
阿里云窄带高清本质上是一种转码质量优化技术,是一套以“人眼主观感受最优”为基准的视频编码技术。研究的是在带宽受限的情况下,如何追求最佳的视觉感受,即人眼感受的主观质量最优。
视频画面质量提升往往需要使用合适的画质增强技术来实现。
“视频高清化”大趋势
视频是信息呈现和传播的主要载体。从早期的625线模拟电视信号,到后来的VCD、DVD、蓝光、超大尺寸电视等,用户对高品质画面无止境的追求推动着视频技术的不断进步和产业的蓬勃发展。据预测,未来个人消费者网络流量的80%以上和行业应用流量的70%以上都将是视频数据。
当下,随着视频拍摄和视频播放显示设备的软、硬件配置和性能不断升级,消费者对于视频画质的要求越来越高:从360p到720p再到1080p,现在正全面跃升至4K,并且8K的脚步正在逼近。
在视频娱乐场景中,视频画质是影响用户互动体验的关键因素,高清视频往往比低清视频包含更多的细节和信息,给用户的视频互动带来更好的体验,这也促使了用户对视频画质的要求越来越高。
视频消费者一旦适应了高清视频所带来和以往不一样的感受和体验,例如:高清视频可以将光线、质感、人物皮肤、纹理等细节还原得更为真实,对于“渣”画质的容忍度就会越来越低。
作为创新的排头兵,互联网视频网站正拿出各种应对手段满足消费者的需求,提升画质俨然成为视频网站争取IP之外的新战场。
当下,国内外主流的视频网站、APP已经全面普及1080p,1080p已经成为一种标配。一些视频平台,例如爱优腾、B站、YouTube,部分节目内容也提供了4K版本。
助力“最后一公里”的画质优化
视频从采集到分发再到终端消费者进行播放观看,中间要经历复杂的视频处理和传输链路。完整的处理和传输链路通常包括以下几个环节:
- 采集/编码:内容提供方采集的视频首先会被编码为特定的格式;
- 编辑/剪辑/重编码:对原始素材进行多样化的编辑/剪辑操作,进行二次创作,然后重编码输出;有的业务场景可能会包含多次剪辑处理;剪辑/编码完成的视频会被上传至服务端;
- 云服务端转码:视频在上传到云服务器后,为适应不同的网络环境和播放终端通常会在云端进行转码(本文所讨论的窄带高清转码即发生在该环节,以更高的压缩比呈现更高质量的视频);
- 云发布:内容分发网络(CDN);
- 播放端:视频经由内容分发网络(CDN)加速分发,通过解码最终在内容消费方的终端设备上实现播放;
- 多平台播放:手机,Pad,OTT,IPTV,Web;
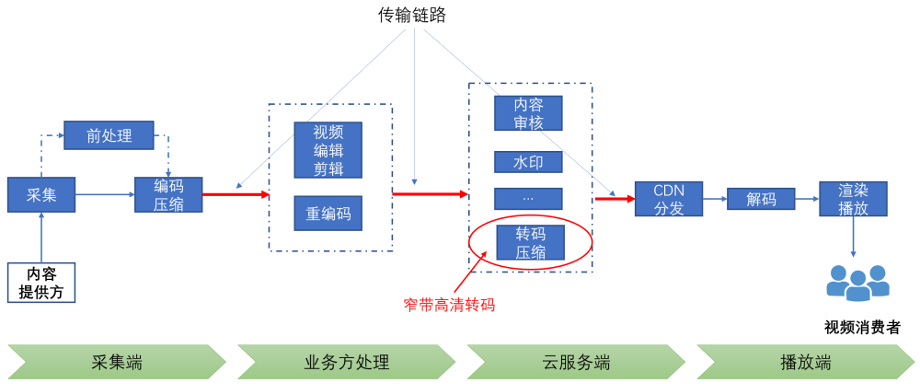
图1 视频处理和传输链路
从视频处理角度来看,窄带高清云转码是视频内容触达终端消费者的最后一个处理环节;从客观现实上来说,是视频内容生产消费全链路的“最后一公里”。
从传输角度来看,在视频生产和消费全链路,各环节之间数据的流转有多种形式:SDI有线线缆方式、无线蜂窝移动通信、互联网以及卫星通信等。
