
由于目前互联网上有关AV1视频编码标准的中文资料特别少,针对它的compound inter prediction这一术语,本文将其译为混合帧间预测,以下皆用此名词代指。
1.基本原理
AV1中的混合帧间预测,它的基本原理简单来说就是使用2个不同的参考帧进行帧间加权预测,得到它的预测像素值,属于运动补偿预测MCP的过程。如下图所示:
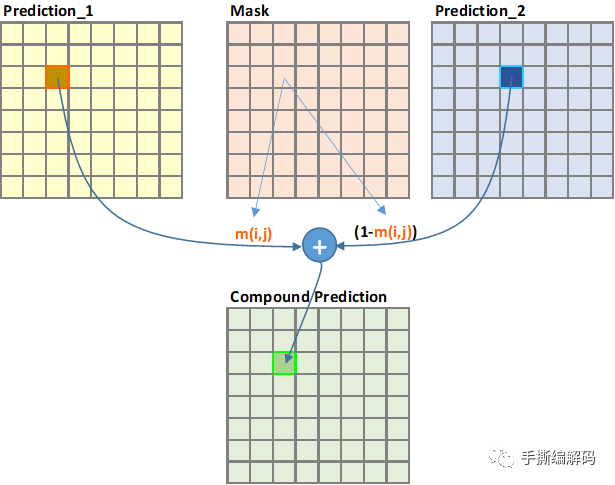
上图中的Prediction_1和Prediction_2用来表示当前块的两个不同的预测块,当前块的预测块的像素值p(i,j)的计算如下:
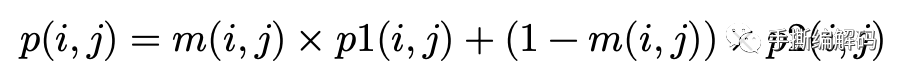
这个便是AV1混合帧间预测的计算式子,其中m(i,j)是每个像素位置在(i,j)对应的权重系数,其取值是0~1的浮点数。请大家注意上式三个像素点位置关系,均是(i,j)位置。
混合帧间预测看起来类似于H.265里的加权预测,但也没必要去硬套H.265系列的技术,我们还是针对AV1来具体问题具体分析。混合帧间预测的技术原理,似乎是较为简单的,但细思之下还是有几个不可忽视的问题,最关键的就是混合帧间预测里的p1,p2和m是如何得到的。
前面只说了要用到2个参考帧,但没说这2个参考帧是来自前向参考帧,还是后向参考帧。此外,我们知道,要获得参考帧里对应的预测像素块,首先需要通过一些方式得到MV信息,然后再进行MC才行。
所以,当前块的两个参考帧应该是如何选择的?参考帧里对应的预测块(MV)是怎么获得的?混合两个预测块的Mask矩阵里的权重系数m(i,j)又是怎么取值的?
如果你对以上几个问题,还没有确定的答案,请继续阅读下文。
2.参考帧的选择
正如本号在之前文章中所介绍的AV1的参考帧内容,当前编码帧可选的前向参考帧有4个,后向参考帧有3个。
如果按常规思路来计算,每个编码块可选的compound参考帧组合共有21组,即前向的4选2加上后向的3选2再加上双向的4乘以3。但实际在AV1视频编码标准里,可选的compound参考帧组合一共有16组,舍弃了单向componud的5组。
具体地,我画了个示意图如下:

我用黄色块表示前向参考帧,红色块来表示后向参考帧,每个块中的数字表示参考帧的index,每个块下面是参考帧类型。
例如参考帧索引(1,2)表示选择的参考帧组合是(LAST,LAST2),显然它是一个单向的compound,本该是21组参考帧组合,去掉了(2,3),(2,4),(3,4),(5,7)和(6,7)这5个单向参考帧组合。
在AV1里这么做的依据是什么呢?在论文《A Technical Overview of AV1》里面是这样说的:
In estimation theory, it is commonly known that extrapolation (unidirectional compound) is usually less accurate than interpolation (bidirectional compound) prediction.assumption that if the numbers of the reference frames on both sides of thecurrent frame in natural display order are largely balanced, the bi-directional predictions are likely to provide better prediction
总之,混合帧间预测对参考帧的组合方式是有4个特殊的单向参考帧组合,和12个双向参考帧组合。
3.MV和MVP的获得
确定了可选的参考帧之后,接着是考虑从中获取MV信息,按AV1的标准文本:
compound_mode specifies how the motion vector used by inter prediction is obtained when using compound prediction. An offset is added to compound_mode to compute YMode.
