
作为近两年大火的生成模型,扩散模型在图像合成任务上表现突出,近期也有一些工作将扩散模型引入视频合成与编辑任务。本文提出将扩散模型扩展到人脸视频编辑任务中,提出了一个扩散自动编码器的新型人脸视频编辑框架,它通过从给定的视频中提取身份和运动的分解特征,改变其中时不变的特征来编辑视频,从而解决了视频编辑任务中编辑帧之间的时间一致性的挑战。实验表明,相较于之前的方法,本文方法能得到质量更高的生成结果,并且与现有的基于GAN的方法相比,它对一些边角案例(如被遮挡的人脸)具有鲁棒性。
论文题目:Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
作者:Gyeongman Kim, Hajin Shim, Hyunsu Kim, Yunjey Choi, Junho Kim, Eunho Yang
论文链接:https://arxiv.org/abs/2212.02802
项目链接:https://github.com/man805/Diffusion-Video-Autoencoders
内容整理:王怡闻
引言
人脸属性编辑一直是图像合成方向上的难点之一。本方法为人脸视频编辑任务引入了基于扩散的模型。正如 DiffAE,该模型学习了一个有语义的潜在空间,可以完美地恢复原始图像,并且可以直接编辑。不仅如此,作为一个视频编辑模型,它首次对视频的分解特征:1)所有帧共享的身份特征,2)每一帧中的运动或面部表情特征,以及 3)由于变化过大而无法高层次表示的背景特征进行编码。然后,为了保持编辑的一致性,只需对所需属性的单一不变特征进行操作,与之前工作相比也减少了计算量。
Diffusion Video Autoencoders
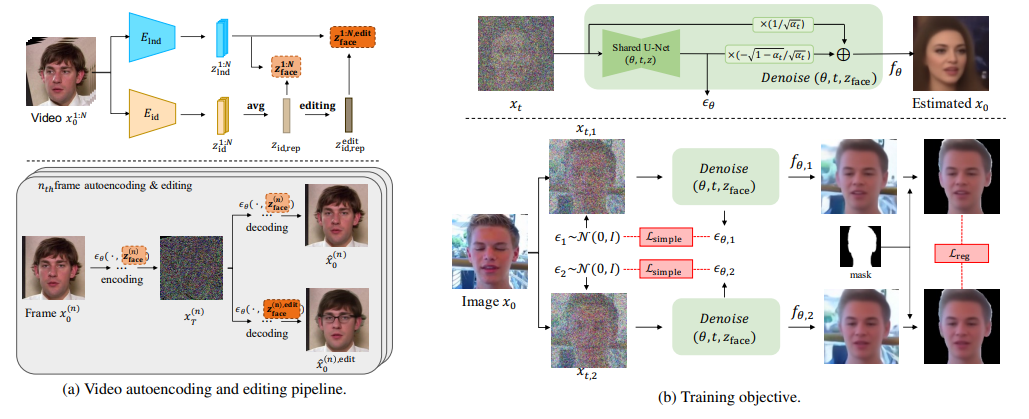
Disentangled Video Encoding
模型中包括两个独立的 encoder 提取视频帧中的 identity 信息(表示视频中人的身份特征,被认为是 time-invarient 的)与运动或面部表情 (motion) 特征。本文中这两个 encoder 都使用了预训练模型。由于视频中的身份特征一般不会有太大的变动,每帧的身份特征在最后会一起做一个 average 的操作,这个得到的特征即为该视频最终的身份特征。identity 特征与 motion 特征 cat 在一起则为该视频的 face 特征,在扩散过程中将以 face 特征作为辅助信息指导模型生成,并可以通过对 identity 特征进行编辑来实现视频人脸编辑的效果。
训练过程
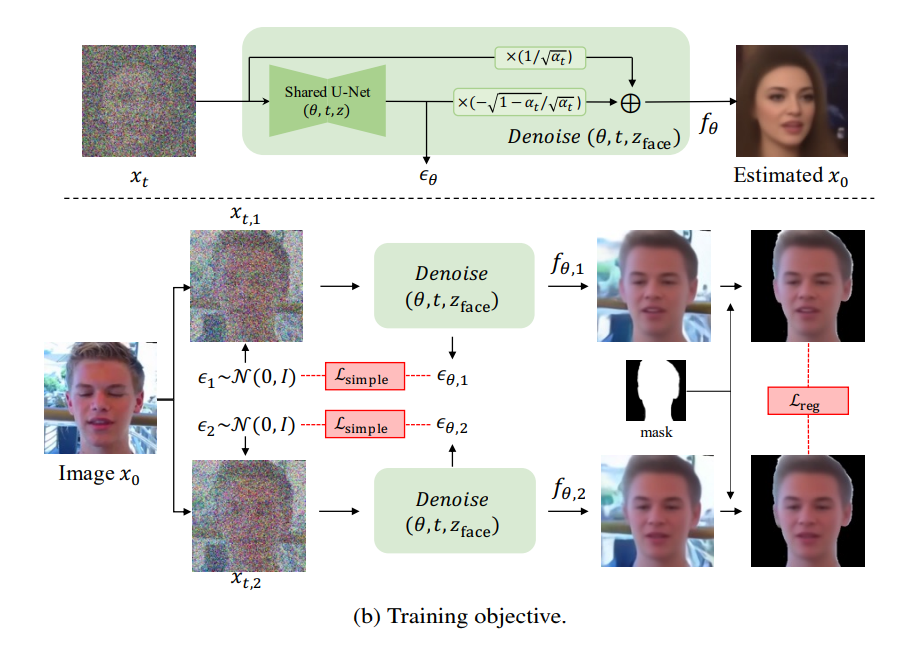
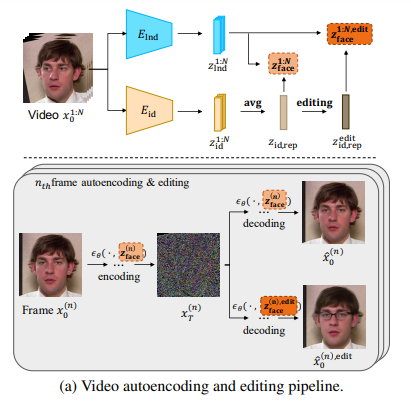
训练的优化目标由两部分组成。第一部分是 DDPM loss,通过优化该 loss 让潜在空间特征更全面地学习到输入图像的信息,并在解噪时可以被充分利用。第二部分是 regularization loss,防止面部信息 (identity 和 motion) 在学习过程中泄露到噪声潜在变量中去。为实现这一点,文中提出通过采样两个高斯噪声来获得两张不同的去噪图片,然后最小化这两张图片人脸部分(用一个 mask 来去除背景信息)的正则化损失。
编辑方法
如何对上文说到的 identity 特征进行编辑?本文提供了如下两个方法。
Classifier-based editing
参考 DiffAE,在 CelebA-HQ 数据集上为数据集中的每一个属性训练了一个线性分类器

