建和训练机器学习模型,在我们的例子中是图像分割模型。Tensorflow 提供执行图像分割任务所需的工具和预训练模型。
图像分割有一些现实世界的用例。他们包括:
- 对象识别和跟踪:图像分割用于实时跟踪和识别人、车辆和动物等对象。这主要用于安全系统、监视和自主机器人。
- 医学成像:图像分割用于查看和分割身体中的结构,例如器官、肿瘤和血管。这些数据用于诊断、治疗和研究。
- 自动驾驶:检测和分类道路上的行人和车辆等对象,以避免发生事故和碰撞
学习目标
- 该项目的目标是训练一个可以为 59 个类别创建分割蒙版的模型。第一类代表个人的背景,而其余 58 类代表服装项目,例如衬衫、头发、裤子、皮肤、鞋子、眼镜等。
- 除此之外,是从图像中可视化模型创建的蒙版,并将它们与正确的蒙版进行比较,以评估模型的准确性。
- 此外,这旨在让用户了解图像分割过程以及如何实现它。
术语
- 深度学习: 是机器学习的一个子集,它使用具有三层或更多层的神经网络来模拟人脑从数据中学习的行为。
- 图像分割: 将图像划分为片段或区域的过程,每个片段或区域代表一个单独的对象或图像的一部分。
- Mask:图像的一部分,与图像的其余部分隔离开来。
- 数据增强: 一种通过对现有数据应用转换来人为增加数据集大小的方法。
- 全卷积神经网络(FCNN)是一种只执行卷积(和子采样或上采样)操作的神经网络。该网络包括三种主要类型的层:卷积层、池化层和全连接层。
- UNet 架构: 一种 U 形编码器-解码器网络架构,包括四个编码器块和四个使用桥连接的解码器块。
- DenseNet121: 架构由四个密集块和三个过渡层组成。每个密集块都有不同数量的层,每个层都有两个卷积来执行卷积操作。
- Upstack: 也称为上采样或转置卷积层。它们用于网络的解码器部分,以提高特征图的空间分辨率。
- Downstack:也称为最大池化层。它们用于网络的编码器部分,以降低特征图的空间分辨率。
- Skip Connections: 用于连接相应的encoder和decoder层。
数据集描述
该数据集由 1000 张图像和 1000 个相应的PNG 格式语义分割蒙版组成。每个图像的大小为 825 像素 x 550 像素。
分割蒙版属于 59 个类,第一类是个人背景,其余 58 个类属于服装项目,例如衬衫、头发、裤子、皮肤、鞋子、眼镜等。
这个数据集在 Kaggle 上可用:https://www.kaggle.com/datasets/rajkumarl/people-clothing-segmentation
导入必要的库和依赖
导入执行此项目中的任务所需的库。
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import matplotlib as mpl
from tqdm import tqdm
from sklearn.model_selection import train_test_split数据集准备
我们将首先创建两个单独的列表来收集图像和蒙版数据集的路径,然后我们将使用 os.walk() 函数遍历所有文件。最后,我们将打印出两个列表的长度。
# a list to collect paths of 1000 images
image_path = []
for root, dirs, files in os.walk('/content/png_images'):
# iterate over 1000 images
for file in files:
# create path
path = os.path.join(root,file)
# add path to list
image_path.append(path)
len(image_path)
# a list to collect paths of 1000 masks
mask_path = []
for root, dirs, files in os.walk('/content/png_masks'):
#iterate over 1000 masks
for file in files:
# obtain the path
path = os.path.join(root,file)
# add path to the list
mask_path.append(path)
len(mask_path)
这将分别打印出 1000 张图像和 1000 个蒙版的长度。
在整理数据集以获得正确的图像蒙版对之后,我们将解码图像和蒙版以将它们存储在单独的列表中。为此,我们将使用 Tensorflow 函数将每个 PNG 文件读入内存。然后将它们解码为张量并附加到两个单独的列表:蒙版和图像。
# create a list to store images
images = []
# iterate over 1000 image paths
for path in tqdm(image_path):
# read file
file = tf.io.read_file(path)
# decode png file into a tensor
image = tf.image.decode_png(file, channels=3, dtype=tf.uint8)
# append to the list
images.append(image)
# create a list to store masks
masks = []
# iterate over 1000 mask paths
for path in tqdm(mask_path):
# read the file
file = tf.io.read_file(path)
# decode png file into a tensor
mask = tf.image.decode_png(file, channels=1, dtype=tf.uint8)
# append mask to the list
masks.append(mask)可视化数据集样本
