
编者按:随着Google Cloud等基础设施更加成熟,通过使用更加廉价的竞价实例,可以大幅的降低成本。通过开发新的基础设施管理平台——Falkor,Vimeo的运营成本也大幅降低了。
文 / Quentin Mazars-Simon
原文 / https://medium.com/vimeo-engineering-blog/riding-the-dragon-e328a3dfd39d
译 / 核子可乐 https://mp.weixin.qq.com/s/PmLOBdq3UTssCDqIZ0uFVA
Vimeo发布新转码基础设施Falkor——降低成本的同时将速度推向极限。
Vimeo的下一代转码基础设施Falkor现已登场,标志性的形象是充满上个世纪80年代风格的狗头龙身。它不仅比前代方案更快、更可靠,也拉开了通往云原生未来的序幕。关于Falkor的一切,本文将为您一一揭晓。
从历史说起
Falkor的前任方案是Tron转码技术栈,这套技术栈可以追溯到2013年。Tron具有以下特点:
• 能输出带有音频和视频的渐进式MP4格式。
• 会将整个源文件下载到本地,将其转码为所需的profile,再将结果上传至云存储。
Tron是为前云时代的Vimeo所量身打造,当时我们还在运营自己的数据中心(也配合使用一部分竞价实例以优化运营成本)。但如今,我们已经全面转向Google Cloud。
尽管Tron已有10年历史,但我们并不打算让它彻底“退休”。某些Falkor无法处理的极端情况,还是要劳Tron的大驾。关于更多具体情况,我们将在后文中详细介绍。
为什么选择Falkor?
这套全新基础设施的雏形发源于2011年,甚至比Tron的诞生还要早。但我们直到2019年底才在这个方向上全面发力,希望借Falkor项目达成以下几个目标。
将原始源文件直接作为输入
这一点属于对Tron开发工作的延续,希望尽可能使用原始源文件作为转码输入,从而最大限度提升输出质量。毕竟夹层文件是转码的产物,而转码本身是个有损过程。所以跟直接使用原始源文件相比,使用夹层作为后续转码源会降低视频质量。
实现并行化和分布式转码
并行化与分布式转码的本质,就是把视频拆分成一个个更小的片段,分别在我们的服务器上进行转码。在完成所有转码之后,再把各片段组合起来以创建最终输出(参见图一)。这样不仅转码速度更快,从错误中恢复的能力也更强。
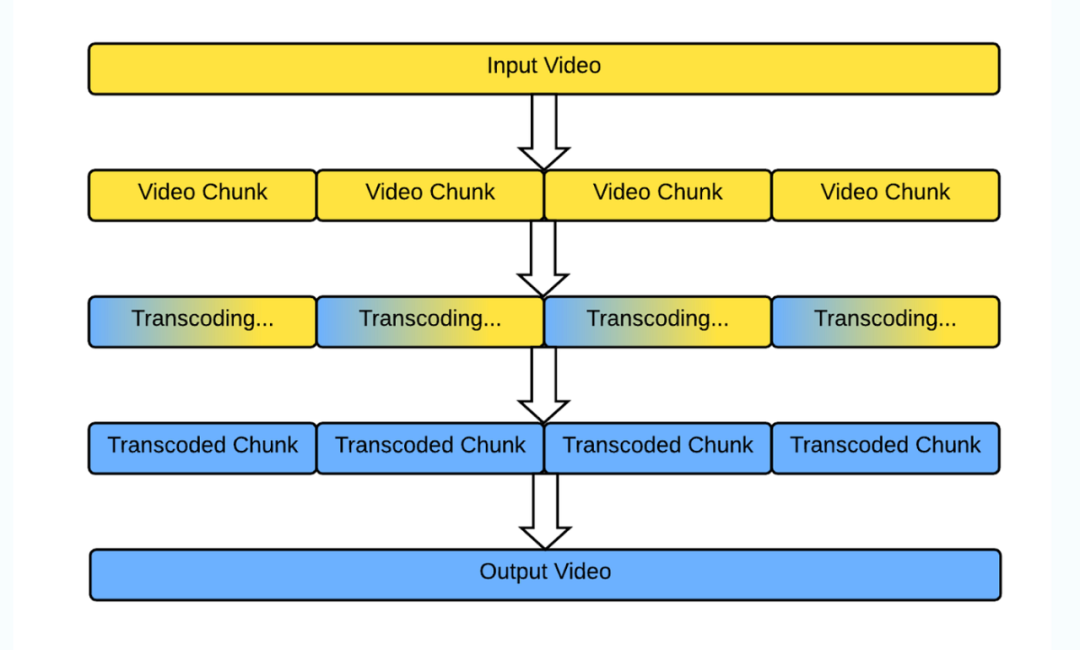
我们希望新的基础设施能继续使用成本低廉的临时竞价实例,延长旧有Tron设施的使用周期。竞价实例不提供容量保证,但成本比按需实例低得多,价格普遍在后者的50%以下,也有助于对可用资源的快速变化做出响应。在Vimeo的用例中,使用竞价实例意味着某些转码作业会被中途取消;但配合并行化与分布式转码,只需重新执行一小部分即可顺利完成视频转码。