不同数据传输方案在传输环境稳定性和带宽存在巨大的差异,因此,为了能在带宽受限的链路上进行稳定的视频传输,必然要对视频信号进行深度编码压缩,而编码压缩势必会带来不同程度的画质损伤。
举个例子:常见的视频流规格:1080p, 60 fps, YUV 4:2:0, 8-bit,raw data码率为192010801.5860 = 1.49Gbps
上述提到的传输方式中,只有3G-SDI有线线缆可支撑该码流的实时传输。而视频内容触达终端消费者的方式一般是经由互联网进行分发,码率需要控制在10Mbps以下,因此意味要将原始视频压缩上百倍。
综上所述,从整个视频处理和传输链路来看,视频内容从采集到终端播放,要经历多个视频编辑、处理、重编码的操作。而每一次处理/编码操作或多或少都会对视频的画质产生影响,通常会损伤画质。
因此,当下即便是使用最新的视频采集设备(可以输出高画质的原始视频信号),终端消费者侧也不一定保证能体验到高画质,原因就在于中间处理环节的画质损耗。
窄带高清云转码作为整个视频处理链路的最后一个处理环节,其输出码流画质效果即为最终分发至终端消费者的画质效果。因此,如果在该环节使用恰当的画质增强技术,可以一定程度上弥补前序视频处理环节所产生的画质损伤,起到优化画质的作用。
画质增强应该优先解决什么问题?
视频画质增强技术大致可以分为三大类:
- 色彩/亮度/对比度维度增强:色彩增强(色域,位深,HDR高动态范围)、去雾、低光照/暗光增强等;
- 时域维度帧率增强:视频帧率变换/智能插帧;
- 空域维度细节复原/增强:去压缩失真、分辨率倍增、降噪/去划痕/去亮斑、去闪烁、去模糊、去抖等。
视频增强技术在产品落地层面,目前比较热门的选择是将老旧视频素材高清化,例如年代比较久远的电影、电视剧、动画片和MV/演唱会视频等。
老旧影视素材普遍存在:划痕、噪点/霉斑、闪烁、细节模糊、运动拖尾、色彩暗淡或者只有黑白等问题,可以通过去噪、去脏点/划痕/霉斑、去模糊、去闪烁、分辨率/帧率倍增以及色彩增强(黑白上色)等处理,这样可以全面提升素材的整体观感。
然而,由于每个老旧素材所面临的画质问题差异很大,且目前的技术水平对于有的画质问题还难以给出令人满意的效果,因此老旧素材高清化处理过程必须引入人工干预。
人工干预体现在两个方面:一是对老旧素材画质问题进行诊断,并配置恰当的处理模型和处理流程;二则是对模型处理结果进行人工审查,并做适当的精修和微调。
窄带高清画质增强技术落地选择原则
窄带高清云转码作为一种全自动,无人工干预的视频转码作业,所采用的视频画质增强优化技术也需要做到全自动,无需人工参与。我们认为在选择产品化方向时,所集成的视频增强技术应该满足以下几个条件:
- 视频增强技术可以实现全自动,无需人工干预:老旧素材高清化目前还需要太多的人工干预,不符合该原则;
- 相关技术具有广泛的适用范围:低光照/暗光增强和视频去抖在部分场景也有需求,但在视频转码场景,有这类画质问题的视频占比非常少;
