
什么是超分辨率?
“分辨率”是一个泛指图像清晰程度或者图像输出设备解析能力的词,其实就是我们经常说的那个空间分辨率。(凡是能度量的量都存在分辨率,比如时间、空间、光谱、辐射量等等,都是成像中会遇到的分辨率。而我们常说的分辨率,没有特别限定的话就是指空间分辨率。)
那什么是空间分辨率呢?空间分辨率简单讲就是单位长度内拥有多少个采样点,采样点越多,分辨率越高,图像就越清晰。举个例子:1mm的长度采样1000点,那每个点就是1μm,这时候我们就可以说其空间分辨率是1μm。对于侦察卫星而言,经常会出现10m、2m、1m、0.5m甚至0.1m的分辨率,就是指对地观测时的空间分辨率,对于0.1m的精度来说,一辆汽车约有20×40像素。

不同分辨率的差别
在数字成像技术,视频编码通信技术,深空卫星遥感技术,目标识别分析技术和医学影像分析技术等方面,视频图像超分辨率技术都能够应对显示设备分辨率大于图像源分辨率的问题。
简单来说超分辨率技术可以分为以下两种:
1)只参考当前低分辨率图像,不依赖其他相关图像的超分辨率技术,称之为单幅图像的超分辨率(single image super resolution),也可以称之为图像插值(image interpolation)。
2)参考多幅图像或多个视频帧的超分辨率技术,称之为多帧视频/多图的超分辨率(multi-frame super resolution)。
这两类技术中,一般后者相比于前者具有更多的可参考信息,并具有更好的高分辨率视频图像的重建质量,但是其更高的计算复杂度也限制了其应用。
浅谈一下基于深度学习的图像超分辨率技术?
此部分内容转自公众号[我爱计算机视觉]
低分辨率图像一般通过一系列的退化操作得到,在损失了大量细节的同时,也引入了一系列的噪声。基于深度学习的超分辨率过程本质上就是通过网络模型采用成对的训练数据进行有监督学习的训练,进而拟合上述退化操作的逆操作,得到重建后的高清图像。
上文有提到,目前主流的图像超分辨率技术的解决方案可以分为基于单张图像的超分辨率技术和基于参考图像的超分辨率技术,下面将分别对其展开介绍。
基于单张图像的超分辨率是指通过一张输入图像对图像中的高分辨率细节进行重建,最终得到图像超分辨率的结果,是传统图像超分辨率问题中的主流方法。
在众多方法中,SRCNN 模型 [3] 首次将卷积神经网络应用于图像超分辨率技术,相对于传统插值、优化算法在重建质量上取得了极大的提升。如下图所示,该模型使用一个三层的卷积神经网络来拟合从低分辨率图像到高分辨率图像的函数。特别地,该方法在 FSRCNN 模型 [4] 中被进一步优化,大大提升了其推理速度。
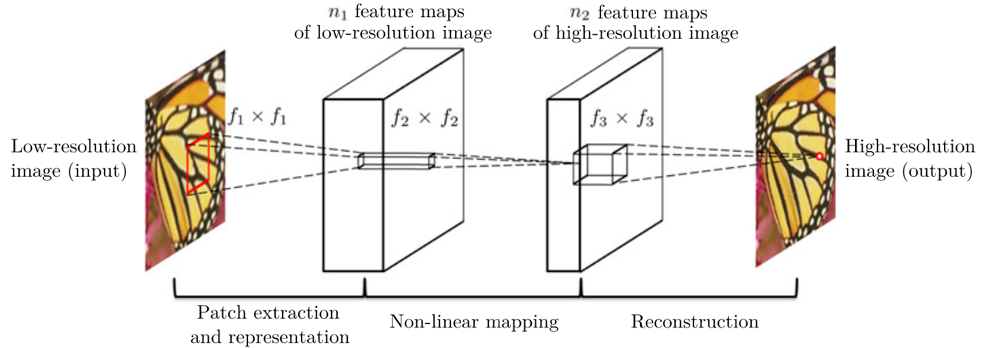
SRCNN 模型中的三层卷积结构
