
本文作者
刘璟:哔哩哔哩高级算法工程师
齐竟雄:哔哩哔哩高级算法工程师
唐哲:哔哩哔哩高级算法工程师
李傲:哔哩哔哩资深算法工程师
需求背景
当前站内存在一定比例的UP主投稿重复、低编辑度的低创视频投稿的情况。低编辑度重复投稿表现为,相同或不同视频作者对同一视频素材进行黑边、裁剪、渣清、模板、录屏、变形、滤镜、模糊填充等不影响内容实质的编辑后进行反复投稿,如下图所示。

图1:同样的画面与文字内容,套用不同模板。
图2:模糊填补、视频水印、播放器录屏、黑边填补多重嵌套。
图3:直播录屏+水印+黑边多重嵌套。
图4:包含滑动弹幕、super chat和直播间样式的具有复杂干扰的直播间录屏。
图5:黑边+白边。
同质内容的重复投稿加重了安全与社区审核的负担,影响了流量分配的公平性,同场景同屏或不同刷展现多个相同内容稿件降低了用户的使用体验,并且增加了其他任务的机器成本。因此,我们需要引入一套能够支持B站现有超大规模视频量级的视频检索系统(下称撞车系统),对所有新增视频,在所有历史视频库中进行查重匹配,对低编辑度的视频进行识别,并对撞车视频向审核人员给出源视频的提示,通过该系统对原创作者的权益进行保护。
本文将重点围绕算法架构优化(准召、效果提升)和工程性能加速优化(降本增效)两方面进行抽象与阐述,忽略不对机器性能、资源占用起明显作用的传统工程架构设计。我们认为体现内容原创度的本质在于视频画面与音轨,因此本文不对标题、封面、简介等额外信息作研讨。
难点挑战
视频查重对模型的准确率和召回率同时有着较高要求,准确率低会影响审核对于撞车环节的人力时间成本投入,召回率低会增加推荐系统bad case反馈率。以下几点为影响模型准确率和召回率的重要因素:
1、 缺乏符合B站视频数据分布的,能表征不同编辑程度的图像距离的预训练特征,这要求我们使用B站自己的数据对查重场景自研一整套特征提取模型的训练机制;
2、 为了实现快速推理节约GPU需求,我们将输入特征提取模型的分辨率设置为224*224,而B站低编辑度视频中存在大量通过冗余区域增强来逃避撞车系统的视频,这使核心区域占比过小,分辨率过低,严重影响判断精度,这要求我们设计一套预处理算法,刨除冗余区域,提取可能为编辑源的画面主体内容;
3、 全站底库视频量级大,而返回结果需要在720P每秒一帧视频产生后的10秒内获取,这要求我们不能使用严格的逐帧匹配,而需要通过二阶段策略,由一阶段先粗筛召回部分候选集压缩计算量,在二阶段实现严格精准的片段匹配。同时我们通过自研深度学习推理框架,对接硬件解码SDK,GPU处理整个预处理流程,CUDA实现音频特征提取等性能优化手段,对各个阶段进行工程加速。经过优化后,目前超过96%的视频能在审核进入人审页面后及时给到撞车的判断结果。
整体架构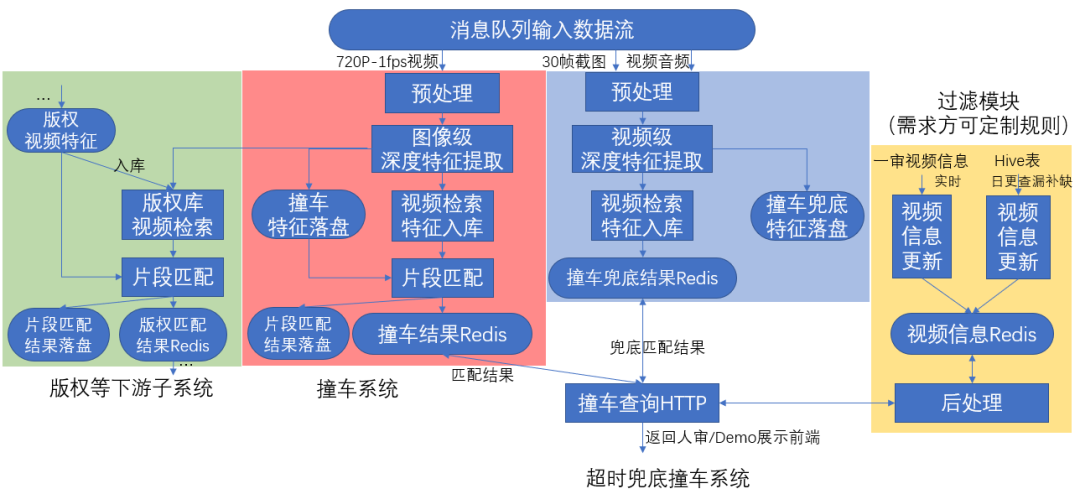

我们将撞车系统设计为4个子系统:版权等下游子系统、撞车系统、超时兜底撞车系统、过滤模块。
撞车系统
为整个视频查重系统的主系统。存储所有B站历史视频的特征形成检索库,所有新上传的视频均需对历史视频库进行检索与精确的匹配。该系统分为视频预处理、特征提取、检索库粗筛视频对、片段精确匹配与特征结果落盘这4项子流程,占用整个查重系统中最大的资源量,同时有着最好的准确率与召回率。数据流交互过程如图所示(红色区块),输入720P每秒截一帧的视频流,输出所有落盘特征、实时更新的检索库索引与最终的匹配结果。