此外,Google等云服务商大多支持按秒(首分钟之后)支付实例费用。也就是说,运行单一实例1个小时和运行10个实例各6分钟,其资源价格基本相当,但并行转码的总体耗时会短得多。
迈向云原生
之前提到,Tron是专为前云计算时代的Vimeo所设计,那时候的云环境还有很多问题,所以立足本地基础设施是个非常合乎逻辑的选择。但现在既然决定上云,我们当然要充分利用云服务商提供的方案。这样能大大削减需要自主管理的本地基础设施,但代价就是我们得提防别陷入供应商锁定的陷阱。一旦过度依赖当前云服务商的复杂技术体系,那么我们后续会很难迁移至其他云服务商。
尽可能使用竞价实例
如前所述,使用竞价实例有助于降低成本,同时不会显著影响转码时间。
将音频和视频分别存储,生成碎片化的MP4输出
将音频和视频分别输出,让我们得以轻松访问音频和视频流。
如果音频只需要被提取和存储一次(而非与视频混合或合并),那我们的打包压力就会小得多,也能节约存储成本。(传统上,音频和视频会被存储在同一文件内,导致不同视频质量或还原度版本中都要单独保存一份音频。)
使用碎片化视频,我们可以轻松将视频文件切割成多个片段,这种存储方式能降低打包程序的运行难度。
但这里也有新的权衡,音频与视频拆分会提高渐进式文件的交付难度,挑战我们将音视频即时合并的能力。
使用标准工具进行开发和部署
为团队和公司内其他部门提供一组类似的工具(语言、库、编排等)服务,确保我们的基础设施更易于维护、充分发挥其他服务和团队的产出成果,从整体上降低设施复杂性。
Tron仍依赖于Python 2等已被弃用的技术。
Falkor宏观架构解析
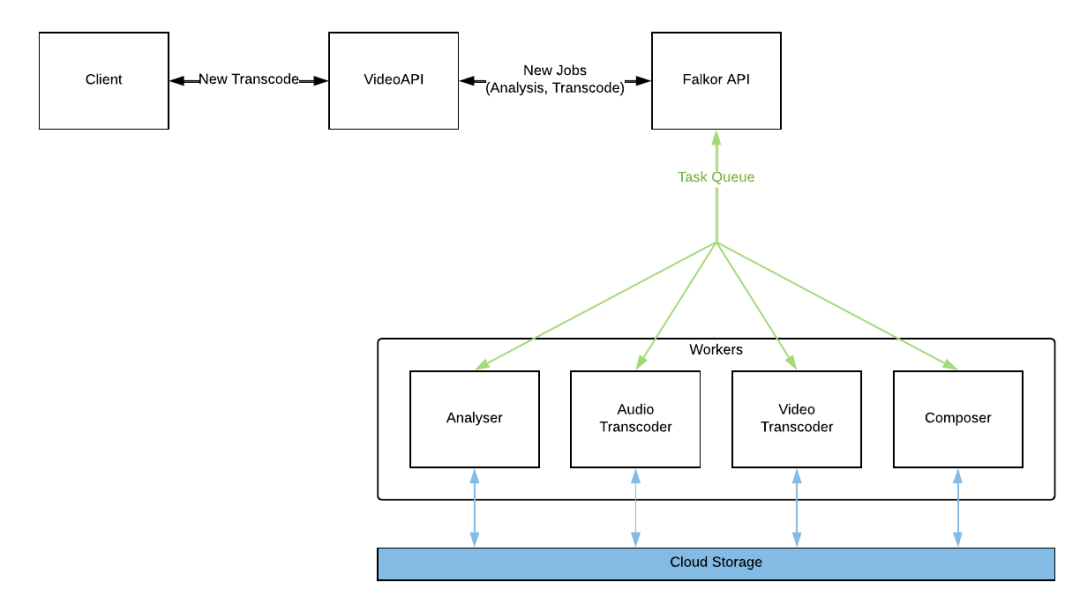
下面,我们用图文详解的方式聊聊Falkor的宏观架构。图二所示,为Falkor各组件与其他服务间的交互关系。
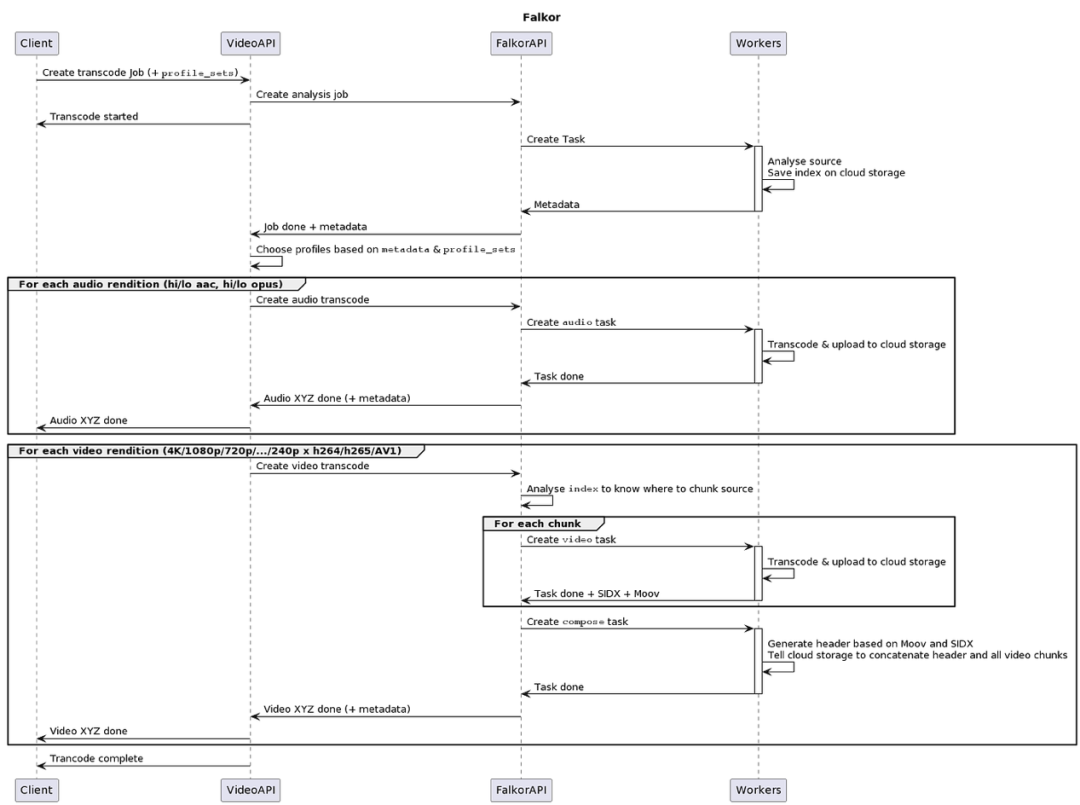
图三所示,为Falkor作业的端到端流程。
下面是Falkor的具体转码步骤。
步骤1
客户端通知我们的视频API使用profile集列表,对视频数据进行转码。Profile集的确切列表视具体用例而定。例如,并非所有视频都可使用AV1格式。
步骤2
我们的视频API会执行一系列检查,包括获取视频源位置、要求Falkor API运行分析作业等。检查会返回元数据,包括视频时长、编解码器、帧率、视频是否为HDR等。这些元数据将被放入云存储,以供后续转码作业重复使用。
步骤3
视频API从分析作业处接收元数据,并确定需要运行哪些转码音频和视频profile:使用哪些分辨率、是否启用HDR等。这些profile各自拥有对应的新Falkkor API作业。
音频作业在音频转码工作器上运行,该工作器负责对源音频进行转码,而非在本地下载再将转码结果上传至云端。