图像超分辨率过程实际上是高频纹理信息的生成过程,对于低频部分通常来源于输入的低分辨率图像。然而,SRCNN 模型的特征学习过程不仅要学习生成高频的信息,还需要对低频信息进行重建,大大地降低了模型的使用效率。针对于此,VDSR 模型 [5] 首次提出了残差学习的网络结构。如图4所示,通过一个残差连接(蓝色箭头)将输入图像直接加到最终的重建高频残差上,可以显著地提升模型的学习效率。
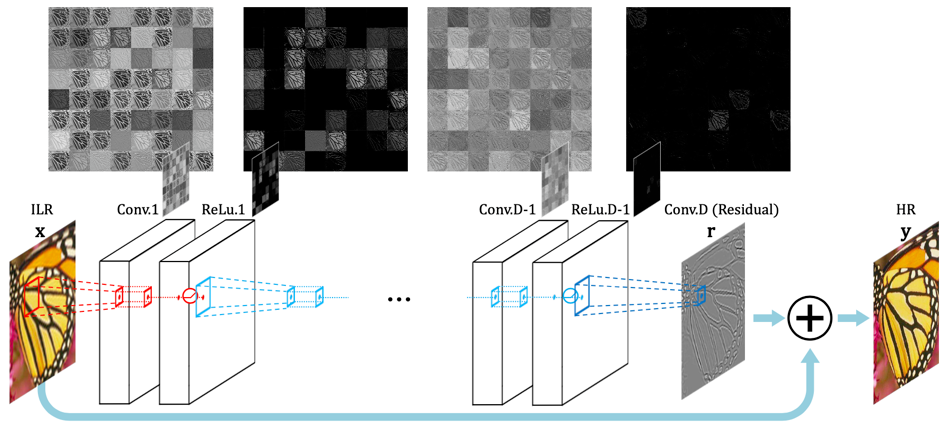
VDSR 模型中的残差学习结构
不难发现,上述方法均是先对输入的低分辨率图像进行上采样,然后再将其送入模型行进行学习,这种做法在降低了模型的推理速度的同时也大大增加了内存的开销。如下图所示,EPSCN 模型 [6] 首次提出了子像素卷积操作,在网络的最后才将学习得到的特征进一步放大到目标大小,大大提升了模型的训练效率,也使得更深卷积通道数更多的模型的训练成为了可能。
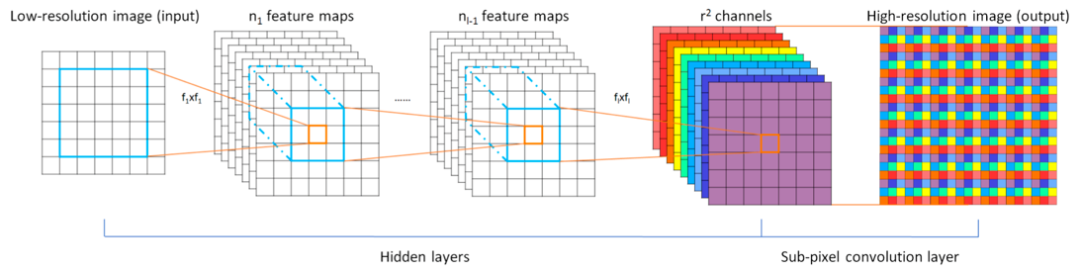
ESPCN 模型中的子像素卷积操作
为了进一步提升模型的表达能力,如下图所示,SRResNet 模型 [2] 首次将被广泛应用于图像分类任务中的残差模块引入到了图像超分辨率问题中,取得了很好的结果。此外,EDSR 模型 [7] 针对上述网络结构提出了进一步的优化,通过去掉残差模块中的批量归一化层和第二个激活层,进一步提升了模型的性能。
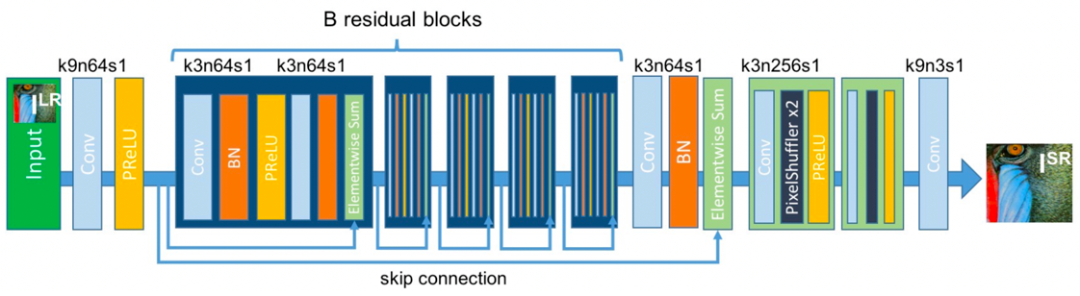
SRResNet 模型中的残差模块结构
近年来,还有很多其他方法从模型的角度进行优化。如,SRDenseNet 模型 [8] 和 RDN 模型 [9] 引入了稠密卷积模块,RCAN 模型 [10] 引入了通道注意力机制,SAN 模型 [11] 引入了二阶统计信息等,上述方法均取得了非常好的结果。
如前文所述,图像超分辨率问题是一个病态的问题,通过单纯的使用平均平方误差或平均绝对误差损失函数进行训练的模型往往会输出模糊的图像。这是因为在整个训练过程中,模型的优化得到的最优解实际上是所有可行解的一个平均值。
针对上述问题,被广泛应用于图像风格迁移的感知损失函数和风格损失函数被分别引入图像超分辨率问题中 [12, 13],某种程度上缓解了上述问题。另一方面,对抗生成损失函数在图像生成模型中取得了很好的结果,SRGAN 模型 [2] 首次将其应用于图像超分辨率问题,大大地提升了重建图像的真实感。
然而上述方法仍存在一定的问题,主要是由于生成对抗网络所依赖的模型能力有限,往往很难对自然界中的全部纹理进行表达,因此在某些纹理复杂的地方会生成错误的纹理(如下图的文字部分),带来不好的观感。

基于对抗生成损失函数的错误纹理生成问题
