
一、背景
首先一张图片由一个个像素组成(可以看成网格),每个像素可以有一个灰度值(标量)或RGB值(三维向量)。

http://a-chien.blogspot.de/2017/01/excel-vba_5.html
现今一张图片动辄1000*1000=100w像素,因此对于图像处理来说,是非常大的维度。
超像素最大的功能之一,便是作为图像处理其他算法的预处理,在不牺牲太大精确度的情况下降维!
二、超像素
超像素最直观的解释,便是把一些具有相似特性的像素“聚合”起来,形成一个更具有代表性的大“元素”。
而这个新的元素,将作为其他图像处理算法的基本单位。
一来大大降低了维度;二来可以剔除一些异常像素点。
至于根据什么特性把一个个像素点聚集起来,可以是颜色、纹理、类别等。
看下图大家就能一瞥一二:

https://ivrl.epfl.ch/research/superpixels
三、超像素算法
理论上,任何图像分割算法的过度分割(over-segmentation),即可生成超像素。
下面是一个图像分割算法的例子(举此例还因为这里分割标准是依据纹理)。
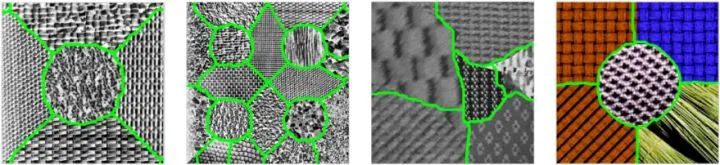
https://github.com/mstorath/Pottslab
四、超像素算法判别条件
市面上如此多的超像素算法,如何比较他们的优劣呢?
一般业内参考以下三个指标(具体公式请参考【1】).
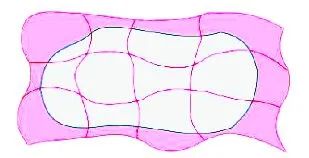
(1) Undersegmentation Error
下图,白色是原图的一个物体,红线是一个个超像素的轮廓,而粉红色的区域就是undersegmentation的区域。显然,这部分区域越大就越不好。
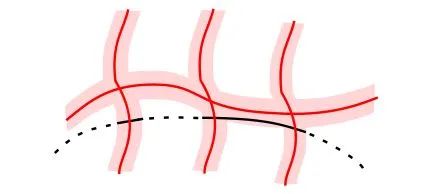
(2) Boundary Recall
下图,黑色虚线以及实现是原图物体的轮廓,红线是超像素的边界。一个好的超像素算法,应该覆盖原图物体的轮廓。在给予一定缓冲(粉红色区域)的情况下,超像素的边缘可以覆盖原图物体边缘的越多(黑色实线),该算法就越好。
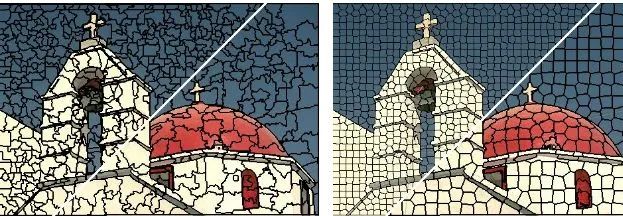
(3) Compactness score
这个指标衡量了一个超像素是否“紧实”。
下图,高下立判。
https://ivrl.epfl.ch/research/superpixels
五、超像素算法举例
(1) 种子像素初始化
SLIC利用了简单的聚类(贪婪)算法,初始时刻,每一个聚类的中心被平均地分布在原图中。而超像素的个数,也可以基本由这些中心点来决定。
每一步迭代,种子像素合并周围的像素,形成超像素。

(2) 矩形区域初始化
SEEDS的初始化,是把原图先平均分割成很多矩形,初始超像素即为这些矩形。每一步迭代,超像素的边缘不断变化,直到converge.

【参考资料】:
【1】D Stutz etl,Superpixels: an evaluation of the state-of-the-art,Computer Vision and Image Understanding 166, 1-27
该文作者是德国亚琛工大计算机本科,马普所计算机博士生,对比了几乎所有有开源代码的超像素算法。作者还把论文中evaluate指标的算法开源了,参考:davidstutz/superpixels-revisited
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