下面的代码使用 matplotlib 使用 for 循环创建 4 到 6 范围内的图像图形。
plt.figure(figsize=(25,13))
# Iterate over the images in the range 4-6
for i in range(4,7):
# Create a subplot for each image
plt.subplot(4,6,i)
# Get the i-th image from the list
img = images[i]
# Show the image with a colorbar
plt.imshow(img)
plt.colorbar()
# Turn off the axis labels
plt.axis('off')
# Display the figure
plt.show()输出:

我们再次使用 matplotlib 打印出相应的蒙版。我们定义了一个规范化器,以便蒙版具有一致性。
# Define a normalizer that can be applied while visualizing masks to have a consistency
NORM = mpl.colors.Normalize(vmin=0, vmax=58)
# plot masks
plt.figure(figsize=(25,13))
for i in range(4,7):
plt.subplot(4,6,i)
img = masks[i]
plt.imshow(img, cmap='jet', norm=NORM)
plt.colorbar()
plt.axis('off')
plt.show()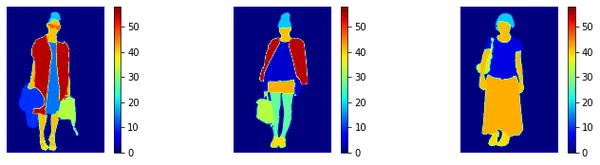
数据预处理
我们将使用两个函数开始数据预处理,以从数据集中获取图像和相应的蒙版,并将它们的大小调整为 128 x 128 像素的固定大小。
函数 resize_image 将重新缩放像素值,而 tf.image.resize 会将图像调整为所需的大小。使用 tf.image.resize 函数调整蒙版的大小,而不缩放像素值。
最后,它将蒙版张量的数据类型转换为 uint8。
然后,我们将使用列表推导式将调整大小函数分别应用于原始图像和蒙版列表中的每个图像和蒙版。调整大小的图像和蒙版的结果列表与原始列表具有相同的大小。
#functions to resize the images and masks
def resize_image(image):
# scale the image
image = tf.cast(image, tf.float32)
image = image/255.0
# resize image
image = tf.image.resize(image, (128,128))
return image
def resize_mask(mask):
# resize the mask
mask = tf.image.resize(mask, (128,128))
mask = tf.cast(mask, tf.uint8)
return mask
X = [resize_image(i) for i in images]
y = [resize_mask(m) for m in masks]
len(X), len(y) 这会在 X 和 y 轴上打印出 1000 的长度。
可视化调整大小的图像和蒙版的样本。
#visualizing a resized image and respective mask
# plot an image
plt.imshow(X[36])
plt.colorbar()
plt.show()
#plot a mask
plt.imshow(y[36], cmap='jet')
plt.colorbar()
plt.show()输出:

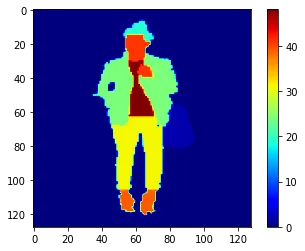
将数据拆分为训练和验证
我们将从将数据集 X 和 y 拆分为训练集和验证集开始。验证数据将是训练数据的 20%,并且 random_state 设置为 0 以实现可重复性。
之后,我们将使用张量切片方法从 NumPy 数组 train_X、val_X、train_y 和 val_y 创建 TensorFlow Dataset 对象。
# split data into 80/20 ratio
train_X, val_X,train_y, val_y = train_test_split(X, y, test_size=0.2,
random_state=0
)
# develop tf Dataset objects
train_X = tf.data.Dataset.from_tensor_slices(train_X)
val_X = tf.data.Dataset.from_tensor_slices(val_X)
train_y = tf.data.Dataset.from_tensor_slices(train_y)
val_y = tf.data.Dataset.from_tensor_slices(val_y)
# verify the shapes and data types
train_X.element_spec, train_y.element_spec, val_X.element_spec, val_y.element_spec数据增强
数据增强是一种通过使用现有数据创建数据集的修改副本来人为增加训练集的方法。以下是函数及其作用:
- Brightness: 调整图像的亮度
- Gamma: 调整图像的Gamma值。蒙版没有改变。
- Hue: 调整图像的色调。蒙版没有被转换。
- Crop: 裁剪图像和蒙版并调整它们的大小。
- Flip_hori: 水平翻转图像和蒙版。
- Flip_vert: 垂直翻转图像和蒙版。