- 持续的刚需:该技术可带来消费者可感知的画质提升,且其解决的问题在未来5-10年都会持续存在,因此可以形成持续的刚需。
解决生产链路引入的画质损失
根据上述原则,我们最终选择在窄带高清转码中集成的画质增强技术为:空间维度细节修复,解决视频生产链路产生的画质损失,即多次编码压缩导致的画质损失。
从整个视频处理和传输链路来看,我们再具体分析一下产生画质损失的环节有哪些:
1.信号源本身的画质问题
- 传输链路导致的低码率:在视频生产流程中,传输链路的带宽通常有一定的限制,为了优先保证流畅,不得不采用低码率。典型场景有:跨国境直播流;大型赛事活动现场信号远距离传输,无专线保障;以及无人机航拍实时信号。典型的码率设置例如1080p 50fps 4-6M,直播场景通常是硬件编码,输出的码流有明显的编码压缩损失;
- 内容版权/商业模式导致的低码率:由于视频版权或者商业模式问题,视频版权方给到分发渠道只有低码率信号源;
- 原始视频素材经历过多次编码压缩,已经有明显的画质损失问题。

图2 低码率信号源画质问题:有明显的编码块效应
2.编辑/剪辑及二次创作引入的画质问题
剪辑软件编码压缩引入的画质问题。在UGC短视频领域,大家通常习惯使用手机剪辑APP来进行视频剪辑,剪辑APP会调用手机硬件编码来做完成渲染视频的编码输出;但手机的视频编码能力比较受限,且不同型号手机的编码压缩性能差异很大,因此很容易出现编码压缩后画质不好的情况,即便输出码率高达20M@1080p,如下图;
推流工具重编码压缩引入的画质问题。在一些业务场景,例如网红博主陪你看球,演播室或者解说主播会将原始信号流通过OBS拉流到本地,叠加解说,再推流上云;OBS的重编码会再次损伤原始视频的画质。

图3 UGC短视频,剪辑软件输出视频码率20M,分辨率1920×1080,画面存在明显编码块效应和模糊
图4 主播解说,OBS推流码率6M,分辨率1920×1080
画面存在大量编码压缩导致的边缘锯齿/毛刺,以及模糊从需求持续时间来看,由于传输带宽的限制,在整个视频生成流程中,视频编码压缩是一个无法避免的处理操作,而有压缩就不可避免引入画质损伤,因此,面向编码压缩损失的画质提升会是一种持续性的需求。
面向编码压缩损失的画质增强技术
从学术的角度来看,解决生产链路引入的画质损失,主要研究的技术包括:去压缩失真以及超分辨率重建。去压缩失真主要解决编码压缩导致的块效应,例如边缘毛刺和细节丢失/模糊问题;超分辨率重建可以消除处理链路中可能引入的空间分辨率降采样,并提升画面整体锐度和清晰度。
学术界对图像超分辨率重建技术的研究已经持续了几十年。早期的方法大多基于空域/时域重构技术,后来发展到基于样例的学习方法,比较有代表性的方案有:(1)基于图像自相似性的方法;(2)基于领域嵌入的方法;(3)基于字典学习/稀疏表示的方法;(4)基于随机森林等。但直到基于卷积神经网络(CNN)的超分辨率技术兴起,才让该项技术在处理效果和性能方面达到可商用的水平,从而在工业界得到广泛关注和应用。