即当这个块是混合帧间预测的时候,会用compound_mode语法来指定其帧间预测的MV如何获取。
我们知道,编码器侧的MV一般可以通过ME来获取,同时AV1中对MV信息的压缩编码使用了预测编码技术,会构建时域和空域MVP列表来获取预测MV,最终被写进二进制码流里的可能是MVD等信息。所以,混合帧间预测需要明确采用的MVP模式类型。
AV1中的MVP列表又叫DRL,是Dynamic Reference List的缩写,列表最多有4个候选项,下图是混合帧间预测的MVP模式类型。
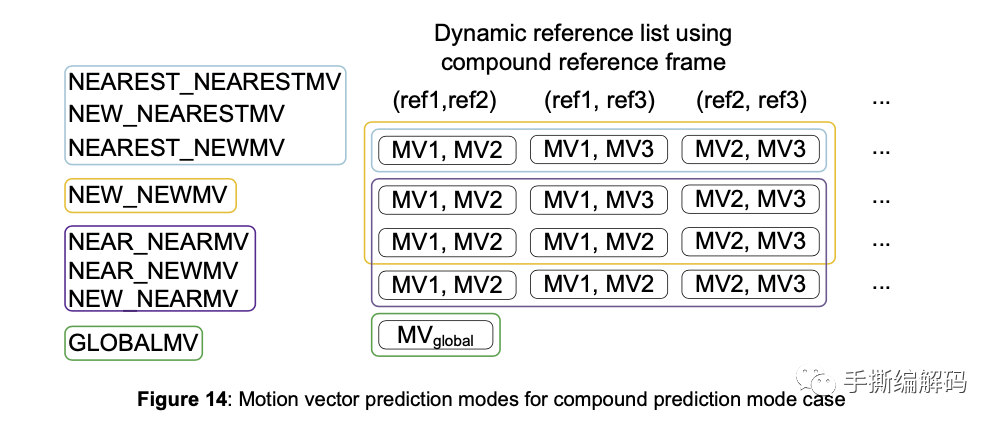
例如当选择的MVP模式是NEW_NEWMV时,表示ref1里对应的MV1是NEWMV,同时ref2里对应的MV2是NEWMV。
AV1里DRL的索引取值范围是0~3,具体取哪个值是和具体的MVP模式类型有关,如下图所示:

要注意的是,像NEAR_NEARMV这种类型,由于drl取到1,2,3都有可能,因而编码器对drl索引还需要RDO进行PK。
SVT-AV1中解析compound mode信息的函数如下:

AV1中的混合帧间预测的MVP模式类型一共有8类,分别是:
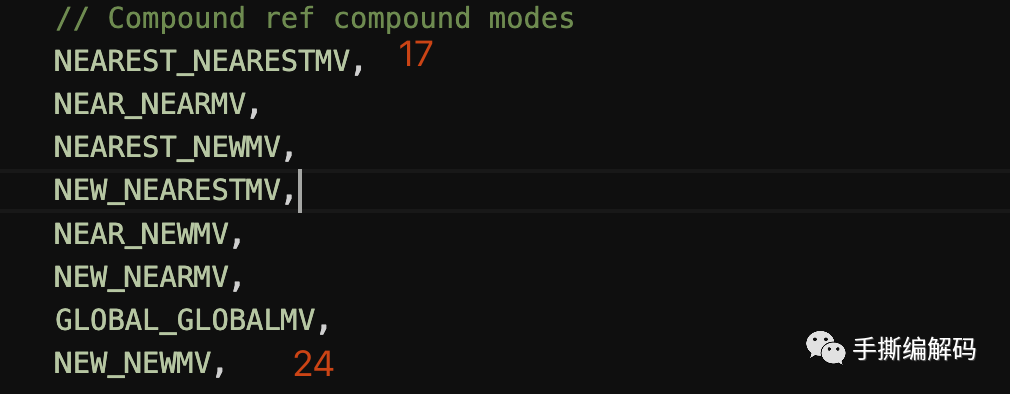
这也就意味着混合帧间预测在确定了2个参考帧以后,参考帧对应预测块的MVP也还有8类不同的候选,编码器侧具体使用哪一种候选需要根据RDO来决定,最终需将确定drl索引。
4.加权系数的获取