超时兜底撞车系统
为撞车系统的附属系统,拥有更轻量化的数据流和模型结构,用较小的成本对主系统因工程超时导致的漏放进行一定程度的补召回。输入为视频前5分钟等间距30帧的快照截图与从原始视频抽取出的音频流。
下游子系统
应用于版权、黑样本库等其他子业务中。与主系统的完整视频库互相独立,库更加轻量,不同子业务可以根据资源预算选择不同级别的参数配置。
过滤模块
数据流引入稿件视频信息,为业务方按需定制后处理过滤规则。
算法优化
特征提取优化:
撞车系统的特征提取分为图像前处理策略、模型和训练方法。我们使用B站视频帧数据通过自监督的训练方式构建了适合B站场景的能表征视频编辑度距离的embedding提取器,设计了一套核心内容框提取器,并在图像对测试集上通过多种trick进行迭代得到了最优解。
图像前处理策略用于优化入库图像质量。并不是所有的图像都是优质图像,低质图像入库会对后续匹配环节带来精度影响。对于特定的图像,例如画中画情形,实际有效画面在图像的内部,在图像匹配时希望将有效部分裁剪出来进行匹配。为此我们进行了针对性的处理:用边缘检测的方法找出图像中的明显边界,然后将所有边界组合成一个矩形,将矩形内部的图片从原图中裁剪出来。
模型的目标是训练一个特征提取器,能够将相似图片的特征拉进,不相似的特征拉远。特征提取器的网络结构是ResNet50。具体来说,训练模型需要标注好的数据,而一般有两种方法获取带标注的数据,一种是自己人工标注,另一种是寻找开源的数据集。这两种方法都有各自的缺点:自己人工标注需要花费大量的标注成本,开源数据集中的数据又和实际的业务场景相差较大导致迁移后不一定能有很好的效果。所以针对于训练特征提取器的问题,我们使用了自监督的训练方式来训练模型,自监督训练方式虽然也会用到标注,但这个标注不需要人为去标,而是通过一些逻辑设计,自动地生成这个标注信息。
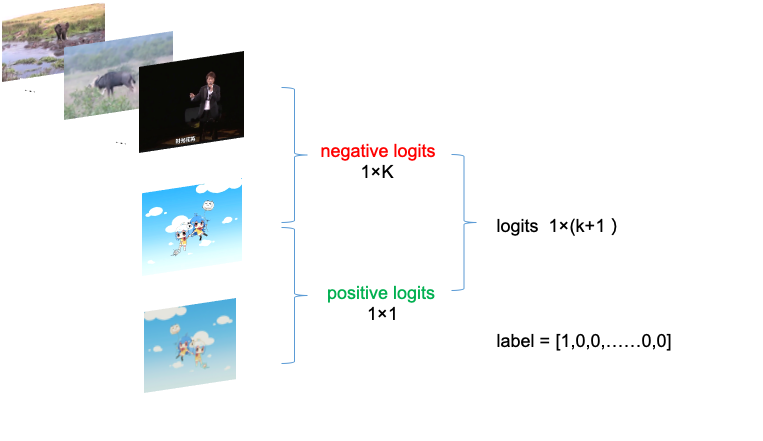
具体训练方法如上图所示,首先准备一系列图片作为负样本集,如第一行所示。这个负样本集保持足够大,并且随着训练的过程动态更新。然后输入一张训练图像和它的随机数据增强,如二、三行所示。值得强调的是这个数据增强是模拟图片常见的编辑方式,例如裁剪、翻转、改变颜色、模糊等等,这两张图像可以认为是正样本对,也可以理解为两张图像相似。训练的过程中将上述提到的图像通过卷积神经网络提取特征向量,两张正样本的特征需要接近,计算两张图像的余弦相似度得到 positive logits。同样的,计算第二行图像和第一行的负样本特征的余弦相似度得到负样本的 negative logits。将positive logits 和 negative logits拼接起来可以得到一个形状为 1 × (1+k) 的logits向量。而这个向量的含义我们是知道的:其中1是正样本的相似度,k 为负样本的相似度。只需要用长度(1+k)的label [1,0,0 ……,0,0]就可以约束,以交叉熵为loss就可以训练模型了。
在训练过程中,负样本的队列要一直动态变化,否则模型见过的负样本太少会影响效果,具体的实现方式是每训练一张图像后,将这张图像放入负样本队列的尾部,队首的图像出队列,进入图像的不同:导致正负样本的组合都不同。随着训练图像的增加,模型就可以学习什么样的图像相似,什么样的图像不相似。