视频作业稍微复杂一些。根据用户所上传源视频的索引和其他元数据,Falkor API将确定视频的拆分位置,理想状态下是分割成时长约1分钟的片段。如果无法分割视频,则回退至Tron对源视频做整体处理(后文将讨论具体细节)。每个片段均由各视频转码工作器做并行转码,根据由源文件分配的视频片段获取所需的字节范围,之后将结果上传至云存储。
当所有片段均处理完成后,Falkor API会创建最终的合并作业。该作业会根据各片段的标题头生成视频标题头,例如moov和SIDX,再将此标题头与所有片段连接起来,最后将合并完成的视频存储在目标位置。在我们的云服务环境下,只需调用云存储API即可完成最后一步(详见下文)。
步骤4
以上步骤完成后,Falkor AIP会告知视频API工作已完成。视频API将新的音频或视频文件添加至视频管理系统,再将完成消息通知客户端。
每个单独作业都有自己的通知过程,可帮助客户决定如何按业务逻辑采取行动。例如,客户端允许在H.264视频组件之一和AAC音频组件之一准备就绪后,立即开始播放视频;或者,客户端也可以等待所有转码均完成后再行播放。客户端还可触发其他处理任务,例如为视频内容生成缩略图。
技术细节
从技术栈的角度看,所有作业均在Google Cloud三个美国区域的Kubernetes(GKE)上运行。在队列方面,我们使用的是PubSub。Falkor本身由Go编写,转码器则用C语言编写。
Falkor还用到了我们的作业调度程序Quickset,让我们能够通过以下两种方式降低成本:
• 能在可用的CPU和内存资源范围之内,有效将任务分配给各工作器,在尽可能减少CPU闲置的同时、仍为突发事件保留一部分空间。
• 能够自动缩放Kubernetes节点,并根据竞价实例优先级做任务安排,保证只在真正必要时才回退至非竞价实例。
但要让Quickset有效分配任务,必须保证各项任务的时长和所需的资源量大致相同。为了实现这一点,我们将任务排入不同队列。任务分析主要根据大小进行,因为我们找不到更好的近似值选项。音频任务按持续时间和编解码器做分析,这是因为我们不会对音频做片段拆分,所以不同文件的持续时长会有很大变化。视频任务则按还原度和编解码器划分,因为视频片段的持续时间是恒定的,每段大约一分钟。
发布流程
我们在整个发布过程中始终小心谨慎。毕竟在快速迭代的同时,我们也要保证尽量减少对用户体验的干扰。
我们首先将一小部分H.264 240p转码发送至新基础设施,原因如下:
• 这种还原度的视频不会通过UI或API向用户公开,仅面向内部播放器或外部播放列表,所以即使出现问题也不会造成太大影响。
• 我们可以借此引导流量并调整比例,不必担心突然对用户造成严重影响。
• 我们可以在此期间构建并集成零散的音频和视频数据管线,借此重新组合渐进式文件。
