
人类语音是极富表现力的,包括语调、重读、风格、情感的各种表达。表现力语音合成(Expressive Speech Synthesis)的目标就是准确的表达出语音中的各种表现力因素。之前的表现力语音合成通常将表现力定义为说话时的单一因素,即风格或情感,然而风格可以随文本内容和场景进行转换,情感可以随着态度和意图进行转换。比如“童话故事”和“武侠评书”具有明显的朗读风格上的区分,而各自风格的语音朗读过程中又有着随文本内容变化而变化的的情感。因此,表现力语音合成中对风格、情感同时进行建模,进行独立控制是值得研究的方向。
近期,西北工业大学音频语音与语言处理研究组(ASLP@NPU)的论文“Multi-Speaker Expressive Speech Synthesis via Multiple Factors Decoupling”被语音研究顶级会议ICASSP2023接收。该论文提出一种基于多因素解耦的表现力语音合成方法,将语音分解为多种表征,包括内容、说话人、情感、风格,实现说话人、情感、风格的多因素重组,获得富有表现力的合成语音。现对该论文进行简要的解读和分享。

论文题目:Multi-Speaker Expressive Speech Synthesis via Multiple Factors Decoupling
作者列表:朱新发,雷怡,宋堃,张雍茂,李涛,谢磊
论文原文:https://arxiv.org/abs/2211.10568


1. 背景动机
近年来,基于神经网络的文娱转换(TTS)技术在合成语音的质量和自然度方面取得了巨大的突破。随着TTS的广泛应用,人们对合成语音的表现力提出了更高的要求。在先前表现力语音合成的工作中,语音表现力通常是指与语音相关的特定风格或情感表达。一种直接的方法是使用目标说话人富有表现力的训练语音来训练一个特定发言者的TTS系统。然而,这种方法不能直接推广到没有表现力训练数据的目标发音人,而且不是每个目标发音人都具备表现力数据。因此,利用迁移学习,将表现力从源发音人迁移到目标发音人是一种可行策略[1,2]。通过从其他发音人录制的参考语音(reference)中转移风格(style)和情感(emotion)来合成目标发音人的风格和情感语音是一种有效途径。具体地,风格是指在面对不同场合和不同文字题材发音人独特的讲话方式,例如新闻朗读、讲故事、诗歌朗诵和聊天对话等,都具备不同的讲话方式。即使对于某种风格,例如“讲故事”,不同的故事题材(如童话故事和悬疑小说)也会具备不同的讲话方式。相比之下,情感主要反映说话人的瞬时情绪状态,与态度和意图有关,例如一个童话故事里,随着情节的不同,会有喜、怒、哀、乐等情感表达。在有声书播报(audiobook)等表现力语音合成应用中,风格和情感需要兼备。然而,建立这样一个多因素语音合成系统面临三个挑战。
- 显式解耦多个因素——风格、情感和说话人音色更为困难,因为风格和情感都反映在语音的韵律中,因此两者之间高度纠缠。
- 同时标记有情感和风格的表现力语音数据缺乏。
- 在实际应用的非并行迁移场景中的不匹配问题,即推理期间的新文本内容与训练数据中选择的参考信号不同,导致性能下降。