针对单张图像超分辨率技术中生成对抗损失函数引入的错误纹理生成问题,基于参考图像的超分辨率技术为该领域指明了一个新的方向。基于参考图像的超分辨率,顾名思义就是通过一张与输入图像相似的高分辨率图像,辅助整个超分辨率的复原过程。高分辨率参考图像的引入,将图像超分辨率问题由较为困难的纹理恢复/生成转化为了相对简单的纹理搜索与迁移,使得超分辨率结果在视觉效果上有了显著的提升。
Landmark 模型 [14] 通过图像检索技术,从网络上爬取与输入图像相似的高分辨率图像,再进一步通过图像配准操作,最终合成得到对应的超分辨率结果,其算法流程下图所示。
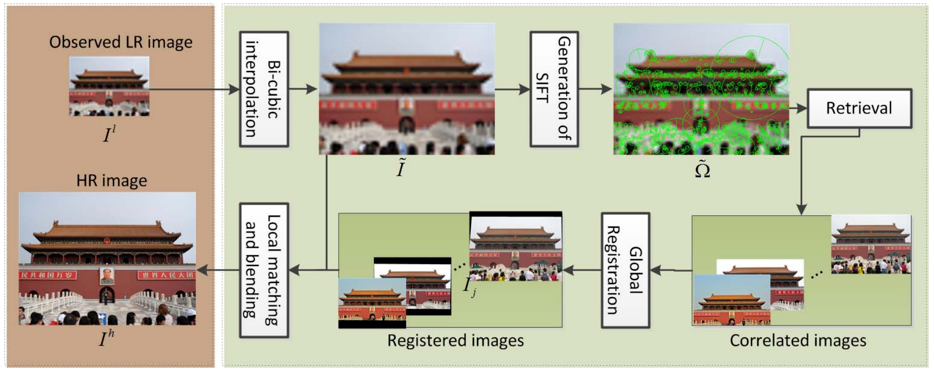
Landmark 模型的算法流程图
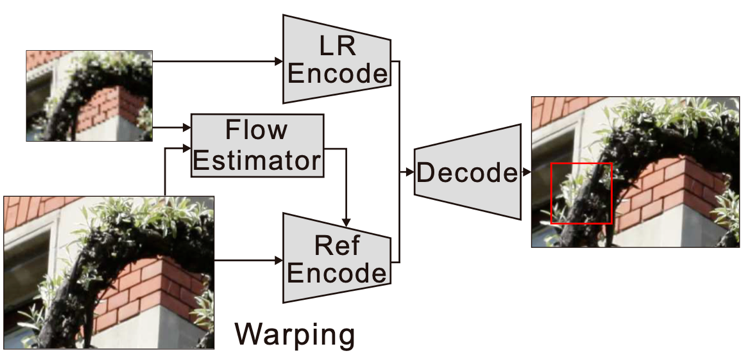
CrossNet 模型 [15] 进一步优化上述图像配准过程,提出了基于光流估计的模型结构。如下图所示,该模型通过估计输入低分辨率图像与参考图像之间的光流来对超分辨率图像进行重建。最终结果的优劣很大程度上依赖于光流计算的准确与否,而这要求输入的低分辨率图像与参考图像在视角上不能存在很大的偏差,大大限制了上述模型的适用性。
针对上述问题,最近发表的 SRNTT 模型 [16] 提出了基于图像块的全局搜索与迁移模块,取得了非常不错的结果。该模型通过在不同尺度上对输入低分辨率图像与高分辨率参考图像中的相似图像块进行全局的搜索与迁移,上述过程可以很好地通过高分辨率的参考图像中的高频纹理对输入低分辨率图像进行表达,进而得到非常真实的超分辨率结果。
参考资料:
- https://mp.weixin.qq.com/s/_c_3EQpj16iqHg9JdN574g
- Ledig C , Theis L , Huszar F , et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J]. CVPR 2017.
- Dong C , Loy C C , He K , et al. Image Super-Resolution Using Deep Convolutional Networks[J]. TPAMI 2016.
- Dong C , Loy C C , Tang X . Accelerating the Super-Resolution Convolutional Neural Network[C]. ECCV 2016.
- Kim J , Lee J K , Lee K M . Accurate Image Super-Resolution Using Very Deep Convolutional Networks[C]. CVPR 2016.
- Shi W , Caballero J , Huszár, Ferenc, et al. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network[C]. CVPR 2016.
