
神经体积渲染使得在自由视角下进行逼真的人体表现成为沉浸式 VR / AR 应用的关键任务,但是渲染过程中的高计算成本限制了其实际应用。为解决这一问题,作者提出了一种新的方法,称为“ UV 体积 ”,它能够实时渲染人体表演者的可编辑自由视角视频。该方法将高频(即非平滑)人类外观与 3D 体积分离,并将它们编码为 2D 神经纹理栈(NTS)。平滑的 UV 体积可以使用更小、更浅的神经网络来获取 3D 密度和纹理坐标,同时在 2D NTS 中捕捉详细的外观信息。为了实现可编辑性,参数化人体模型与平滑的纹理坐标之间的映射允许作者更好地推广到新的姿势和形状。此外,使用 NTS 还可以实现有趣的应用,例如修改纹理。在CMU Panoptic、ZJU Mocap和H36M数据集上的大量实验表明,本模型可以以平均30FPS的速度渲染 960×540 像素的图像,并且具有与最先进方法相媲美的逼真度。
来源:CVPR 2023
原标题:UV Volumes for Real-time Rendering of Editable Free-view Human Performance
作者:Yue Chen, Xuan Wang, Xingyu Chen, Qi Zhang
链接:https://arxiv.org/pdf/2203.14402
内容整理:王彦竣
引言
在计算机视觉领域中,生成一个运动人类的自由视角视频一直是一个长期存在的问题。早期的方法依赖于多视角立体视觉获取精确的三维网格序列。然而,计算出的三维网格往往无法描绘出复杂的几何结构,导致视觉效果受限。近年来,使用体积表示和可微分光线投射的方法(如 NeRF )在新视角合成方面表现出了很好的结果。这些技术已经进一步扩展到处理动态场景。