为了提升模型的最终效果,在训练过程中也添加了些提升效果的技巧。例如添加数据增强的种类,使用大模型(ViT)作为teacher来蒸馏ResNet50等等,同时为了提升模型的推理速度,我们对模型进行了量化。
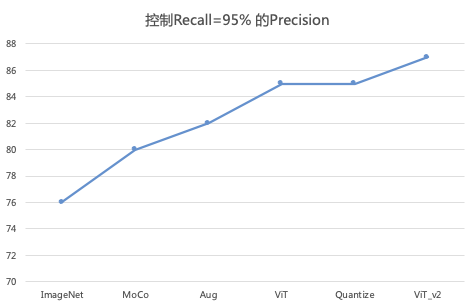
为评估模型的特征提取效果,我们准备了一批图片对作为测试集,包含3万组正负图片对。测试方法是评估模型能不能将相似的图片匹配上,将不相似的图片区分出来。在模型迭代过程中,我们首先使用了开源的ImageNet作为baseline,后续做了MoCo、数据增强 (Aug)、轻量ViT蒸馏ResNet50(ViT)、对ViT进行8bit量化加速(Quantize)、大ViT蒸馏ResNet50(ViT_v2)等优化,迭代效果逐步提升。
二阶段匹配策略:
撞车系统设计了二阶段匹配策略,即粗筛和精排。通过该匹配策略,我们能做到在10秒内应对数十亿级向量检索库做完片段维度的匹配,达到96%的及时率。
在视频粗筛任务中,对视频指纹特征在欧氏距离上进行K近邻召回是一种广泛应用的筛选方案。随着向量维度和数量的增加,直接进行K近邻搜索会引入极大的计算量和存储消耗,造成系统性能瓶颈。近似近邻检索技术是一种处理大规模特征检索任务的有效方案,利用倒排索引、特征量化等手段,在可控的精度损失下,可以获取远优于暴力检索的计算速度和更小的向量存储成本。在近似近邻检索时我们采取了积极的压缩和过滤策略,使用100W+的倒排桶数量,采用PQ32的方式存储向量。当前总入库规模超过十亿级。
对版权视频检索业务,处理单个视频的查询任务时,对视频中每帧图像最相似的10个库内指纹进行计数,可以筛选出指纹库中相关度最高的5个视频,将这些视频发往精排进行详细比对。考虑到连续时间内,视频相似度通常较高,指纹入库采用了2s1f的方式以减少计算和内存资源的消耗。对于撞车业务,直接对均值特征卡阈值进行召回,为保召回率,粗筛阶段采取非常宽松的阈值策略,由精排匹配阶段保高准确率。
视频精排任务可以看作两组视频序列特征的匹配问题,在由查询视频与注册视频指纹向量生成的损失矩阵中寻找正确的匹配关系。我们采用的精排策略包含了候选生产和片段过滤两个步骤。
在进行候选生成时,需要通过相似帧匹配获得查询视频帧与注册视频帧的相似关系,形式化的记为,即查询视频第帧与记录视频第帧存在大于0的相似度。然后利用KNN召回,可获得如下的视频帧相似关系。

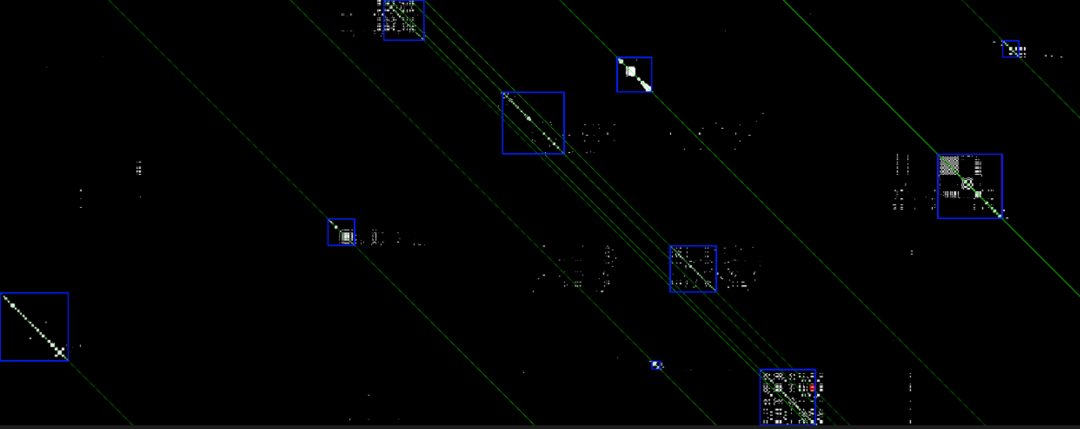
如上图所示,在获取候选的基础上,通过寻找最长的匹配序列,可以得到初步的匹配关系,即图中矩形框所代表的查询视频与注册视频匹配关系,并以此为基础进行过滤。考虑到损失矩阵中,匹配序列可能存在噪声的问题,可通过开闭操作、近邻序列合并等策略进行优化。另外视频序列匹配存在一对多匹配的现象,采用非极大值抑制可以较好的缓解这一问题。由于外部蓝色框的抑制,上图中红色框所代表的匹配关系将不会出现在最终的匹配结果中。
工程性能优化
视频撞车系统主要有两个计算密集模块——特征提取和向量检索。特征提取包含模型推理、视频解码、图像预处理、音频特征提取等过程,向量检索又包含了粗排和精排两个阶段。经过我们的优化,模型效果基本对齐baseline,同时单个视频端到端处理速度提升3倍多,99分位提升十多倍,优化效果显著。