第一个将基于CNN的图像/视频超分辨率技术进行产品化落地尝试的当属一家叫Magic Pony的创业公司。该公司在CVPR 2016上做了一个当时非常炫酷的demo – Real-Time Image and Video Super-Resolution on Mobile, Desktop and in the Browser [1, 3]。
第一次将基于CNN的视频超分辨率技术移植到了移动平台(三星手机和iPad),可以对游戏直播画面进行实时的超分辨率增强处理,显著提升源流的画质。该项技术很快引起了Twitter的关注,并在很短的时间内就完成了对该公司的收购 [2]。
而后,随着第一届NTIRE超分辨率比赛 – NTIRE 2017 Challenge on Single Image Super-Resolution [4]的举办,越来越多的公司开始关注基于CNN的图像超分辨率技术,从那之后,这方面的落地应用也如雨后春笋般地涌现。
常规CNN去压缩失真处理:这个面部有点假
虽然基于CNN的图像超分辨率技术可取得远超过往技术的处理效果,但其产品化过程还是存在不少问题。一个典型的问题是:基于MSE/SSIM损失函数训练得到CNN超分辨率模型(也即常规CNN超分辨率模型),重建生成的图像往往会缺少高频细节信息,从而显得过平滑,主观感受不佳。
下面三个例子为一个典型的常规CNN超分辨率模型达到的处理效果:
常规CNN超分辨率模型对编码压缩造成的块效应、边缘锯齿、毛刺等artifacts有比较好的平滑作用,从而使得整个画面看起来更加干净,但画面缺少细节和质感,主要体现在面部区域,有比较明显磨皮效应。因此,在对画面细节有要求的业务场景,例如PGC内容生产,用户通常会抱怨:面部磨皮太明显,有点假。




图5 常规CNN模型处理效果示范
处理之后编码artifacts被有效去除,画面比较干净平滑,但缺少细节和质感,例如:人像区域的头发/眉毛/胡子/皮肤颗粒感/嘴唇纹理等细节;地面草地纹理细节以及晚会节目视频中演员服装、道具细节丢失。
基于GAN的处理方案
为了解决常规CNN超分辨率模型缺乏细节、过平滑的问题,学术界在2017年提出了基于生成对抗网络(GAN)的超分辨率方案:超分辨率生成对抗网络(SRGAN)[5]。SRGAN在模型训练过程中,额外使用判别器对模型输出结果的纹理真实性进行鉴别,从而使得模型倾向输出具有一定细节纹理的结果。
如下图所示,基于MSE的模型倾向输出平滑的结果,而基于GAN的模型倾向输出有一定纹理细节的结果。
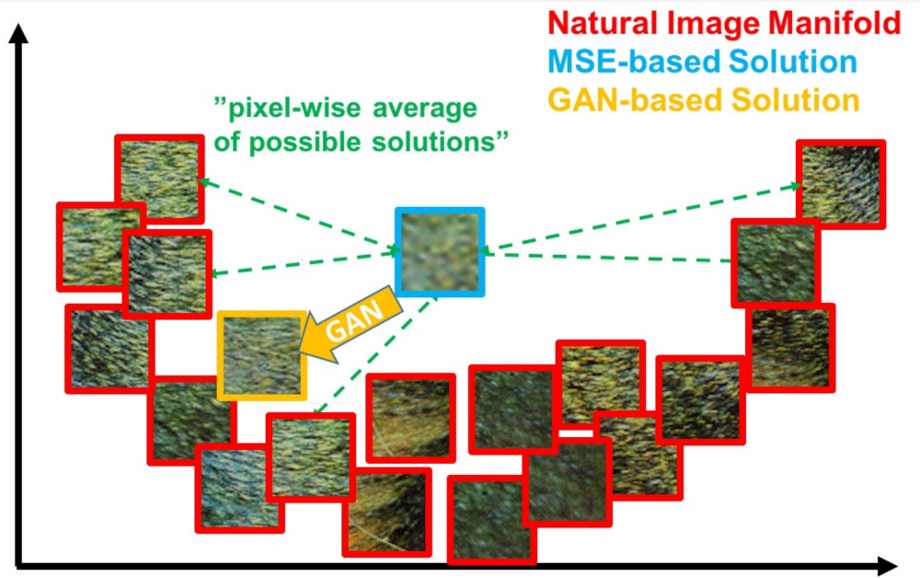 图6 基于GAN的SR方案来源:论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
图6 基于GAN的SR方案来源:论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