然而,NeRF 及其变种需要对深度多层感知器( MLP )进行大量的查询。这种耗时的计算使得它们难以应用于需要高渲染效率的应用程序。对于静态的 NeRF ,已经有一些方法已经实现了实时性能。然而,对于动态的 NeRF ,尚缺乏能够实时渲染体积自由视角视频的解决方案。
本文提出了一种名为“ UV Volumes ”的新框架,可以生成可编辑的运动中人类表演者的自由视角视频,并实时渲染。具体而言,模型利用人体的预定义 UV 展开(例如 SMPL 或 densepose )来处理几何形状(带纹理坐标)和纹理两个分支。作者使用稀疏的三维卷积神经网络( CNN )将基于姿势 SMPL 模型的体素化和结构化潜在编码转换为三维特征体积,其中仅编码了平滑和视角无关的密度和 UV 坐标。为了提高渲染效率,作者使用浅层 MLP 解码密度,并通过体积渲染将特征集成到图像平面中。然后,图像平面中的每个特征都被单独转换为 UV 坐标。最后利用产生的 UV 坐标从一个姿势相关的神经纹理堆栈( NTS )中查询 RGB 值。该过程大大减少了对 MLP 的查询次数,并实现了实时渲染。
值得注意的是,所提出的框架中的 3D 体积只需要近似比较“平滑”的信号。如下图所示,RGB图像和相应的UV图像的幅度谱表明,UV 比 RGB 要平滑得多。也就是说,模型只在 3D 体积中建模低频密度的UV坐标,然后在 2D NTS 中详细描述外观,该 NTS 在不同姿势下也是空间对齐的。这种解耦也增强了这些模块的泛化能力,并支持各种编辑操作。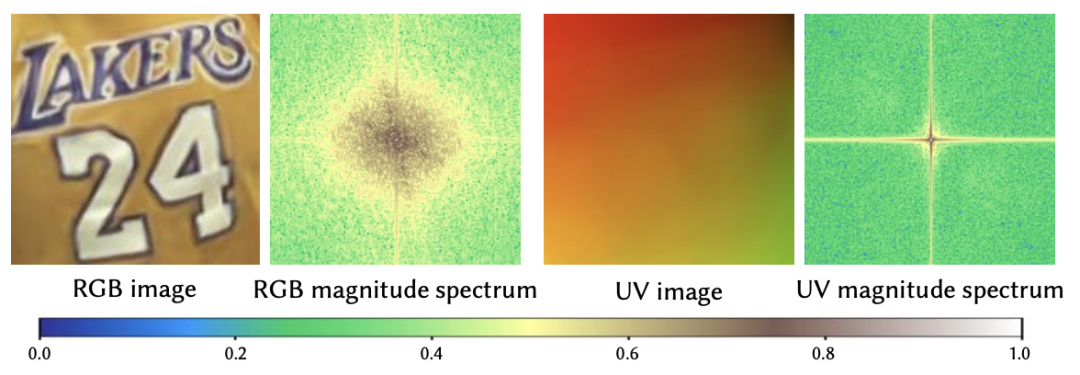
