
了解 H.264 的码流结构,以及这样设计的原因,编解码的过程就有了具体的依托。实际上 H.264 规范也是先规定了码流结构,再规定解码器的结构(对于编码器的结构和实现模式没有具体的规定),都是同样的道理。
H.264 码流结构
1、句法元素分层:
编码器输出的码流中,数据的基本单位是句法元素(可以理解为码流结构每一个基本字段),句法(Syntax)表征句法元素的组织结构,语义(Semantics)阐述句法元素的具体含义,所有的视频编码标准都是通过定义句法和语义来规范编码器工作流程的。
在 H.264 中,句法元素被组织成序列、图像、片、宏块(Macro Block, MB)、子块五个层次,如下图所示:
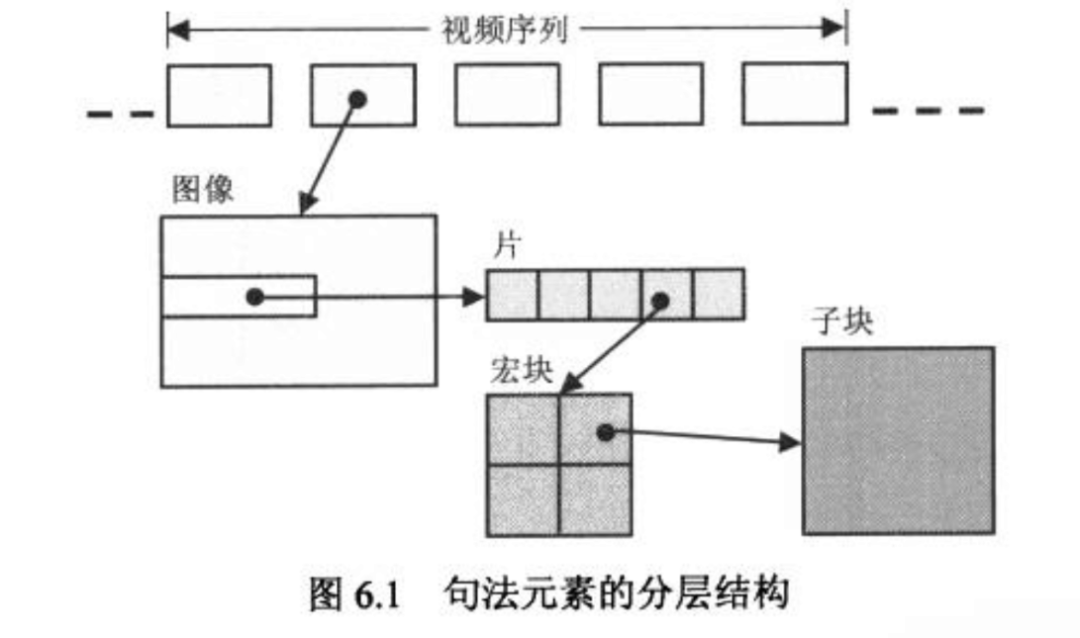

分层有利于节省码流,例如下一层中的共用信息可以在上一层保存,而不是每个下层结构都携带一份。但在 H.264 的分层结构中,各层数据组织并没有形成强依赖关系,这样有助于提高鲁棒性。因为分组交换容易出错,如果存在强依赖关系,一旦头部丢失,那后面的数据就无法使用了。
相较于以往标准,H.264 取消了序列层和图像层(概念上存在,但实际上取消了),把原本属于序列和图像头部的大部分句法元素抽离出来,形成了序列参数集(Sequence Parameter Set, SPS)和图像参数集(Picture Parameter Set, PPS),其余的句法元素则放入片层。参数集是独立的数据单位,不依赖参数集外的其他句法元素,它们可以单独传输、重点保护。
取消了序列层和图像层的分层结构及各层关系如下图所示:
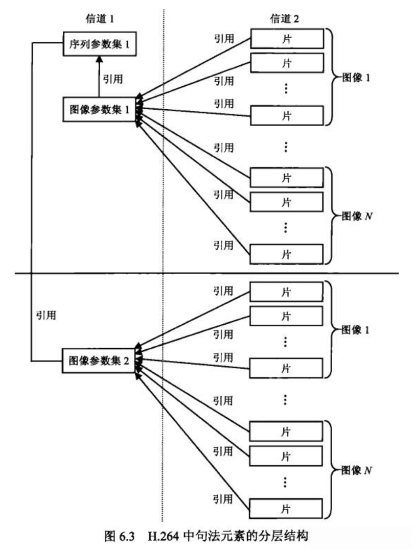
从上图中我们可以看到,一幅图像由多个片组成,片数据会引用 PPS,PPS 又会引用 SPS,而 PPS 和 SPS 可以单独传输,重点保护。