基于GAN的超分辨率模型具有“无中生有”生成细节的能力,因此可以补充原始画面缺失的纹理细节,这对解决常规CNN模型过平滑问题有很大的帮助。在SRGAN模型之后,学术界有不少工作对这一技术方向进行不断的完善[6, 7]。
窄带高清GAN细节生成技术:时域稳定的细节生成能力
然而,想要在实际业务场景中用好GAN生成技术,尤其是要在窄带高清全自动转码作业中应用该能力,技术实现层面还是有不少难点。
由于GAN的纹理细节是通过大量数据训练之后“脑补”出来的,那么“脑补”生成出来的细节纹理是否自然、与原始画面有没有违和感、相邻帧的生成结果是否具有一致性等,对该项技术能否在实际视频业务中成功应用至关重要。
具体来讲,要在窄带高清全自动转码作业中使用GAN生成能力,需要解决以下几个问题才能满足商用要求:
- 模型“脑补”生成的纹理自然,与原始画面没有违和感;
- 视频相邻帧的生成效果一致性高,连续播放无时域闪烁现象;
- 可应用于自动化处理流:模型对片源质量有良好的自适应能力,对不同画质损失程度不同的片源均有收益;
- 模型可适用于不同视频类型场景,例如影视剧,综艺,赛事,动画片等;
- 模型处理流程简单,处理耗时可预测、可控制(直播场景对处理效率有比较高的要求)。
阿里云视频云音视频算法团队经过对GAN生成技术持续的钻研,积累了多项GAN模型优化技术,解决了上述GAN细节生成能力商用落地的难点问题,打造了一个可应用于全自动转码作业的GAN细节生成方案。该方案的核心优势是:时域稳定的细节生成能力。
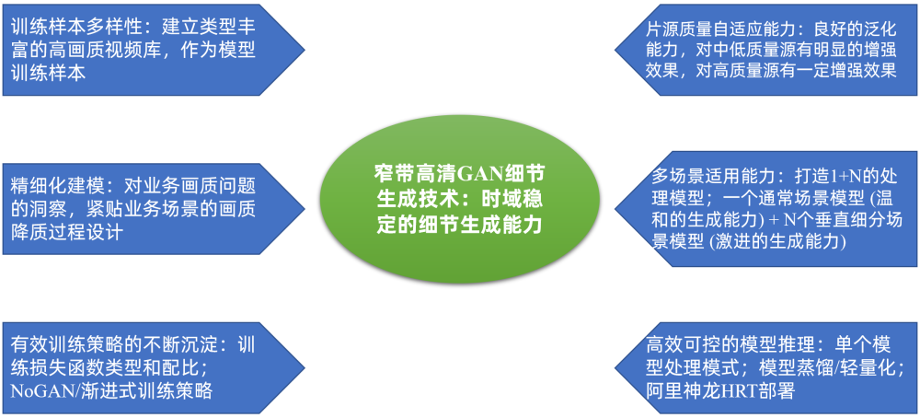
图7 阿里云窄带高清GAN细节生成技术
具体来讲,在窄带高清GAN细节生成模型的训练过程中,我们使用了以下优化技术。
1.建立类型丰富、清晰度高、细节丰富的高画质视频库作为模型训练的高清样本,训练样本包含多样的纹理特征对GAN生成纹理的真实感有很大的帮助;
2.通过精细化建模不断优化训练数据的制备过程:基于对业务场景所面临的画质问题的深入洞察,贴合业务场景不断优化训练样本建模方法,不断探索以达到精细化建模;
3.探索积累有效的模型训练策略:
损失函数:训练损失函数配置调优,例如perceptual loss使用不同layer的feature,会影响生成纹理的颗粒度,不同loss的权重配比,也会影响纹理生成的效果;
训练方式:我们在模型训练过程使用了一种叫NoGAN的训练策略 [8]。在图像/视频上色GAN模型训练中,NoGAN训练策略被证实是一种非常有效的训练技巧:一方面可以提升模型的处理效果,另外一方面对模型生成效果的稳定性也有帮助。
4.模型对片源质量的自适应能力决定了其是否可应用于自动化处理作业。为了提高模型对片源质量的自适应能力,我们在训练输入样本质量的多样性和训练流程方面做了很多工作。最终我们训练得到的GAN模型具有良好的片源质量自适应能力:对中低质量视频源具有明显的细节生成增强能力、对高质量片源有适中的增强效果;
