
在本文中,作者提出了 Imagic,能够将复杂的文本指导的语义编辑应用于单一真实图像,同时保留其原始特征。与以前的工作不同的是,此方法只需要一张输入图像和一个目标文本,不需要任何额外的输入。Imagic 利用一个预训练的文本到图像的扩散模型来完成这项任务。它产生了一个与输入图像和目标文本相一致的文本嵌入,同时对扩散模型进行微调,以捕捉图像的特定外观。
来源:CVPR 2023
作者:Bahjat Kawar, Shiran Zada 等
论文题目:Imagic: Text-Based Real Image Editing with Diffusion Models
论文链接:https://arxiv.org/abs/2210.09276
内容整理:汪奕文
引言
对真实照片进行语义编辑长期以来一直是图像处理中一项有趣的任务。近年来,由于基于深度学习的系统取得了相当大的进展,它引起了人们的极大兴趣。若所需的编辑可以由一个简单的自然语言文本提示来描述时,图像编辑就与人类的交流非常吻合。许多基于文本的图像编辑方法被开发出来,并不断改进;然而,目前领先的方法在不同程度上存在几个缺点:
- 只限于一种特定的编辑,如在图像上作画、添加对象或风格迁移
- 只能对特定类型的图像或生成的图像进行操作
- 除了输入图像外,它们还需要去他的辅助输入,如表明图像所需编辑位置的 mask、同一主题的多幅图像或描述原始图像的文本。
本文提出了一种语义图像编辑方法 Imagic,只需给定一个待编辑的输入图像和一个描述目标编辑的单一文本提示,就可以对真实的高分辨率图像进行复杂的非刚性编辑。生成的图像输出与目标文本很好地对齐,同时保留了原始图像的整体背景和结构。本文的主要贡献总结如下:
- 提出了 Imagic,这是第一个基于文本的语义图像编辑技术,它允许对单一的真实输入图像进行复杂的非刚性编辑,同时保留其整体结构和组成
- 展示了两个文本嵌入序列之间有语义的线性插值,揭示了文本到图像的扩散模型的强大生成能力
- 提出了一个复杂图像编辑 benchmark,它能够对不同的基于文本的图像编辑方法进行比较。
扩散模型

方法
对于给定输入图像 x 和描述所需编辑的目标文本,我们的目标是以满足给定文本的方式编辑图像,同时最大化地保留 x 的细节。为了实现这一目标,我们利用扩散模型的文本嵌入层来执行语义操作。与基于 GAN 的方法类似,我们首先寻找有意义的表示,在生成过程中嵌入,并产生与输入图像相似的图像。再微调生成模型,以更好地重建输入图像,最终操纵潜在表示获得编辑结果。此方法共包含三个步骤:
- 优化文本嵌入,在目标文本嵌入附近找到与给定图像最匹配的文本嵌入
- 对扩散模型进行微调,更好地匹配给定图像
- 在优化的嵌入和目标文本嵌入之间进行线性插值,以找到一个同时实现输入图像保真度和目标文本对齐的点
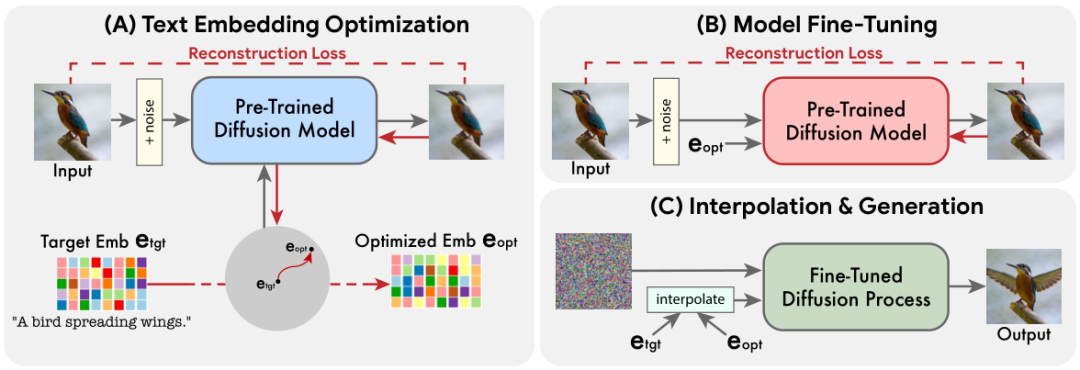
文本嵌入优化

模型微调

文本嵌入插值


实验
实施细节
作者使用 64 x 64 的扩散模型和 Adam 优化器对文本嵌入进行了 100 步优化,学习率为 1e-3 。然后,作者通过继续对输入图像进行 1500 步的 Imagen 训练,以优化的嵌入为条件,微调 64 x 64 的扩散模型。同时,作者还使用目标文本嵌入和原始图像对 64 x 64 —>256 x 256 的 SR 扩散模型进行 1500 步的微调,以捕捉原始图像的高频细节。作者发现,微调 256 x 256 —> 1024 x 1024 的 SR 扩散模型对原始图像的影响很小,模型对结果几乎没有影响,因此选择了使用以目标文本为条件的预训练版本。以上整个优化过程在两块 TPUv4 芯片上完成,每张图片需要大约 8 分钟。
实验结果
将 Imagic 应用于来自不同领域的大量真实图像,用简单的文本提示描述不同的编辑类别,如:风格、外观、颜色和姿势。Imagic 能够对一般的输入图像和文本应用各种编辑类别,并且可以对同一图像进行不同文本提示的编辑,显示了 Imagic 的多功能性。