- Rotate: 将图像和蒙版都顺时针旋转 90 度。
每个函数都将图像和蒙版的张量作为输入,并返回结果图像张量和原始蒙版张量。这些变换被设计为以相同的方式应用于图像和蒙版张量,以便它们保持对齐。这用于从原始数据生成新的训练示例。
# adjust brightness of image
# don't alter in mask
def brightness(img, mask):
img = tf.image.adjust_brightness(img, 0.1)
return img, mask
# adjust gamma of image
# don't alter in mask
def gamma(img, mask):
img = tf.image.adjust_gamma(img, 0.1)
return img, mask
# adjust hue of image
# don't alter in mask
def hue(img, mask):
img = tf.image.adjust_hue(img, -0.1)
return img, mask
def crop(img, mask):
# crop both image and mask identically
img = tf.image.central_crop(img, 0.7)
# resize after cropping
img = tf.image.resize(img, (128,128))
mask = tf.image.central_crop(mask, 0.7)
# resize afer cropping
mask = tf.image.resize(mask, (128,128))
# cast to integers as they are class numbers
mask = tf.cast(mask, tf.uint8)
return img, mask
# flip both image and mask identically
def flip_hori(img, mask):
img = tf.image.flip_left_right(img)
mask = tf.image.flip_left_right(mask)
return img, mask
# flip both image and mask identically
def flip_vert(img, mask):
img = tf.image.flip_up_down(img)
mask = tf.image.flip_up_down(mask)
return img, mask
# rotate both image and mask identically
def rotate(img, mask):
img = tf.image.rot90(img)
mask = tf.image.rot90(mask)
return img, mask然后我们将解压缩图像和蒙版文件,应用增强函数,并将新数据连接到训练集。
# zip images and masks
train = tf.data.Dataset.zip((train_X, train_y))
val = tf.data.Dataset.zip((val_X, val_y))
# perform augmentation on train data only
a = train.map(brightness)
b = train.map(gamma)
c = train.map(hue)
d = train.map(crop)
e = train.map(flip_hori)
f = train.map(flip_vert)
g = train.map(rotate)
# concatenate every new augmented sets
train = train.concatenate(a)
train = train.concatenate(b)
train = train.concatenate(c)
train = train.concatenate(d)
train = train.concatenate(e)
train = train.concatenate(f)我们现在有一个数据集是原来的800*7=5600加上原来的800一共是6400个训练样例。之后,设置批量大小和缓冲区大小,为模型构建做好准备。
#setting the batch size
BATCH = 64
AT = tf.data.AUTOTUNE
#buffersize
BUFFER = 1000
STEPS_PER_EPOCH = 800//BATCH
VALIDATION_STEPS = 200//BATCH
train = train.cache().shuffle(BUFFER).batch(BATCH).repeat()
train = train.prefetch(buffer_size=AT)
val = val.batch(BATCH)定义和构建模型
我们将使用 FCNN(全卷积神经网络),如上所述,它包含两个部分:编码器(下层)和解码器(上层)。
- 编码器是卷积神经层的下层堆栈,负责从输入图像中提取特征。
- 解码器是转置卷积神经层的上层堆栈,可根据提取的特征构建分割图像。
在这个项目中,我们将使用 U-Net 架构。
我们希望使用 U-Net 架构的功能方法,但我们将拥有适合我们功能的架构。下层堆栈可以是为图像分类训练的预训练 CNN(例如,MobileNetV2、ResNet、NASNet、Inception、DenseNet 或 EfficientNet)。
它可以有效地提取特征。但是我们必须构建我们的上层堆栈以匹配我们的类(此处为 59),构建跳过连接,并使用我们的数据对其进行训练。
在这种情况下,我们将使用 Keras 的 DenseNet121。