5.打造多场景处理能力:根据学术界的经验,处理目标先验信息越明确,GAN的生成能力越强。例如将GAN技术用于人脸或者文字修复,由于其处理对象单一(高维空间中的一个低维流形),可以得到非常惊艳的修复效果;
因此,为了提升GAN对不同场景的处理效果,我们采用了一种「1+N」的处理模式:「1」为打造一个适用于通用场景的GAN生成模型,具有比较温和的生成能力;「N」为多个垂直细分场景,针对垂直细分场景,在通用场景模型基础之上,对该场景特有的纹理细节进行比较激进的生成,例如:对于足球赛事场景,模型对赛场草地纹理有更强的生成效果;对于动画片场景,模型对线条有更强的生成能力;对于综艺节目,舞台表演场景,模型对人像特写细节有更强的生成能力。特别注意:如下所述,对于特定目标的生成效果提升,我们并没有采用特定目标单独处理的方案;
6.计算复杂度可控可预测的处理模式:直播场景对处理模型的运行效率有很高的要求。为了适配直播画质增强的需求,当下,我们采用了单个模型处理模式,即:对全幅图像,统一使用单个模型进行处理。即便要对某些特定目标的生成效果进行针对性提升,例如人像区域及足球场地草地纹理,我们并没有采用将目标抠出来,单独处理的方案。
因此,我们的模型推理时间是可预测的,与图像内容无关。经过模型蒸馏、轻量化,基于阿里云神龙HRT GPU推理框架,我们的GAN细节生成模型在单卡NVIDIA Tesla V100上,处理效率可达60fps@1920×1080。
GAN生成时域稳定性保障技术
为了保证GAN模型生成效果的帧间一致性,以避免帧间不连续带来视觉上的闪烁,我们通过与高校合作的方式,提出一种即插即用的帧间一致性增强模型 – Temporal Consistency Refinement Network (TCRNet)。TCRNet的工作流程主要包含以下三个步骤:
- 对单帧GAN处理结果进行后处理,达到增强GAN处理结果的帧间一致性的同时,增强部分细节,改善视觉效果;
- 使用偏移迭代修正模块(Iterative Residual Refinement of Offset Module,IRRO)结合可变形卷积,提高帧间运动补偿精度;
- 使用ConvLSTM模块,使模型能够融合更长距离的时序信息。并通过可变形卷积对传递的时序信息进行空间运动补偿,防止由于偏移造成的信息融合误差。
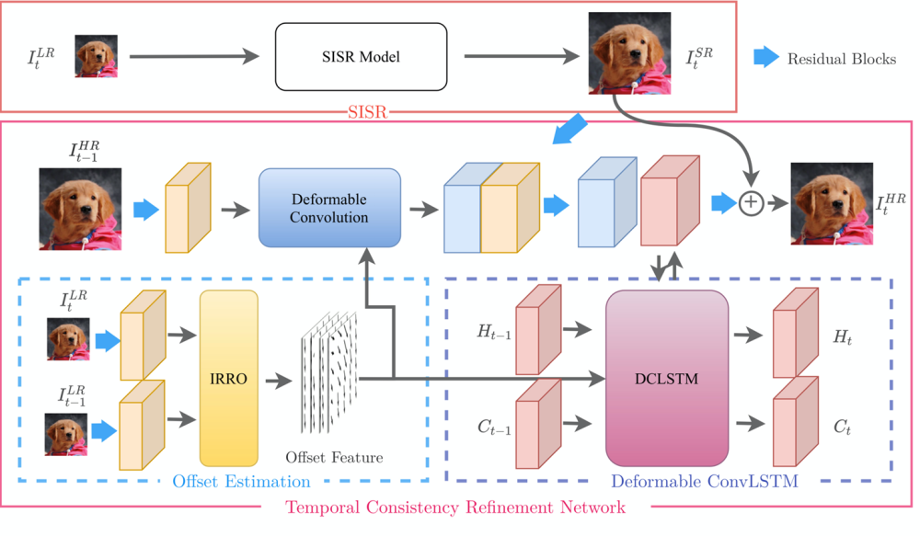
图8 TCRNet算法流程 来源:论文Deep Plug-and-Play Video Super-Resolution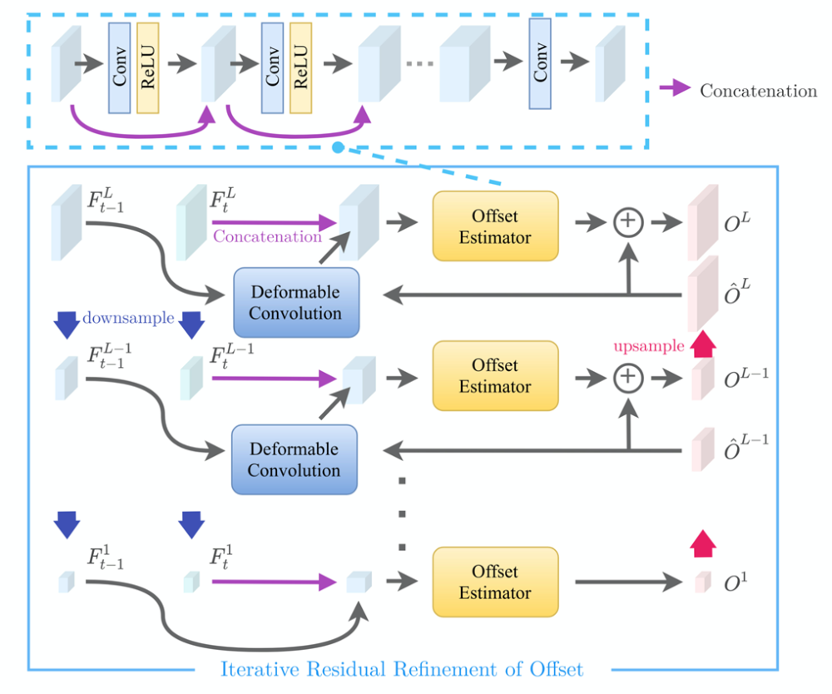
图9 偏移迭代修正模块(IRRO)算法流程 来源:论文Deep Plug-and-Play Video Super-Resolution
窄高GAN细节生成:面部效果还假吗?
