
内容摘要:最近,视频的图像隐含神经表示法 NeRV 因其有希望的结果和比常规像素隐含表示法迅速的速度而受到欢迎。然而,网络结构中的冗余参数会导致在扩展时出现较大的模型尺寸,以获得理想的性能。这种现象的关键原因是 NeRV 的耦合表述,它直接从帧索引输入中输出视频帧的空间和时间信息。在本文中,我们提出了 E-NeRV,它通过将图像上的隐性神经表征分解为独立的空间和时间背景,极大地加快了 NeRV 的速度。在这种新的表述方式的指导下,我们的模型大大减少了冗余的模型参数,同时保留了表示能力。我们通过实验发现,我们的方法可以在较少的参数下很大程度上提高性能,从而使收敛速度提高了 8 倍以上。
作者:Zizhang Li, Mengmeng Wang, Huaijin Pi , Kechun Xu , Jianbiao Mei, and Yong Liu
论文地址:https://arxiv.org/abs/2207.08132
代码地址:https://github.com/kyleleey/E-NeRV
整理人:何冰
视频的隐式神经表示
位置编码技术的提出使得神经网络展现出了能够拟合高频信息的能力,于是有了各种使用神经网络过拟合视觉信息的工作。其中视觉信息包含图像,视频,以及 3D 场景。NeRV 系列工作被应用于视频压缩,并引起了比较广泛的关注。NeRV 系列工作中,网络的输入为时间坐标,经过位置编码后,输入 MLP 以及卷积层,最终还原输入时间对应帧的图像。
隐式神经表示将传统的,多步骤的编码流程转换为可端到端训练的神经网络过拟合的过程,将图像的压缩问题转化为神经网络的压缩问题。尽管在编码速度上依然远远落后于传统的实用编码器,但其压缩性能展现的潜力已引起了较为广泛的关注,或可作为日后离线压缩的替代方案。
NeRV 工作
为使得读者更便于理解 NeRV 系列的工作内容,以及本工作的创新处,本文将简单回顾 NeRV 中所使用的技术。
使用神经网络过拟合某一场景的数学形式可以写为如下公式:

由于卷积神经网络更易于学到图像信息,相比于前人的像素级别神经网络的结构,NeRV 工作实现了更短的编解码时间,以及更高的视频图像重建质量。
本文工作
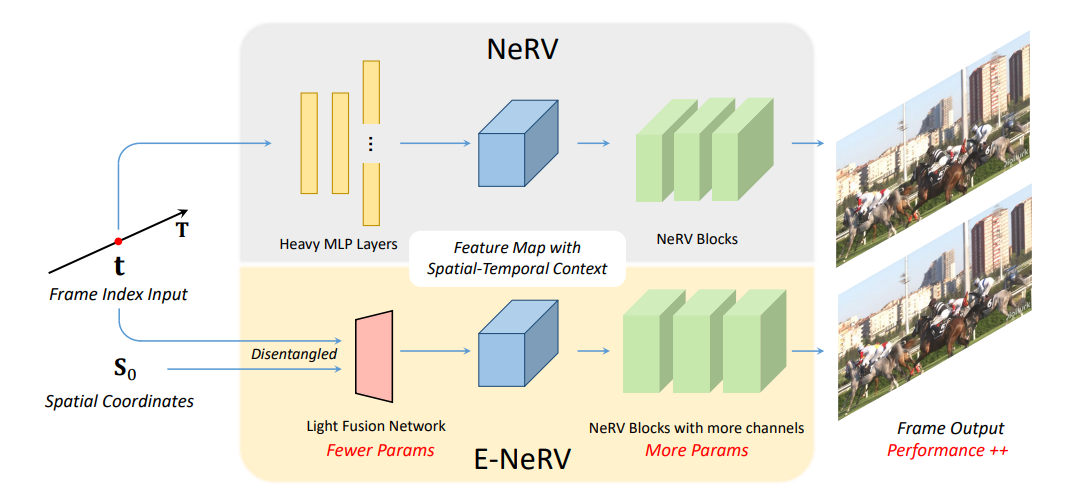
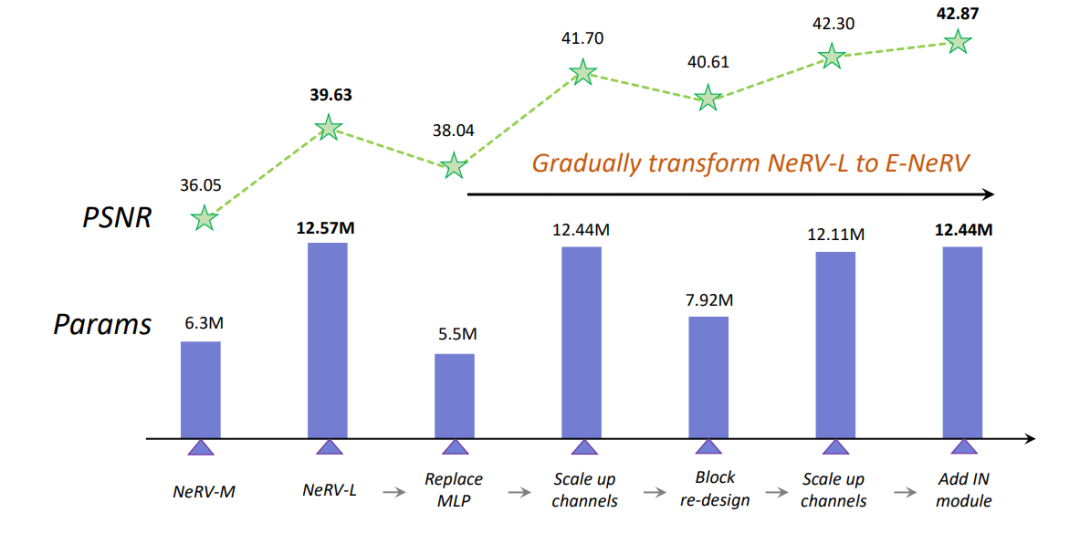
本文分析了 NeRV 模型中的参数分布,发现其 MLP 的参数量是偏重的,七成的参数量来自于 MLP 的最后一层,并且视频图像其实是时间信息与空间信息的耦合,然而 NeRV 中只提供了时间信息输入的通道。因此作者在工作中提出了名为 E-NeRV 的模型结构,在输入端既输入时间信息,也输入空间坐标信息,并使用一个比较小的 attention 层耦合时空信息,将更多的参数量留给表达能力更强的卷积层,最终达到了更好的表达效果。
模型详细介绍
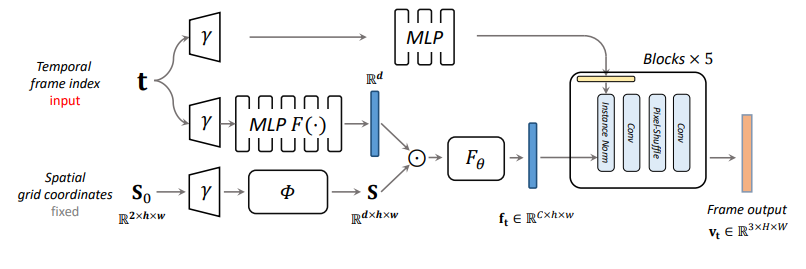
具体而言,本文的模型如图 2 所示,其中 均为位置编码模块, 为一个小的单头自注意层,并且使用残差连接,这一结构是为鼓励特征在空域上的融合,后面的 是多头注意力层,用于时空特征信息的融合。
IN 结构的引入
NeRV 工作中时间仅有一条路径可以进入模型中,本文作者受到 GAN 工作的启发,将时间信息单独通过一个小的 MLP 输入至每个升采样块中,作为输入该层块的特征数据的均值和方差的偏移。

块结构改变
在 block 结构上,E-NeRV 也做了一些改进。在 NeRV 中,每个网络块结构如下:

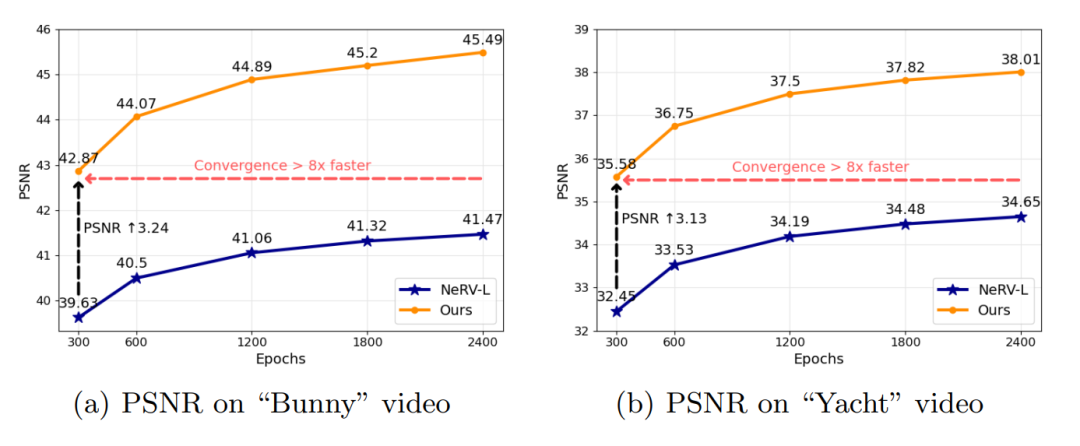
实验结果

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