针对这些挑战,本文提出了一种基于两阶段的表现力语音合成方案,借助不同说话人的表现力数据,达到说话人、风格和情感的多因素解耦的效果,在目标说话人在没有表现力标注训练数据的情况下,实现其兼具风格和情感的合成语音。本文系统包括一个文本到风格和情感(Text2SE)的模块和一个风格和情感到波形(SE2Wave)的模块,通过神经网络瓶颈(BN)特征作为两者之间的桥梁。为了解决多因素解耦问题,采用多标签二进制向量(MBV)和互信息(MI)最小化来分别离散化提取的嵌入(embedding),在Text2SE和SE2Wave模块中解耦风格、情感和说话人因素。此外引入一种半监督训练策略,利用来自多个发音人的表现力数据,包括情感标注数据、风格标注数据和无标注数据。为了消除非并行迁移中的不匹配问题,通过引入参考候选池(reference pool),提出一种基于注意力机制的参考选择方法。本文方法可以实现语音中风格、情感、说话人音色的解耦与重组,合成目标说话人极具表现力的语音。
2. 提出的方案
如图3所示,本文以瓶颈层特征(BN)、基频、能量作为中间表征,将模型分为两部分:文本到风格和情感(Text2SE)模块和一个风格和情感到波形(SE2Wave)模块。其中基频、能量采用句级归一化,使其尽可能与说话人无关。在中间表征的帮助下,三因素之间的解耦可以简化为两两之间的解耦,降低了任务难度并使其更加可控。
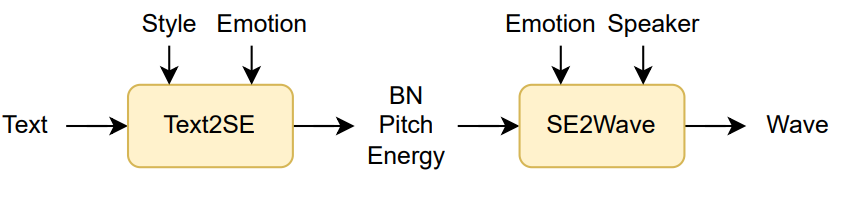
Text2SE: 如图4所示,该模块用于建模风格和情感。本文从参考音频中提取风格和情感表征。为了实现风格与情感的解耦,本文首先对提取的表征加分类器进行约束,使其倾向于表征情感或风格。其次,本文使用多标签二进制向量(Multi-label Binary Vector, MBV[3])对提取的表征进行压缩,其作用类似于瓶颈层,过滤不必要的内容。最后,本文使用基于变分对数上界(variational contrastive log-ratio upper bound, vCLUB[4])的最小化互信息(mutual information minimization, MI)对风格表征和情感表征进行解耦。
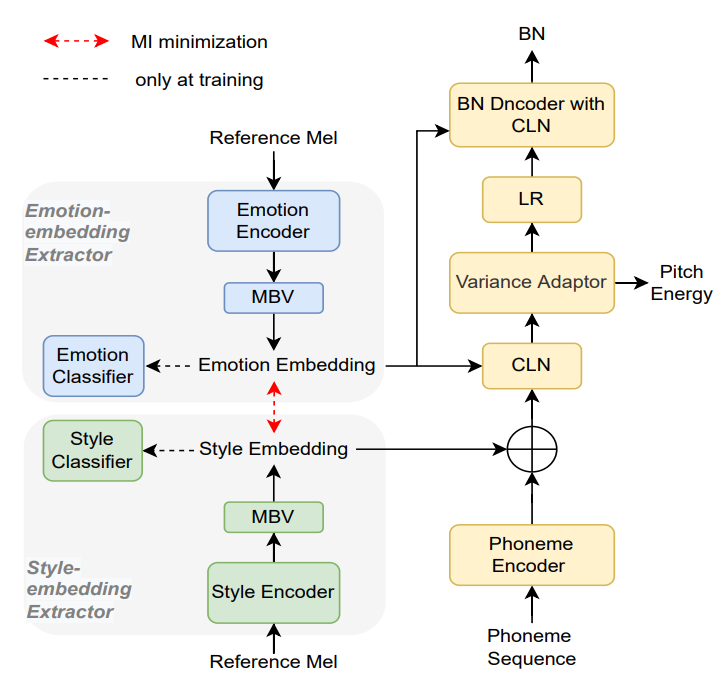
图4 Text2SE模型结构
SE2Wave: 如图5所示,该模块用于建模情感和说话人。本文从从参考音频中提取情感表征并加以分类约束,从说话人ID中获取说话人表征。对情感和说话人表征本文同样使用MBV进行压缩,MI进行解耦。考虑情感不仅是文本相关的,同时也是声学相关的,因此本文在SE2Wave中建模情感细节。
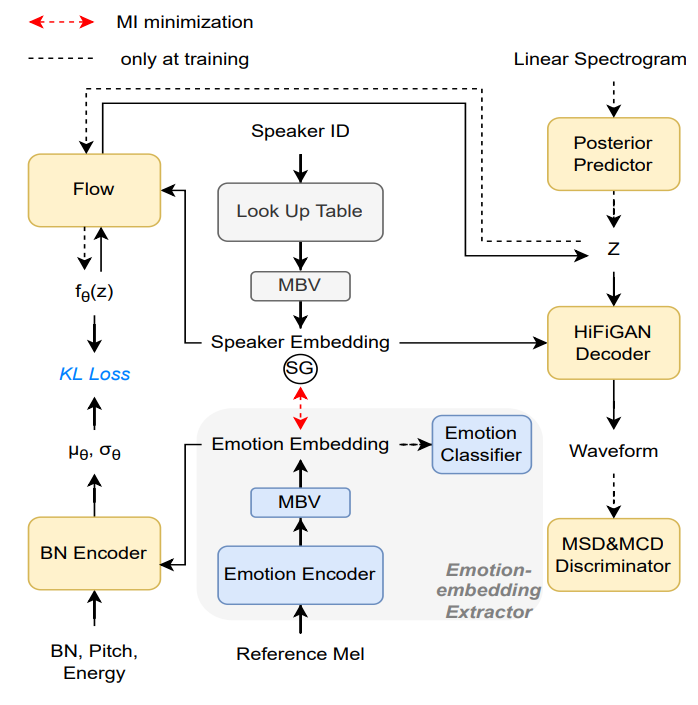
图5 SE2Wave模型结构
半监督训练: 让每一位发音人录制所有的风格和情感是不现实的,相比之下,收集情感标注数据集、风格标注数据集、无标注数据集(目标发音人)是更容易的。因此为了更好的利用数据,我们使用半监督的分类约束。本文只有对有标注数据计算交叉熵损失,对于无标注数据让模型自行决定风格和情感的种类。
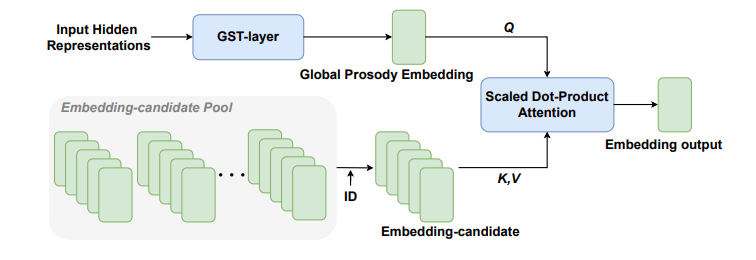