我们还做了一些微小调整,修复了一些bug并解决了缩放问题。当240p视频全部由新基础设施承载之后,我们开始向其发送AAC和Opus格式的音频,意味着Falkor开始处理部分实际业务流量。
之后我们转向H.264 1080p,这种还原度的视频能让我们轻松验证视觉质量是否符合预期,也是用户使用最多的视频格式。万一出现问题,我们会很快得到反馈。虽然我们在内部做了一遍又一遍测试,但每当实际处理用户上传的内容时,总会冒出意料之外的有趣极端案例。
在1080p之后,我们对新基础设施的规模伸缩和输出质量已经充满信心,于是决定引入全部其他H.264格式:4K、2K、720p、360p等,后续还将转移360º视频和用于HDR10及杜比视界的HEVC视频。
但在撰写本文的同时,我们还有不少转码任务没有迁往Falkor:
• 具有可变帧率源的视频。我们打算暂时搁置这部分极端案例,等到之后能轻松发现帧率问题时再迁移比较安全。
• AV1。其实这里没有任何技术障碍,我们只是不想过于贪多。除了极少数内部精选的视频外,我们还没有迁移AV1。事实也证明,这种格式确实需要投入更多精力来整理。
• 在网络上存量较少的源视频。对这部分视频,我们还是采取将源文件下载到磁盘上的老办法。
升级总结
我得说,这项工作推进得相当顺利。当然,期间也出现了一些与视频相关的bug(我们已经向上游发布了相关补丁)和基础设施问题。
首先,我们需要在单独的Kubernetes集群中运行AIP和工作器。这是因为一旦集群中的节点超过1000个,GKE Ingress就无法工作。但现在这个限制已经解除了。
第二,Google Cloud的VPC原生集群中,每个pod都有自己的IP地址。而且因为我们有很多很多pod,所以不想把这个集群与Vimeo的其余基础设施并列部署,毕竟我们已经占用了太多的10.x.x.x内部IP资源。但我们将Cloud NAT设置为仍能与基础设施的其余部分通信,例如我们的可观察性服务。
第三,我们的一部分状态机无法妥善处理重复消息。Google Cloud的Pub/Sub提供“at-least-once”(至少一次)交付保证,但并非“exactly-once”(严格一次)。所以我们被迫重写了一些代码块以使其更具弹性,并会在后续编写新代码时考虑到这个问题。
第四,为了保证可用性,我们在美国三个区域同时运行,所以拉高了出口成本。
升级的回报
简单来讲:成本下降、速度加快。在类似的用例下,Falkor的运营成本远低于Tron,而且我们还有更进一步的调优空间。
此外,虽然Falkor并没有解决所有问题(短视频的转码方式和用时仍跟过去一样),但长视频的转码速度确实大大加快。用户们纷纷给出好评,所以我们的“折腾”也就物有所值了。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