以上确定了参考帧以及MV信息,进行MC获取2个对应预测块像素以后,还需要考虑如何将2个预测块像素值组合在一起。按照AV1标准的文本规定:
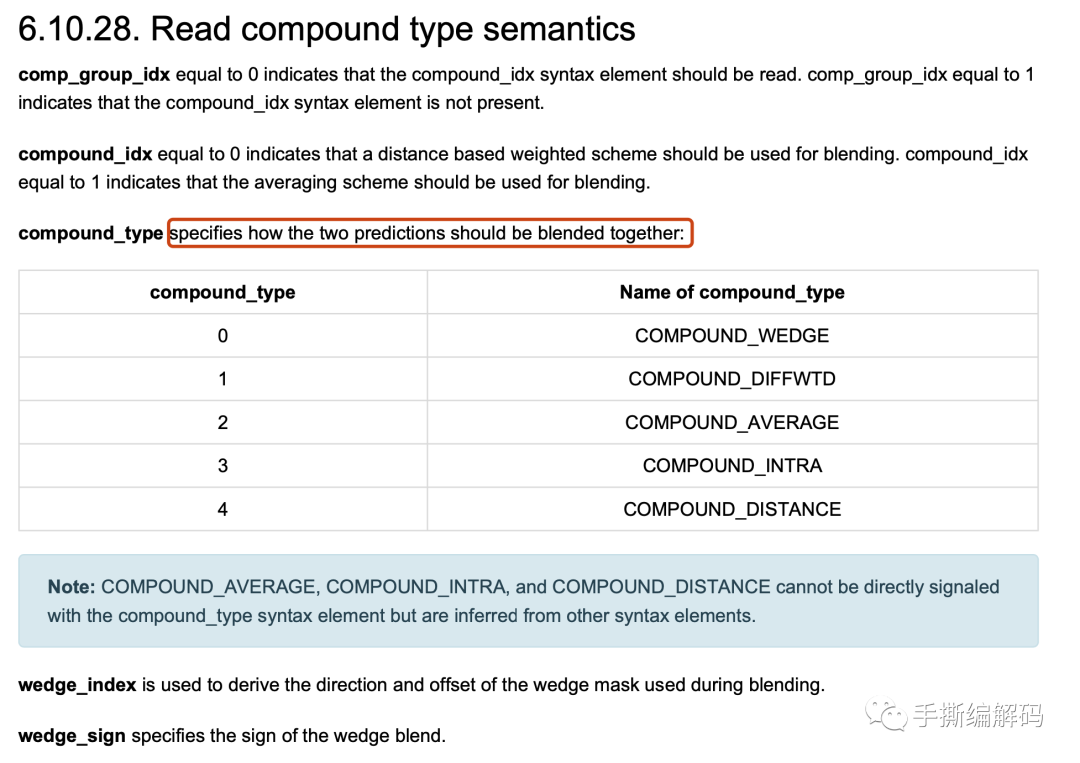
compound_type specifies how the two predictions should be blended together
关于如何把2个预测块的像素值给融合到一起,得到当前块的预测像素值,一共有5种方式,如下图所示:
对于Wedge方式,AV1视频编码标准会针对不同编码块大小提前定义好16组的二维加权系数数组,且每个加权系数数组和Wedge分割模式相关联。
这种混合预测方式适合对块边界的预测,能够更接近真实物体的运动,比我们之前常见的矩形块分割方式要好一些,下面是Wedge分割模式:

不同的分割模式对应着由m(i,j)所组成的一个Mask矩阵,比如上图左边的第一个Wedge分割模式,假设当前编码块的大小是16×16,则它对应的Mask矩阵是:
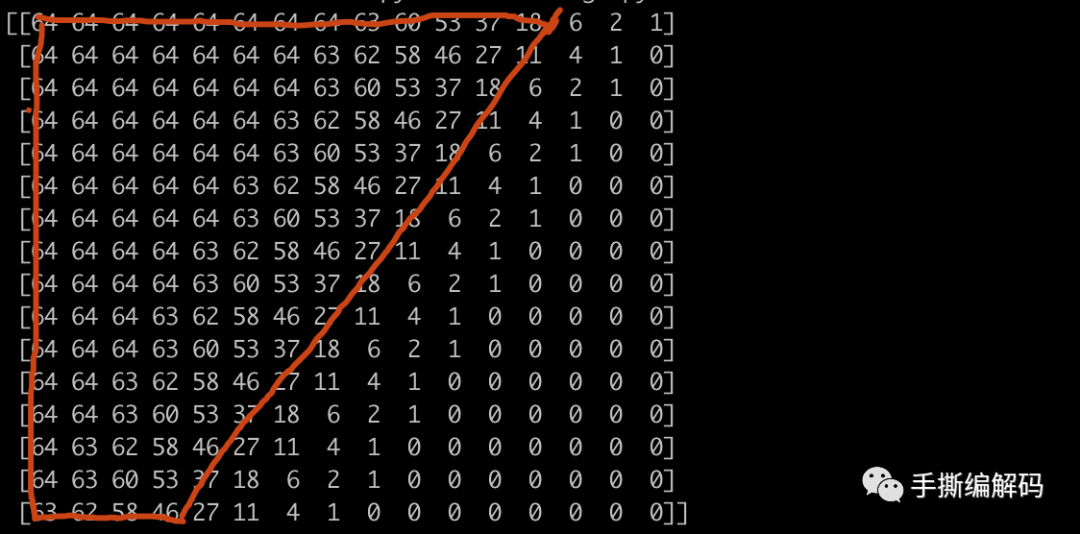
上图这个矩阵里的元素值,是根据AV1的标准文本里Wedge_Master相关矩阵得到的,可以看到,当元素位置越接近楔形分割线,加权系数取值约接近32。
AV1用两个语法元素来表征Wedge模式:wedge_index is used to derive the direction and offset of the wedge mask used during blending.wedge_sign specifies the sign of the wedge blend.