作者在三个广泛使用的数据集( CMU Panoptic ,ZJU Mocap 和 H36M 数据集)上进行了大量实验。结果表明,所提出的方法可以有效地从稠密和稀疏视角生成可编辑的自由视角视频。生成的自由视角视频可以实时渲染,并具有与高计算成本的最新方法相当的逼真度。总的来说,本文的主要贡献是:
- 提出了一种新颖的系统,可实时呈现可编辑的人体表演视频,支持自由视角。
- 提出的 UV Volumes 是一种能够在保留高频细节的同时加速渲染过程的方法。
- 该框架支持多种扩展编辑应用,例如姿势重定义、修改材质和修改体型等。
方法
该模型接受表演者的多视角视频,生成可编辑的自由视角视频,支持实时渲染。模型利用现成的 SMPL 模型和 Densepose 中预定义的 UV 坐标定义来将适当的先验知识引入框架。本节中详细描述了该框架的细节,如下图所示。该框架有两个主要分支。一个是生成UV体积 ,另一个是生成 NTS 。
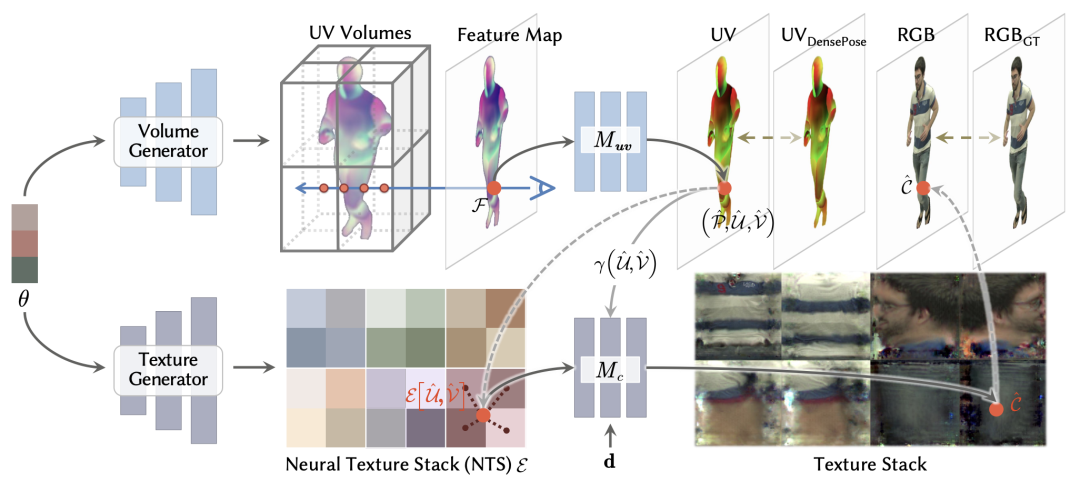
UV Volumes
神经辐射场已被证明能够生成具有视角一致性和高保真度的自由视点图像。然而,在动态场景中捕捉高保真度外观是耗时且困难的。为此,本文提出了 UV 体积,其中只编码密度和纹理坐标(即 UV 坐标),而不是人类外貌。通过使用 Densepose 中定义的 UV 展开,模型可以利用光线投射生成的 UV 图像从 2D NTS 中查询相应的 RGB 值。
模型利用体积生成器构建 UV 体积。首先,将 SMPL 模型上的与顶点对应的时不变隐编码(time-invariant latent codes) 体素化并作为输入。然后,使用 3D sparse CNN 将体素化的潜在编码编码成一个名为 UV 体积的 3D 特征体积,其中包含 UV 信息。