基于注意力机制的参考音频选择:基于参考音频编码器的语音合成模型在训练的时候,参考音频和文本是匹配,即语音和文本是对应的,然而推理的时候参考音频和文本通常是不匹配的(即平行迁移),导致模型表现下降。本文需要同时从参考音频中获取风格和情感,该现象会更加严重。因此,我们在Text2SE和SE2Wave训练完毕之后,提取训练集音频的表征,每个风格、情感种类随机挑选N个表征组成参考候选池(reference candidate pool)。设计如图6所示的表征提取器,从风格或情感候选池中通过scaled dot-product attention [5]隐式匹配出符合当前文本的风格或情感表达。
方法流程:本文方案分为训练、微调和推理三个阶段。
步骤一:训练。以公式(1)~(3)为目标训练Text2SE和SE2Wave。

步骤二:微调。提取参考音频表征,组成参考候选池,用表征提取器替代风格提取器和情感情感提取器并进行微调。
步骤三:推理。输入文本、风格ID、情感ID、目标说话人ID,模型自动匹配符合当前文本的风格和情感表达,并生成目标说话人音色的语音。
3. 实验
实验数据:实验数据来自三个数据集。1)M30S3共有30位说话人,3种风格(诗歌朗诵、童话故事、小说),总计18.5小时。2)M3E6共有3位说话人,六种情感(愤怒、害怕、高兴、悲伤、惊喜、中性),总计21.1小时。3)M30U共有30位说话人,无风格情感标注,总计18.2小时。
对比系统: 对比方案包括两个,一个是MR-Tacotron[6],HiFi-GAN声码器将生成的梅尔谱还原成波形。另外一个是Referee[7],在Text2Style中增加了风格建模。主观测试:主观测试包含四个方面—整体自然度、情感相似度、说话人相似度、风格相似度。四项均采用了MOS打分的方式。如表1所示,提出的方法取得了最优的自然度,验证了提出的方法可以匹配适合当前文本的风格和情感表达。此外,提出的方法同时获得了最高的情感、音色、风格相似度,反映出其有效地解耦了情感、音色、风格,并实现了重组。
表1 语音自然度、情感相似度、说话人相似度和风格相似度主观测试结果(MOS)
客观测试:客观测试包含两个方面——字错误率和说话人余弦相似度。表2中的结果可以看出,提出的方法获得了最高的说话人余弦相似度,与主观实验相符。此外,由于通用语音识别模型对诗歌题材的语音识别性能不佳,因此整体字错误率偏高。考虑到提出的方法整体表现力较高,比MR-Tacotron的字错误率略高是合理的。
表2 字错误率、说话人余弦相似度客观测试结果(MOS)
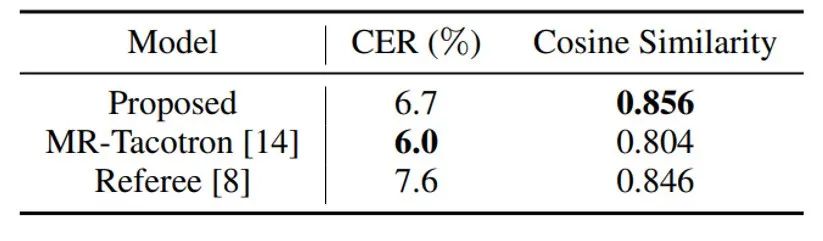
可视化分析:可视化分析包括对提取表征的聚类分析与统计分析。聚类分析如图7所示,Text2SE中风格和情感表征聚类效果较好,显示了半监督的有效性。SE2Wave中情感聚类效果一般,我们推测是SE2Wave中情感主要是捕捉Text2SE中没有关注到的情感细节,因此有所不同。统计分析如图8所示,计算了提取表征每一维度的标准差,灰度越浅,标准差越小;纯白表示方差为零,表示这一维度没有被使用。由图可知,每个表征都有纯白的维度,表示这些维度没有被使用,这反映出MBV避免了不必要内容泄露的能力。此外图中(a)与(b)基本互斥,体现出Text2SE中风格和情感是解耦的。

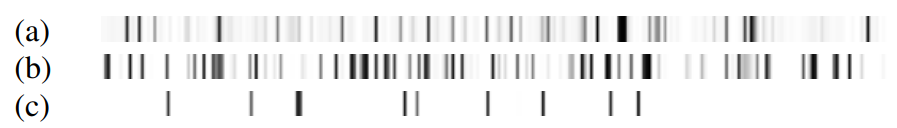
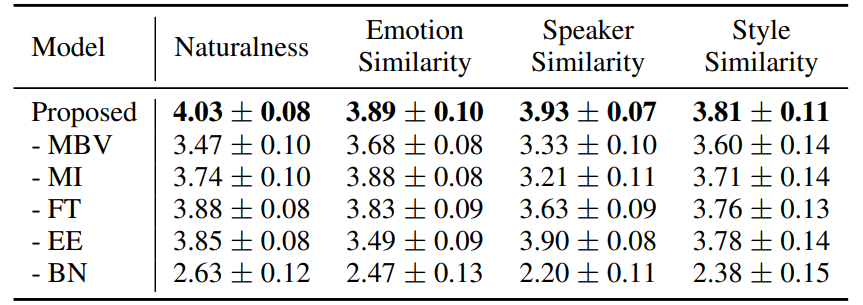