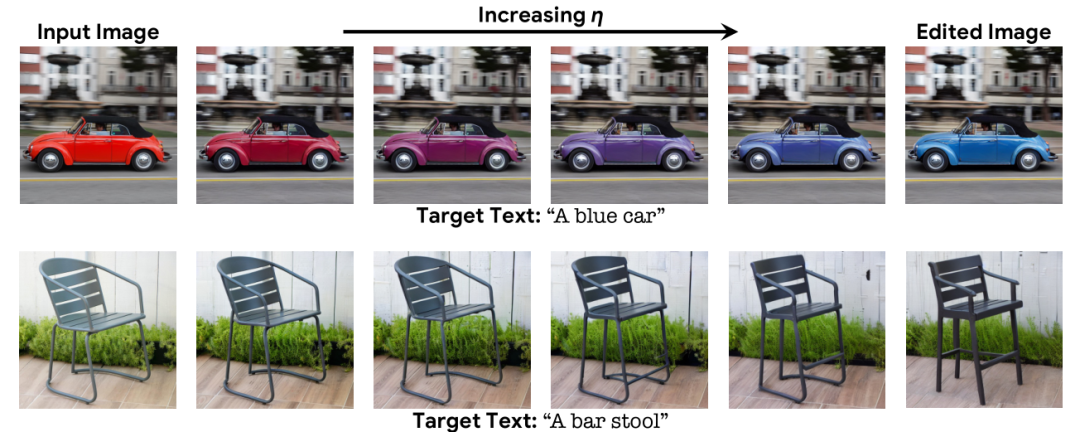
此外,作者还展示了随着 η 的变化,图像表现出平滑的语义插值特性。假设这种平滑特性是发生在语义潜在空间的扩散过程的副产物,而不是在图像像素空间。
作者将 Imagic 与目前领先的文本图像编辑技术进行比较,即 Text2LIVE、DDIB 和 SDEdit。对于 SDEdit 和 DDIB,将其应用于相同的图像模型和目标文本提示,同时保持相同的 Imagen 扩散超参数,并为每个图像独立选择 SDEdit 的中间扩散时间步长,以实现最佳的目标文本对齐,而不彻底改变图像内容。对于 DDIB,提供了一个额外的源文本作为输入。可以观察到,Imagic 保持了对输入图像的高保真度,同时适当地执行了所需的编辑。当被要求进行复杂的非刚性编辑时,所提出方法也明显优于以前的技术。

消融性实验
微调优化

作者使用预训练的 64 x 64 扩散模型(上图)和微调模型(下图)在不同的 η 值下生成编辑图像,以衡量微调对输出质量的影响。如果没有微调,该方法不能完全重建 η = 0 处的原始图像,并且不能随着 η 的增加保留图像的细节。相比之下,微调模型不仅优化了嵌入,还会从输入图像中引入细节,从而实现有语义的线性插值。此外,作者还对文本嵌入优化步骤的数量进行了实验,用较少的步骤优化文本嵌入会限制模型的编辑能力,而优化超过 100 个步骤几乎没有产生附加价值。
插值
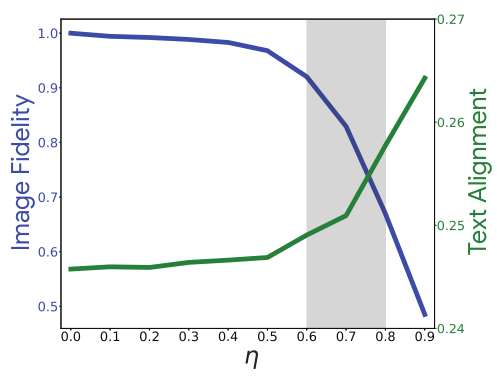
由于不同的编辑需要不同的强度,每个输入的最佳 η 值可能不同。为此,作者对 150 个图像-文本输入对计算输出的 CLIP 分数和 LPIPS 分数。较高的 CLIP 分数表明输出与目标文本的对齐更好,较高的 LPIPS 表明对输入图像的保真度更高。对于小于 0.4 的 η 值,输出几乎与输入图像相同。对于 η ∈ [0.6 , 0.8],图像开始改变,并更好地与文本对齐。因此将该区域确定为最可能获得满意结果的区域。
局限性
在某些情况下,编辑的目标文本非常微妙,不能很好地与目标文本对齐。在另一种情况下,图像的编辑效果很好,但会对图像外部细节有影响,如变焦或改变相机角度。当编辑应用的力度不够时,增加 η 通常可以达到所需的结果,但在少数情况下,有时会导致原始图像细节的重大损失。

来自:媒矿工厂——第一时间发布最新最有料的媒体技术资讯。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