Neural Texture Stack
基于生成的 UV 图像,模型利用隐式神经表示编码的连续纹理堆栈来恢复彩色图像。为了提取神经纹理堆栈相对于人体姿态的局部关系,使用 CNN 纹理生成器 G 生成姿态相关的 NTS:

训练


作者将上述损失组合起来,共同训练该模型,以优化完整的目标函数:
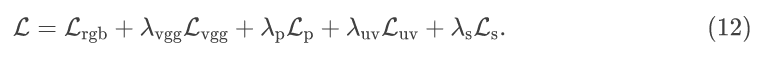

实验
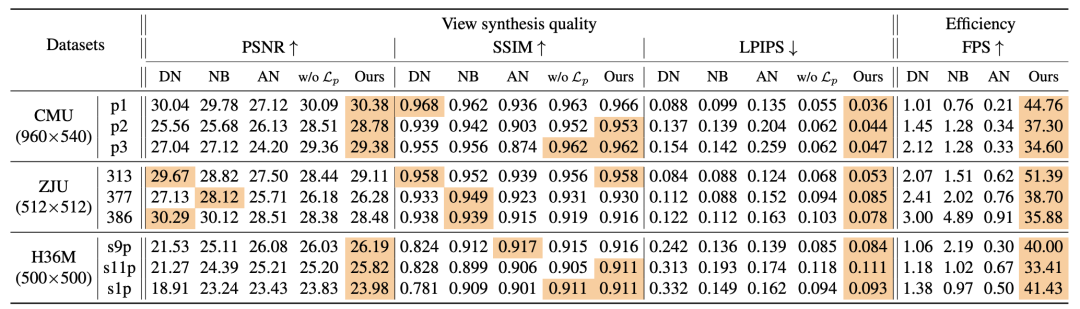
为了展示该方法的有效性和效率,作者进行了广泛的实验,并使用四个标准指标报告定量结果:PSNR 、 SSIM 、 LPIPS 和 FPS1。而定性实验进一步说明该方法在不同任务中产生了逼真的图像,例如新视角合成、姿势改变、形状改变和纹理改变。
下表显示了本方法与基线方法的比较,证明此方法在所有方法中表现出最佳的 LPIPS 和 FPS 。具体来说,模型借助 UV 体积实现了每秒 30 帧的人类表演自由视角视频的渲染。需要注意的是,LPIPS 与人类视觉感知较为一致,这表明该模型的合成更加接近真实。
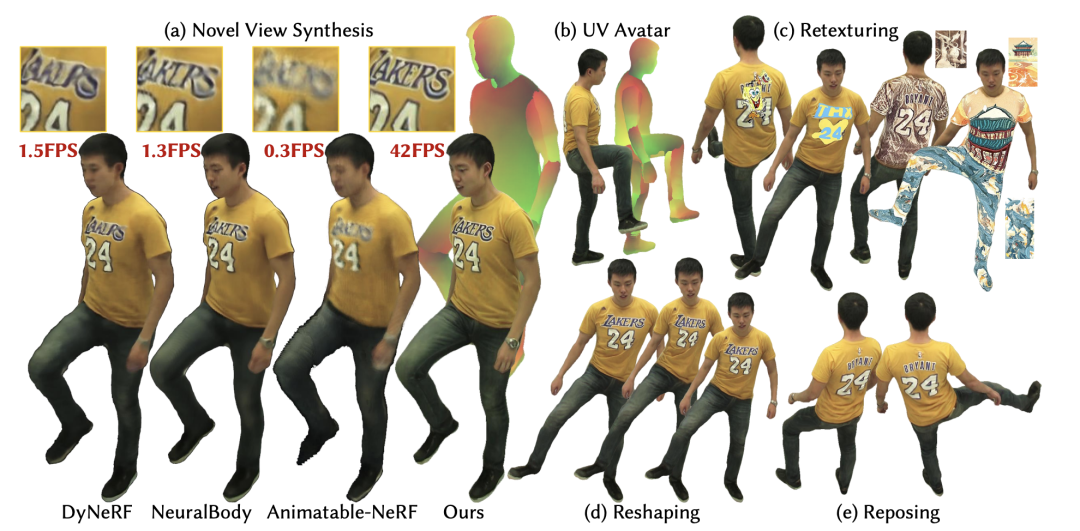
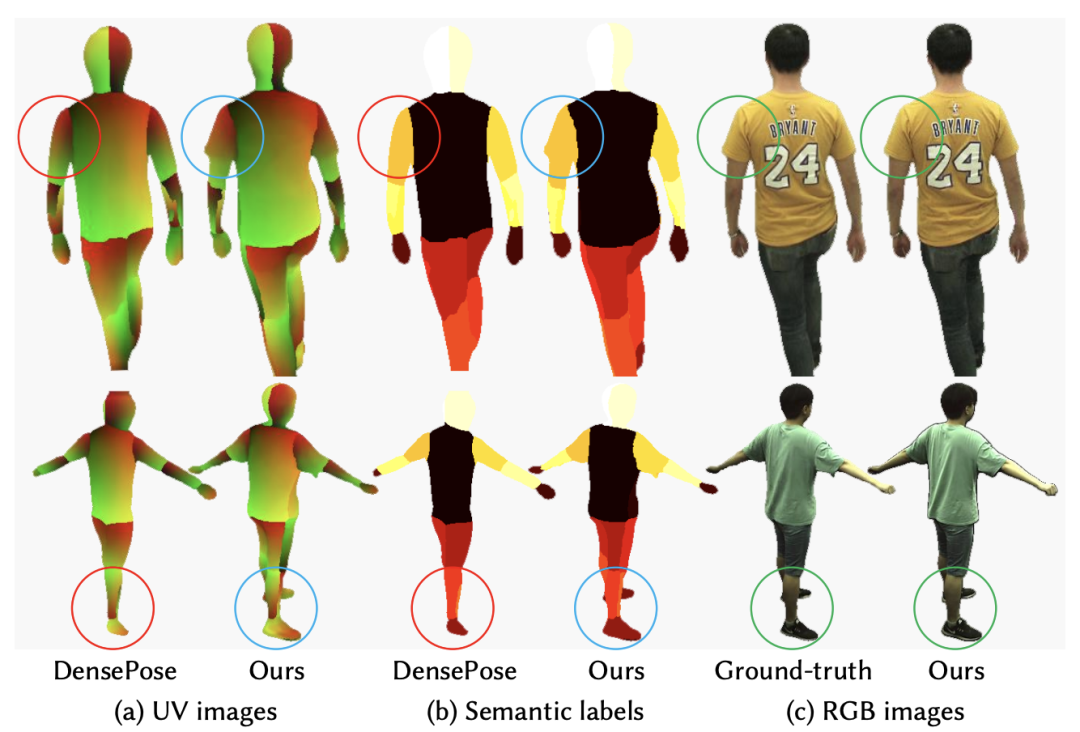
下图左边展示了该方法与基线方法的定性比较。基线方法无法保留清晰的图像细节,其渲染模糊甚至分裂。相比之下,此方法可以准确地捕捉高频细节,如衬衫上的字母、数字和皱纹,以及裤子上的皮带,这要归功于改的NTS模型。