消融分析:如表3所示,我们对模型中不同组件进行消融分析。去除MBV或MI会使音色相似度大幅度下降,降低模型解耦能力。移除微调过程,模型不能消除训练和推理的不匹配问题,整体表现下降。去除SE2Wave中的情感模块,情感相似度大幅度降低,验证了情感细节建模的必要性。此外,移除中间表征进行联合训练,模型失去解耦与重组能力。
表3 消融实验结果
参考文献
[1] Yi Lei, Shan Yang, Xinsheng Wang, and Lei Xie, “Msemotts: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 853–864, 2022
[2] Tao Li, Xinsheng Wang, Qicong Xie, Zhichao Wang, and Lei Xie, “Cross-speaker emotion disentangling and transfer for end-to-end speech synthesis,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 1448–1460, 2022.
[3] Andy T. Liu, Po-chun Hsu, and Hung-yi Lee, “Unsupervised end-to-end learning of discrete linguistic units for voice conversion,” in Proc. Interspeech. 2019, pp. 1108–1112, ISCA.
[4] Pengyu Cheng, Weituo Hao, Shuyang Dai, Jiachang Liu, Zhe Gan, and Lawrence Carin, “CLUB: A contrastive log-ratio upper bound of mutual information,” in Proc. ICML. 2020, pp. 1779–1788, PMLR.
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Proc. NIPS, 2017, pp. 5998–6008.
[6] Yanyao Bian, Changbin Chen, Yongguo Kang, and Zhenglin Pan, “Multi-reference Tacotron by intercross training for style disentangling, transfer and control in speech synthesis,” 2019, vol. abs/1904.02373
[7] Songxiang Liu, Shan Yang, Dan Su, and Dong Yu, “Referee: Towards reference-free cross-speaker style transfer with low quality data for expressive speech synthesis,” in Proc. ICASSP. 2022, pp. 6307–6311, IEEE.
以上文章来源于音频语音与语言处理研究组 ,作者朱新发
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