模型推理
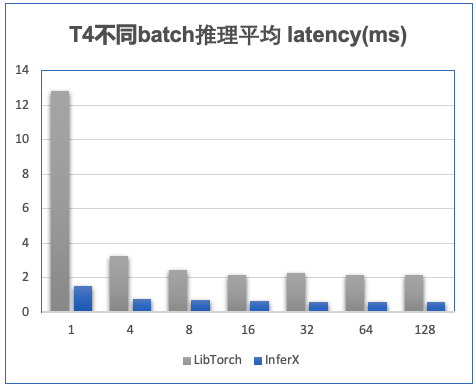
借助部门自研InferX推理框架,视频撞车的模型(ResNet50)推理相比较LibTorch部署方案在Volta及之后架构的NVIDIA GPU上均有5倍以上加速效果,T4单卡推理QPS超过2000,并且能够支持更大batch size。我们测试在T4上使用LibTorch进行推理当batch size增大到128时就会出现GPU OOM,而使用InferX进行推理仅需占用2G显存。我们发现LibTorch在显存管理上做得不太好,在使用LibTorch推理时可以通过减少中间变量或使用混合精度来降低显存占用。
视频解码
由于模型推理速度非常快,撞车系统链路主要耗时分布在其他CPU处理上,视频解码便是其中耗时占比最高的环节之一。我们基于NvCodec SDK开发了通用的GPU视频解码库,输入视频路径/链接,输出torch CUDA Tensor,Layout支持CHW/HWC,可以直接用于后续GPU计算,避免了显存和内存之间的memory copy,实现端到端的All GPU处理方案。解码库以视频路径/链接作为输入,首先调用ffmpeg对视频进行解封装得到码流,再调用CUVID API使用NVIDIA GPU的硬件解码器对视频进行解码,最后再编写CUDA Kernel实现色彩空间转换,如YUV->RGB。为了使得解码库更通用,我们使用CUDA实现了多种转换kernel,如NV12向three-plane YUV420的转换模版等。由于色彩空间转换使用CUDA kernel实现,因此执行时会占用少量流处理器进行计算,可能会影响其他并行执行的GPU计算速度,使用中我们发现一般对GPU占用率小于10%。完成RGB转换后,可以选择性进行Layout重排,提供所需的torch CUDA Tensor作为输出。此外,考虑到某些使用场景下解码服务和模型服务可能分布在不同节点,我们也基于NvJPEG支持了视频解码后帧以jpeg编码格式输出,方便用于网络传输。解码库使用Pybind11同时封装Python接口,更加方便与其他模块对接使用。
图像预处理
撞车系统的图像预处理过程除了常规的Resize, Normalize操作之外,还包含切黑边操作。切黑边算法是基于图像像素级统计信息来判断黑边位置,体现在计算上就是大量的规约操作, CPU实现速度非常慢。规约操作的GPU优化方式比较常规,使用warp shuffle实现线程束级规约、借助GPU共享内存加速线程块级规约、最后使用atomicAdd实现数据位于全局内存的线程网格规约,复杂的是针对不同形状的张量和规约维度实现特定的优化kernel。Resize操作可以直接使用torchvision的GPU版本,但不管使用哪种插值方式,直观上效果相对于Pillow会更差一些,主要原因是Pillow做了额外的平滑处理。为了实现Pillow的Resize操作,我们在采样之前也加入卷积滤波,使用torch卷积的GPU版本。Normalize操作计算量很小,直接使用torch操作实现,整个预处理均在GPU上执行。
音频特征提取