下图右边显示了新姿势合成的效果,NeuralBody 生成的渲染结果模糊且失真,而 Animatable-NeRF 由于高度不受约束的观察到规范空间的后向扭曲场而产生分裂人体。相反,该方法合成的图像表现出更好的视觉质量,并具有合理的高清动态纹理。结果表明,使用光滑的三维 UV 体积和在二维中编码纹理比直接建模姿势条件的神经辐射场对新的姿势泛化具有更好的可控性。

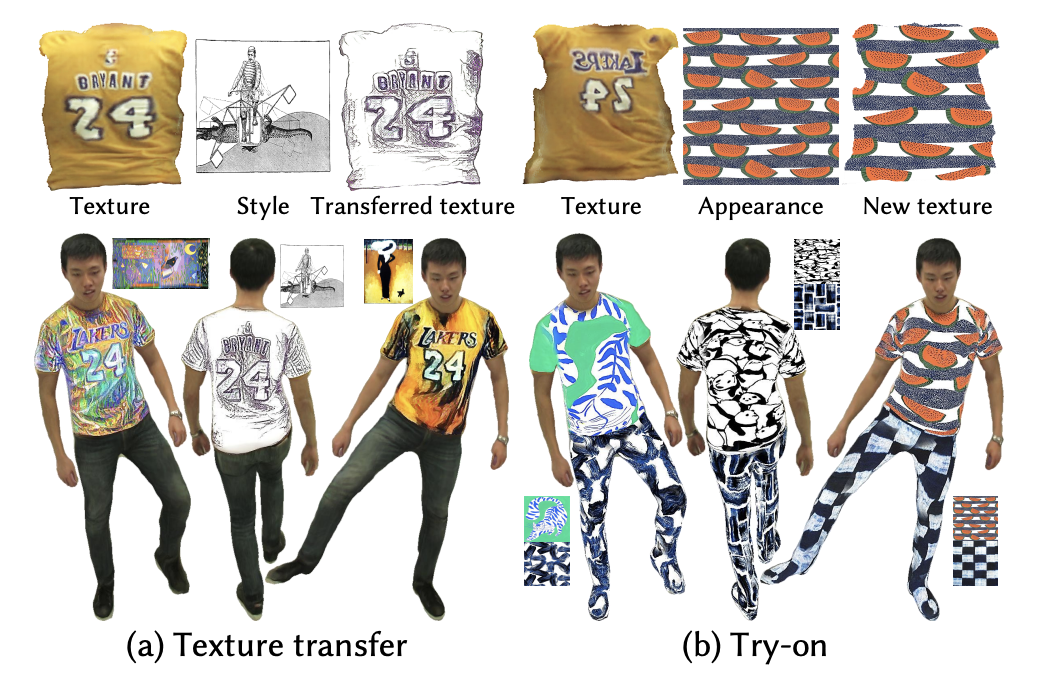
通过学习到的 UV 体积和神经纹理的密集对应关系,模型可以使用用户提供的 2D 纹理来编辑 3D 服装。如下图所示,模型支持改变纹理的风格和外观,如下图所示。通过样式转移网络,模型可以对 3D 人物表演进行任意艺术风格的编辑。给定任何面料纹理,甚至可以穿着不同的外观来进行 3D 虚拟试穿,从而实现实时编辑。
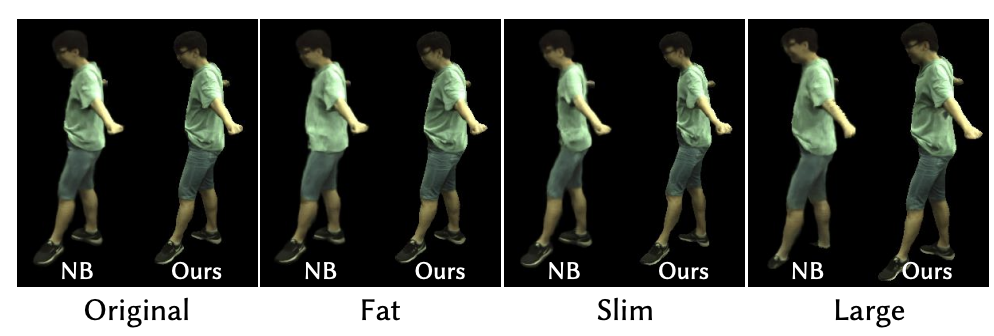
 最后下图展示了此方法可以通过改变S MPL 模型的形状参数来编辑重建的人类动作表现形式的形状。NeuralBody 无法推断出衣服的合理变化,而的方法在新形状上具有很好的泛化能力。
最后下图展示了此方法可以通过改变S MPL 模型的形状参数来编辑重建的人类动作表现形式的形状。NeuralBody 无法推断出衣服的合理变化,而的方法在新形状上具有很好的泛化能力。
总结
作者提出了一种使用 UV 体素进行人体自由视角视频合成的方法。这是第一种能够实时生成可编辑自由视角视频的方法。其关键是采用了平滑的 UV 体素和高精度的纹理在一个隐式神经纹理堆栈中。广泛的实验证明了该方法的有效性和高效性。除了提高效率,此方法还支持编辑,例如重新摆姿势、重塑或重贴人体表面的纹理等。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