回到前面提及的几个常规CNN处理效果例子,我们再来看看使用窄带高清GAN细节生成处理会有怎样不一样的结果。对于这些例子,我们使用通用场景模型进行处理,从左至右分别为:窄带高清GAN处理、输入原始帧、常规CNN处理效果。

图10 皮肤上有了颗粒感,有一种皮肤质感;头发,眉毛有了发丝的感觉;嘴唇纹理更丰富

图11 头发,胡子的细节更丰富,面部不会有磨皮感

图12 地面/草地纹理更丰富,细节更清晰

图13 左侧演员裙子纹理更丰富;
右侧演员道具纹理更丰富,细节更清晰
从左至右分别为:窄带高清GAN处理、输入原始帧。
图14 头发,胡子区域有明显的细节生成,纹理更丰富在前面我们提到,针对垂直细分场景,模型会对该场景特有的目标进行较为激进的纹理生成。例如对于足球赛事场景,模型对场地的草地纹理有更强的生成能力。下图是两个示例:从左至右分别为:窄带高清GAN处理、输入原始帧。


图15 足球赛事场景,草地纹理生成效果此外,对于动画片场景,我们也训练了一个针对性的GAN模型,聚焦在线条生成能力。下面为三个动画片的处理效果,从左至右分别为:窄带高清GAN处理、输入原始帧。


图16 动画片处理效果
窄带高清GAN细节生成技术商用
目前,窄带高清GAN细节生成能力已在百视TV NBA直播转码中全面启用。当观众用百视TV APP观看NBA比赛,选择“蓝光265”档位,就可以体验基于窄带高清GAN细节生成能力转码输出的画质。同时,百视TV在一些综艺节目和大型活动的直播中也使用了该功能。
此外,在FIFA2022世界杯转播中,江苏移动使用窄带高清GAN细节生成技术提升咪咕视频原始机顶盒分发流的画质。在为期一个月的赛事转播期间,窄带高清为江苏移动全天24小时不间断直播提供画质增强能力。
高分辨率、纹理丰富、细节清晰的视频能提供更清晰的画面和更高阶的感官体验,对于提升视频质量和用户视觉感受有很大的帮助。窄带高清GAN细节生成修复技术将持续在该领域不断探索,不断精进,打造极致的细节恢复和增强效果,为视频消费者提供优质的视频观看体验。
未来,窄带高清GAN细节生成能力将持续进行算法性能优化,提升细节生成和修复效果,同时不断降低处理成本。
更好!提升细节生成和修复效果,除了现在采用的GAN方案,基于扩散模型的细节生成技术也将是我们后续研究的重点方向;
更广!打造更多垂直细分场景,采用激进的生成策略提升相应场景的细节恢复效果;
更普惠!通过模型轻量化以及优化部署方案,持续降低处理成本,以普惠的价格服务更多的客户。
特别感谢以下同学对本文所涉及算法做出的贡献:佳芙、相泉、静瑶、岁曦、生辉、明烁。
演示视频高清版观看链接:https://www.yuque.com/chenyunjinximo/zg4swr/gpgwd5hs2qbulpxc
参考文献:
[1] https://cvpr2016.thecvf.com/program/demos
[2] https://www.gov.uk/government/news/magic-pony-technology-twitter-buys-start-up-for-150-million
[3] Wenzhe Shi et al., Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR 2016
[4] NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study, CVPRW 2017
[5] Christian Ledig et al., Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, CVPR 2017
[6] Kai Zhang et al., Designing a Practical Degradation Model for Deep Blind Image Super-Resolution, ICCV 2021
[7] Xintao Wang et al., Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data, ICCVW 2021
[8] https://www.fast.ai/posts/2019-05-03-decrappify.html#nogan-training
[9] Hannan Lu et al., Deep Plug-and-Play Video Super-Resolution, ECCVW 2020
兮墨|技术作者
IMMENSE|内容编辑
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