# Use pre-trained DenseNet121 without head
base = keras.applications.DenseNet121(input_shape=[128,128,3],
include_top=False,
weights='imagenet')
接下来,我们为 CNN 模型定义一个跳过连接列表。跳跃连接用于缓解深度神经网络中的梯度消失问题,这种问题在训练多层网络时可能会发生。
跳跃连接的想法是跳过一个或多个层并将较早的层直接连接到较晚的层,从而使梯度在训练过程中更容易流动。它们用于 U-Net 架构以提高语义分割的准确性。
#final ReLU activation layer for each feature map size, i.e. 4, 8, 16, 32, and 64, required for skip-connections
skip_names = ['conv1/relu', # size 64*64
'pool2_relu', # size 32*32
'pool3_relu', # size 16*16
'pool4_relu', # size 8*8
'relu' # size 4*4
]构建下层
我们正在构建下层堆栈,用于从输入图像中提取特征并对其进行下采样以降低空间分辨率。它使用 DenseNet 模型,输入、输出和权重设置不更新。
#output of these layers
skip_outputs = [base.get_layer(name).output for name in skip_names]
#Building the downstack with the above layers. We use the pre-trained model as such, without any fine-tuning.
downstack = keras.Model(inputs=base.input,
outputs=skip_outputs)
# freeze the downstack layers
downstack.trainable = False构建上层
上层堆栈用于 U-Net 架构的解码器部分以进行图像分割。我们将为 up-stack pix2pix 模板使用上采样模板,该模板在 TensorFlow 示例存储库中以开源方式提供。
上层堆栈由四个上采样层组成,通过执行 2x 最近邻上采样,然后是步幅为 1 的 3×3 卷积层,将特征图的空间分辨率加倍。输出通道的数量在每个连续层中从 512 减少到64.
!pip install -q git+https://github.com/tensorflow/examples.git --quietfrom tensorflow_examples.models.pix2pix import pix2pix
# Four upstack layers for upsampling sizes
# 4->8, 8->16, 16->32, 32->64
upstack = [pix2pix.upsample(512,3),
pix2pix.upsample(256,3),
pix2pix.upsample(128,3),
pix2pix.upsample(64,3)]通过将下层堆栈和上层堆栈与跳跃连接合并,构建具有跳跃连接的 U-Net 模型。该代码使用前面部分中定义的堆栈下层和堆栈上层定义了用于图像分割的完整 U-Net 架构。
下层堆栈对图像进行下采样并提取特征,上层堆栈用于将特征映射上采样到图像的原始输入大小,并将它们与下层堆栈的相应跳过连接起来,以细化分割输出。
最后,将具有 59 个过滤器和内核大小为 3 的 Conv2DTranspose 层应用于输出特征图,以获得最终的分割图。
# define the input layer
inputs = keras.layers.Input(shape=[128,128,3])
# downsample
down = downstack(inputs)
out = down[-1]
# prepare skip-connections
skips = reversed(down[:-1])
# choose the last layer at first 4 --> 8
# upsample with skip-connections
for up, skip in zip(upstack,skips):
out = up(out)
out = keras.layers.Concatenate()([out,skip])
# define the final transpose conv layer
# image 128 by 128 with 59 classes
out = keras.layers.Conv2DTranspose(59, 3,
strides=2,
padding='same',
)(out)
# complete unet model
unet = keras.Model(inputs=inputs, outputs=out)编译和训练模型
编译模型的函数,学习率为 0.001,精度为评估指标。
# compiling the model
def Compile_Model():
unet.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.RMSprop(learning_rate=0.001),
metrics=['accuracy'])
Compile_Model()在训练集上拟合模型并对模型进行微调。
#training and fine-tuning
hist_1 = unet.fit(train,
validation_data=val,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
epochs=20,
verbose=2)使用模型进行蒙版预测。
# select a validation data batch
img, mask = next(iter(val))