这里主要介绍音频浅层特征Log-FilterBank和MFCC计算加速方式。Log-FilterBank计算步骤为:输入波形->预加重->分帧、加窗->能量谱->梅尔滤波->差分->标准差,取梅尔滤波取log后的fbank特征,将对数能量带入离散余弦变换,求出L阶的Mel-scale Cepstrum参数。同样进行差分、标准差,得到最终MFCC特征。线上原始Base版本使用python_speech_features包计算音频特征,我们基于C++使用vectorize, unroll, tile, parallelize等一些常规优化手段增强代码实现的局部性,使用memory pool实现内存复用,选择更高效的内存排布方式,借助intel mkl fft将信号转换为频域计算能量谱,借助intel mkl GEMM计算filter bank和能量谱矩阵乘, 借助intel mkl fftw3实现DCT及BatchDCT,整体加速效果相比较python版本提升10倍。如果需要对其进一步进行GPU优化, GEMM, FFT, DCT这些操作可以直接调用CuBlAS, CuFFT实现,CuBLAS在大多数场景下都有比较好的性能,如果运行在拥有Tensor Core的GPU卡上,还可以使用CUTLASS或者直接使用low-level的WMMA API来更精细化地加速混合精度GEMM计算,它们相比已经编译好的库CuBLAS拥有更好的灵活性。最后,其他一些计算均可以通过编写CUDA kernel来实现,例如预加重就很适合线程束shuffle指令__shfl_down_sync来实现。
检索
视频撞车系统的索引库规模达到数十亿级别。这里我们主要基于faiss构建分布式向量检索系统,对索引分片以方便扩展支持更大规模数据,增加副本数来支持更高QPS。由于latency能满足需求,因此目前索引部署在CPU机器上,一些优化策略主要在算法侧进行。这块的GPU优化手段第一步可以考虑针对Volta及之后架构借助Tensor Core使用fp16精度计算,在加速计算同时也能节省显存;进一步可以考虑基于哈希学习的方法量化为二值编码,在可以容忍损失一部分精度前提下将浮点乘加操作转换成异或和popcnt,由于哈希编码之间的距离在有限的整数范围内,topk阶段可以简单使用基数排序。也可以先使用直方图统计筛选出距离topk,再对topk内距离进行排序,能够进一步降低排序计算量。上述topk、基数排序、直方图统计在并行计算领域是比较经典的问题,很容易用CUDA高效实现。这种方法中哈希学习可以采用有监督学习,以pairwise-loss或ranking-loss作为损失函数,量化误差并不像简单的二值量化一样一成不变,而是可以通过训练来降低。此外哈希编码极致地压缩了内存/显存占用,特征向量的32位哈希编码仅需1个float32存储空间,使得在一块普通16G显存的GPU中进行数十亿规模特征的向量相似度检索成为可能。
成果总结
本项目历时两年多,对比2020年时的baseline,撞车视频打回量提升约7.5倍,召回率提升约3.75倍,提示量上升至基线的1.7倍,业务准确率为基线的2.2倍,模型准确率约为88%。人审发现的机审漏召从日均65个降低至日均5个,为基线的十三分之一。目前该查重系统已为B站安全问题撞车审核、版权机审、高危图像视频回扫、同屏推荐去重等业务提供服务。后续将持续对检索效率、检索质量进行工程性能、与算法准召指标的优化。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。