CLIP-based editing
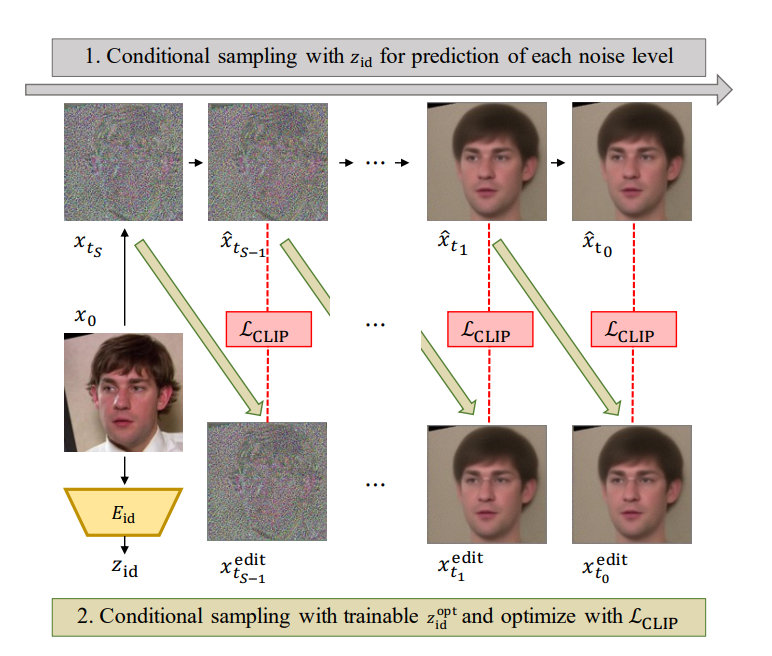
首先介绍一下 Directional CLIP loss:

实验结果
与之前方法的对比

重建效果对比
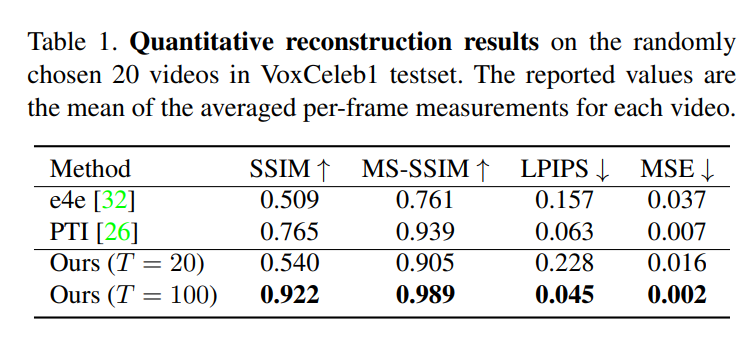
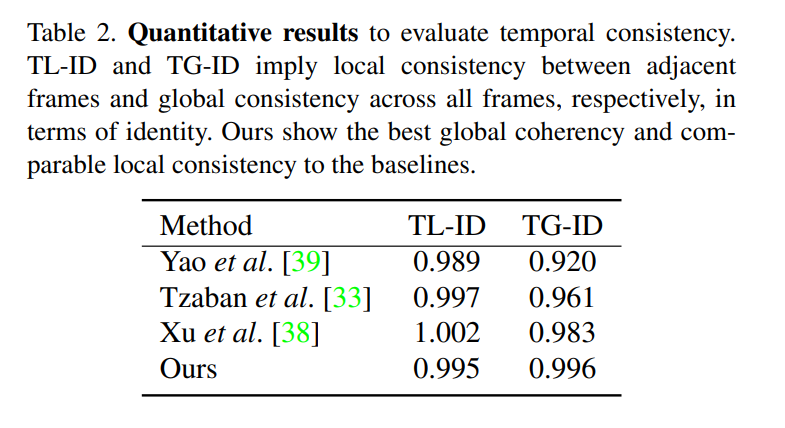
时间一致性
视频分解特征展示

消融实验

证明了正则化损失的必要性。
来源:媒矿工厂第一时间发布最新最有料的媒体技术资讯。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