# make prediction
pred = unet.predict(img)
plt.figure(figsize=(20,28))
k = 0
for i in pred:
# plot the predicted mask
plt.subplot(4,3,1+k*3)
i = tf.argmax(i, axis=-1)
plt.imshow(i,cmap='jet', norm=NORM)
plt.axis('off')
plt.title('Prediction')
# plot the groundtruth mask
plt.subplot(4,3,2+k*3)
plt.imshow(mask[k], cmap='jet', norm=NORM)
plt.axis('off')
plt.title('Ground Truth')
# plot the actual image
plt.subplot(4,3,3+k*3)
plt.imshow(img[k])
plt.axis('off')
plt.title('Actual Image')
k += 1
if k == 4: break
plt.suptitle('Predition After 20 Epochs (No Fine-tuning)', color='red', size=20)
plt.show()
从第 21 个 epoch 到第 40 个 epoch 训练模型和微调。
downstack.trainable = True
# compile again
Compile_Model()
# train from epoch 20 to 40
hist_2 = unet.fit(train,
validation_data=val,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
epochs=40, initial_epoch = 20,
verbose = 2
)使用模型进行蒙版预测。
# select a validation data batch
img, mask = next(iter(val))
# make prediction
pred = unet.predict(img)
plt.figure(figsize=(20,30))
k = 0
for i in pred:
# plot the predicted mask
plt.subplot(4,3,1+k*3)
i = tf.argmax(i, axis=-1)
plt.imshow(i,cmap='jet', norm=NORM)
plt.axis('off')
plt.title('Prediction')
# plot the groundtruth mask
plt.subplot(4,3,2+k*3)
plt.imshow(mask[k], cmap='jet', norm=NORM)
plt.axis('off')
plt.title('Ground Truth')
# plot the actual image
plt.subplot(4,3,3+k*3)
plt.imshow(img[k])
plt.axis('off')
plt.title('Actual Image')
k += 1
if k == 4: break
plt.suptitle('Predition After 40 Epochs (By Fine-tuning from 21th Epoch)', color='red', size=20)
plt.show()
模型有了很大的改进。
性能曲线
我们将使用代码来可视化跨多个时期的深度学习模型的训练和验证准确性。
history_1 = hist_1.history
acc=history_1['accuracy']
val_acc = history_1['val_accuracy']
history_2 = hist_2.history
acc.extend(history_2['accuracy'])
val_acc.extend(history_2['val_accuracy'])
plt.plot(acc[:150], '-', label='Training')
plt.plot(val_acc[:150], '--', label='Validation')
plt.plot([50,50],[0.7,1.0], '--g', label='Fine-Tuning')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.ylim([0.7,1.0])
plt.legend()
plt.show()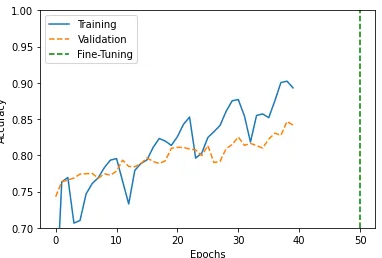
该模型肯定会随着epoch和训练数据的增加而改进。
结论
该项目实现了训练一个模型的目标,该模型可以为 59 类服装生成蒙版。我们能够将生成的蒙版与数据集中相应的蒙版进行比较。我们准备了数据,将其解码为张量,调整大小,拆分数据集,执行数据扩充,并使用 UNet 架构训练模型。
- 对象分割在许多领域都有实际应用,包括计算机视觉、医学成像、机器人和独立驾驶。
- 使用 TensorFlow 进行对象分割的过程包括数据集准备、数据预处理、数据扩充、定义模型、将数据拆分为训练集和验证集,然后训练和微调模型以获得所需的结果。
- 对象分割可用于从随机图像创建衣服蒙版,用于时尚行业。
github:https://github.com/KevKibe/Semantic-Image-Segmentation-using-Tensorflow-Keras/tree/main
作者:磐怼怼 | 来源:公众号——深度学习与计算机视觉(uncle_pn)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