对于DIFF方式,混合预测的加权系数和两个预测像块对应像素值的差值相关,是通过下面的方式获取:
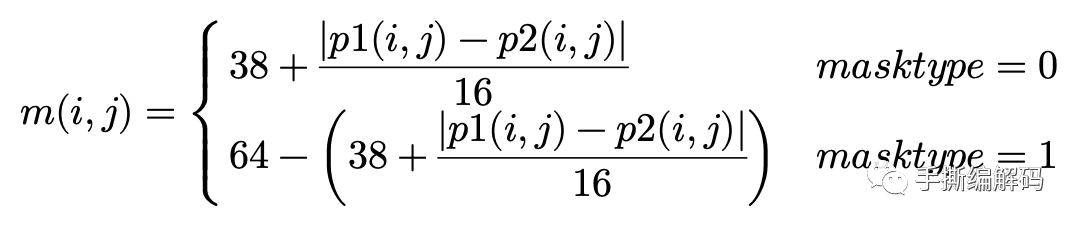
对于AVERAGE方式,就很简单,加权系数m(i,j)=32,最终的预测像素值就是两个预测块对应位置的像素值的平均。
对于DISTANCE模式,加权系数的取值和当前编码块与它的2个参考帧的时域距离大小有关,如果用d1和d2分别表示这2个距离,且d2小于d1,则有:
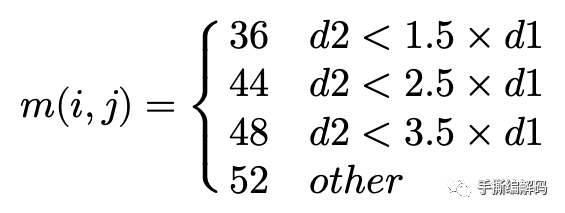
反之,如果d2大于d1,则有
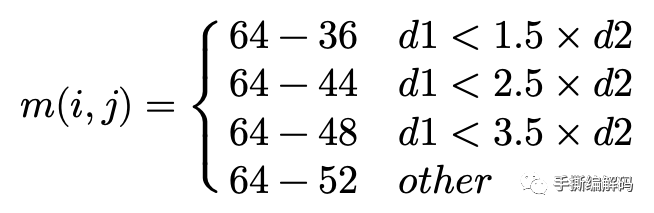
在计算加权系数m(i,j)以及获得预测像素值时,为了将浮点数运算转为整数运算,以上加权系数系数均乘以了64。
还剩一种INTRA的混合模式,下回再讲。
最后来简单回顾一下混合帧间预测,对编码器来说,某个编码块要使用混合帧间预测技术,需要从16种参考帧候选中选择最佳的一组,然后从8类MVP类型模式中选择最佳的一个(同一种可能会有多个候选索引),最后再从5种预测像素值的混合方式中选择一个最佳的,来得到最终预测像素值。抛开ME计算MV的复杂度外,光是给编码块选择一个合适的compound方式就需要这么多的决策过程。
作者: 手撕编解码
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