- Lim B , Son S , Kim H , et al. Enhanced Deep Residual Networks for Single Image Super-Resolution[C]. CVPRW 2017.
- Tong T , Li G , Liu X , et al. Image Super-Resolution Using Dense Skip Connections[C]. ICCV 2017.
- Zhang Y , Tian Y , Kong Y , et al. Residual Dense Network for Image Super-Resolution[C]. CVPR 2018.
- Zhang Y , Li K , Li K , et al. Image Super-Resolution Using Very Deep Residual Channel Attention Networks[C]. CVPR 2018.
- Dai T , Cai J , Zhang Y, et al. Second-Order Attention Network for Single Image Super-Resolution[C]. CVPR 2019.
- Johnson J , Alahi A , Fei-Fei L . Perceptual Losses for Real-Time Style Transfer and Super-Resolution[C]. ECCV 2016.
- Sajjadi M S M , Schlkopf B , Hirsch M . EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis[C]. ICCV 2017.
- Yue H , Sun X , Member S , et al. Landmark Image Super-Resolution by Retrieving Web Images[J]. TIP 2013.
- Zheng H , Ji M , Wang H , et al. CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping[C]. ECCV 2018.
- Zhang Z , Wang Z , Lin Z , et al. Image Super-Resolution by Neural Texture Transfer[C]. CVPR 2019.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