那片、宏块、子块这三层数据又是什么组织结构呢?请看下图:
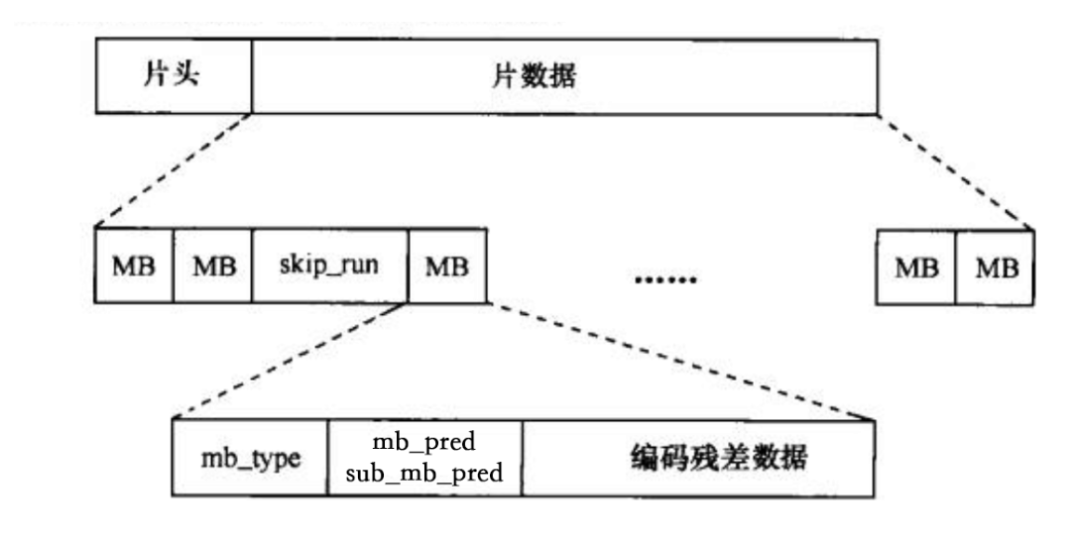
- skip_run:当图像采用帧间预测编码时,H.264 允许在图像平坦的区域使用“跳跃”块,“跳跃”块本身不携带任何数据,解码器通过周围已重建的宏块的数据来恢复“跳跃”块;
- mb_type 是宏块类型,例如 I 帧的宏块,P 帧的宏块(注:关于帧类型,可以搜索相关维基词条,关键词:I 帧,P 帧,B 帧,SP 帧,SI 帧);
- mb_pred 和 sub_mb_pred 是预测编码过程的预测信息,比如宏块如何划分,参考宏块的 id 等;
- 残差数据(resisual)则是预测编码过程中,预测块和本块数据之间的差值;
宏块是解码的基本单元,解码器根据预测信息和残差数据,进行解码。
2、功能分层:
除了句法元素的分层,H.264 功能上也分为两层:视频编码层(Video Coding Layer, VCL)和网络抽象层(Network Abstraction Layer, NAL)。VCL 数据即编码处理的输出,正是它被分为了上述的五层结构。VCL 数据在传输或存储之前,会先封装进 NAL 单元,每个 NAL 单元则分为原始字节序列负荷(Raw Byte Sequence Payload, RBSP)和描述 RBSP(即 VCL 数据)的头部。
在分组交换网络传输中,NAL 单元各自独立、完整地放入一个分组,因此 NAL 单元之间无需分隔符,但在磁盘存储时,NAL 单元连续存放,必须引入起始码来分隔 NAL 单元。这个起始码就是连续的三字节数据 0x000001,如果数据需要对其,则在起始码之前添加若干字节的 0 来填充。
为防止编码数据和起始码冲突,定义如下“防止竞争”(emulation prevention,其实就是转义)规则(00 被解码器作为 NAL 单元结束,01 被解码器作为 NAL 单元开始,03 用于转义,02 尚未使用):
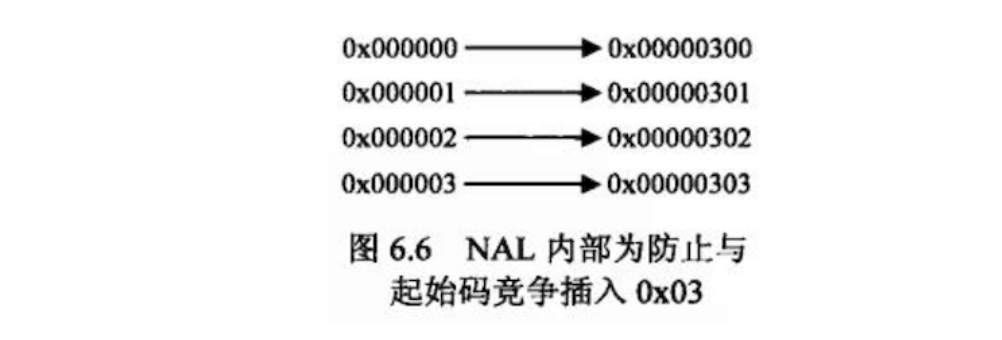
编码器编码后如果检测到这些转义前序列,就在最后一个字节前插入 0x03,解码器解码时如果检测到 0x000003,就把最后的 0x03 丢弃。有了上面的转义规则后,解码器就可以把 0x000001 之后到 0x000000 之前的数据作为一个 NAL 数据单元了。
NAL 单元的结构如下图所示:
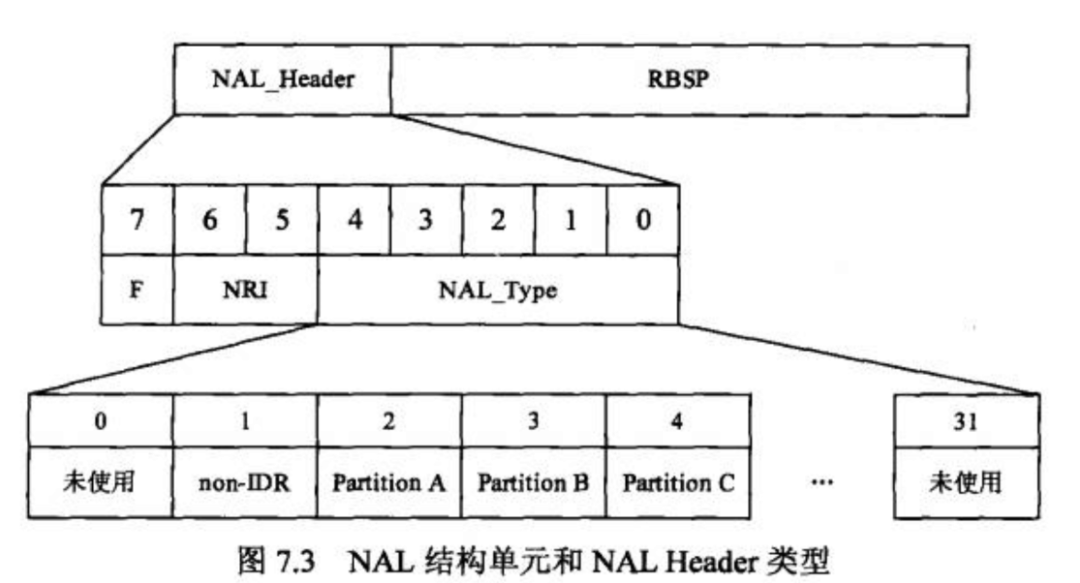
其中 NAL 类型定义如下:
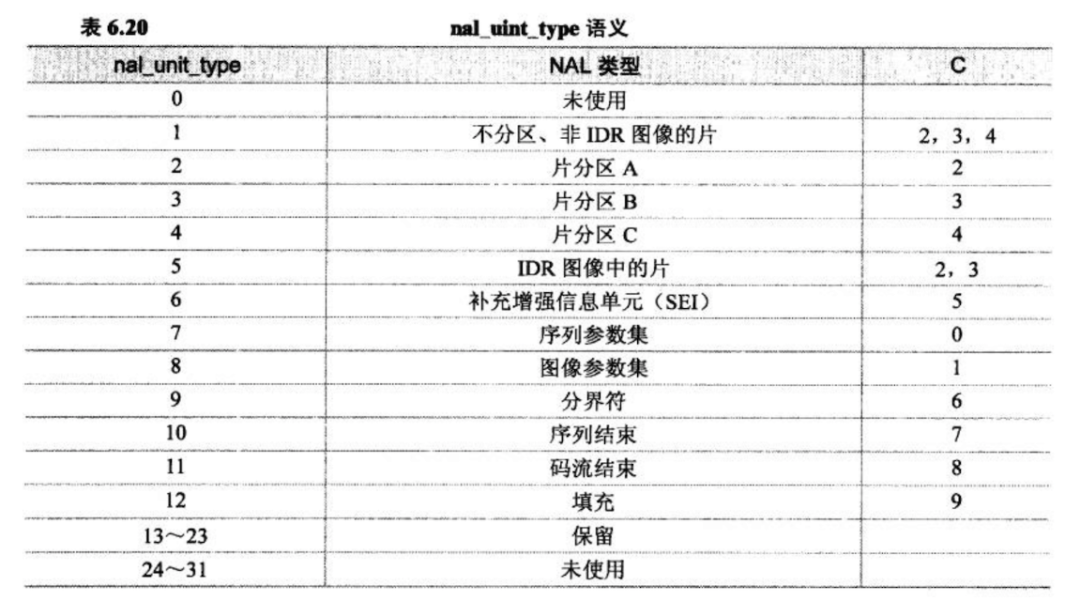
从 nal_unit_type 的定义可知,编码数据传输的基本单元是片,而片内则包含了宏块和子宏块。实际上帧内预测也是局限于片内的,不同片之间是不能参考的,这样做主要就是为了在错误发生时,限制错误的影响范围。
这里我们可以总结如下:H.264 码流传输的基本单元是 NAL 单元,NAL 单元内携带的最关键的数据是参数集和片数据;解码的基本单元是宏块,解码器根据预测信息和残差数据,解码出原始数据;宏块解码之后拼接成片,片拼接成图像,而一幅幅图像则构成了视频!
这里我还想提一点,那就是最后这个一层层的拼接关系,是怎么无缝衔接起来的?
如果让我们设计方案,我们也许会为图像增加播放顺序,进而图像可以按序播放;我们也许会为片增加编号,进而各片就可以按编号拼接为一幅图像;我们也许会为宏块增加编号,这样各宏块就可以按编号拼接为一个片。
实际上 H.264 的方案和我们的朴素想法相去无几:每幅图像除了有播放顺序(Picture Order Count, POC),还有解码顺序(frame_num),因为帧间预测有双向预测,所以解码顺序可能和播放顺序不一样;每个宏块并没有编号,因为一个片的所有宏块都在一个 NAL 单元内,它们按需排列,无需额外编号;每个片没有编号,但片头内有表示本片中首个宏块在整幅图像中的位置信息(first_mb_in_slice),这样我们就知道这个片应该放在图像的什么位置,效果和编号一样;至于整个视频、每幅图像的整体信息,例如宽高信息,则在 SPS 和 PPS 中有相关字段进行描述。
3、具体句法和语义:
原本我想把每一层的各个句法元素简略过一遍的(实际也这么做过),但奈何完全无法涵盖细节,而众多句法元素罗列一遍实在无法脱离堆砌之嫌,所以索性删了个干净。感兴趣的朋友强烈建议阅读原书,或者 H.264 SPEC,至于从事视频编解码相关工作的朋友,则一定要对句法和语义烂熟于胸了。
我整体感觉 H.264 句法描述的方式还是十分巧妙的,它以解码器伪代码的形式,来定义数据格式,真是一举两得。H.264 的句法经过了精心的设计,构成句法的各句法元素既相互依赖而又相互独立。依赖是为了减少冗余信息,提高编码效率,而独立是为了使通信更加鲁棒,在错误发生时限制错误的扩散。
H.264 编码过程:
H.264 规范没有具体规定编码器的结构和实现模式,只要它产生出来的码流结构符合规范即可,这样编码过程就非常灵活了。
不过其基本结构就是第一部分我们提到的基本框架:预测编码、变换编码、熵编码。
编码器基本结构如下图所示:
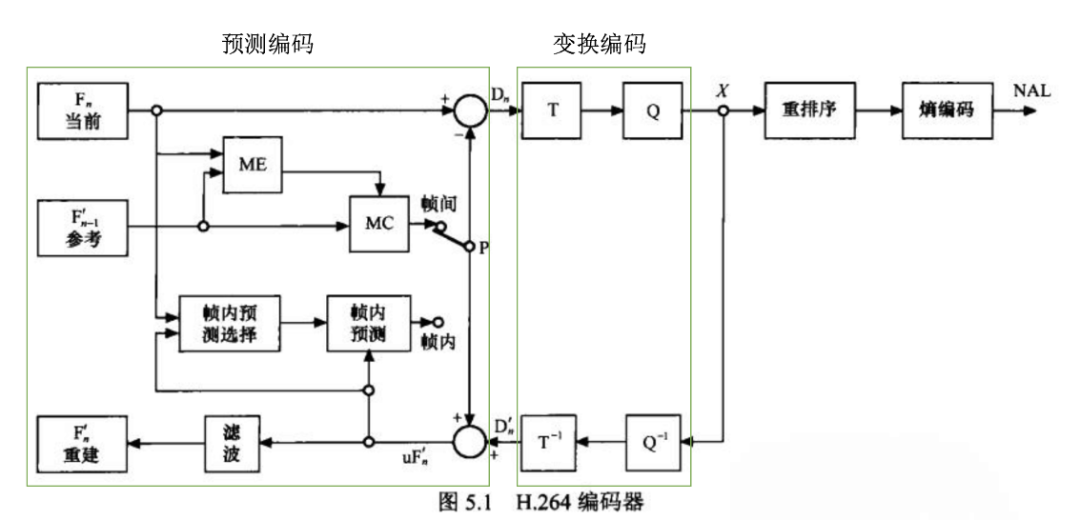
其中最复杂扩展空间最大的,就是预测编码的过程了,而预测编码里最重要同时也是最消耗计算资源的,是运动估计的搜索过程。
此外,无论编码器的结构如何,相应的视频编码的控制都是编码器实现的核心问题。在编码过程中,并没有直接控制编码数据大小的方式,只能通过调整量化过程的量化参数 QP 值间接控制,而由于 QP 和编码数据大小并没有确定的关系,所以编码器的码率控制无法做到很精细,基本都靠试。要么是中途改变后续宏块的质量,要么是重新编码改变所有宏块的质量。
H.264 解码过程
解码过程就是编码的逆过程:熵解码、变换解码、预测解码。
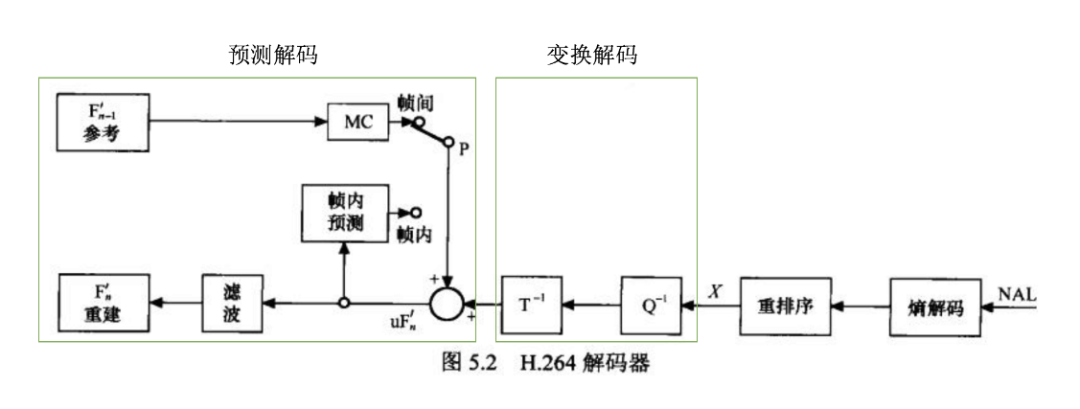
H.264 规范规定了解码器的结构,所以我们可以更细致的总结解码过程:以宏块为单位,依次进行熵解码、反量化、反变换,得到残差数据,再结合宏块里面的预测信息,找到已解码的被参考块,进而结合已解码被参考块和本块残差数据,得到本块的实际数据。宏块解码后,组合出片,片再组合出图像。
解码器基本结构如下图所示:
H.264 的可伸缩编码:
可伸缩编码(Scalable Video Coding, SVC)实质上是将视频信息按照重要性分解,对分解的各个部分按照其自身的统计特性进行编码。一般它会将视频编码为一个基本层和一组增强层。基本层包含基本信息,可以独立解码,增强层依赖于基本层,可以对基本层的信息进行增强,增强层越多,视频信息的恢复质量也就越高。
SVC 通常有三种:
- 空域可伸缩:可以解码出多种分辨率的视频;
- 时域可伸缩:可以解码出多种帧率的视频,分辨率相同;
- 质量可伸缩:可以解码出多种码率的视频,分辨率、帧率相同;
SVC 的实现细节这里不做展开,感兴趣的朋友可以查阅相关资料
最后,详细细节可以阅读这本书籍:
- 《新一代视频压缩编码标准:H.264/AVC(第2版)》
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。