
研究背景:随着网络科技的不断进步,短视频的个性化推荐,会议的录音记录等相关的音频信息在我们的生活中扮演着越来越重要的作用。如何能在海量的语音信息中,准确的进行语音信息的分类和定位,从而减少我们获取信息的时间变得尤为重要。因而语音主题分类(Speech Topic Classification, STC)快速发展。
论文题目:
SPEECH TOPIC CLASSIFICATION BASED ON PRE-TRAINED AND GRAPH NETWORKS
作者列表:
牛方静,曹腾飞,胡英,黄浩,何亮
本文方案
目前常见的语音主题分类系统由两部分级联而成,先由自动语音识别(Automatic Speech Recognition, ASR)将语音转换成文本,再通过自然语言处理进行文本主题分类。大多数存在错误传播和全局结构缺失等问题。所以在本文中,我们提出了一种基于预训练模型和图网络的端到端新型框架。使用预训练模型提取顺序上下文的语义特征代替声学特征,并且与图网络构建的会话语境的全局特征相结合在Fisher数据集上取得了良好的效果。
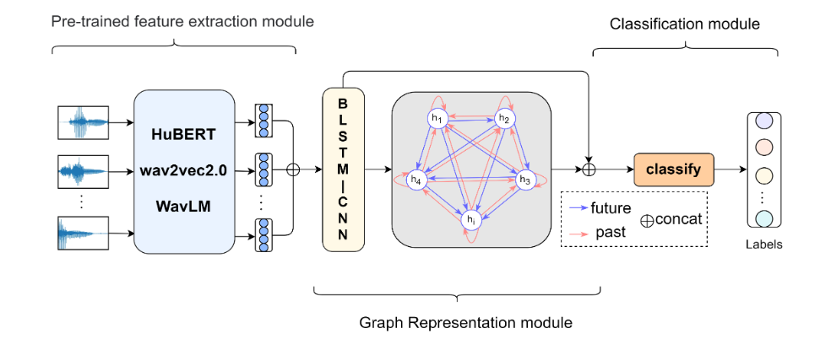
图1 模型框架主要有三个部分构成:预训练特征提取层,图表示层和分类层
预训练特征提取层
由于前人的研究大多是基于语音的声学特征,然而声学特征只能够捕捉到很短时间内的局部时频信息,对于像语音主题分类这类需要理解长时间语音信息的研究存在缺陷。所以我们采用预训练模型提取具有顺序结构的高维语义特征代替声学特征。使用的是目前流行的三个预训练模型:HuBERT[1]、wav2vec2.0[2]和WavLM[3]。
图表示层
我们提出了会话语境的概念,将高维语义特征构造成图数据结构。主要从三个方面构建图表示层:一是中心节点的选择;二是感受域的大小;三是处理邻居节点的特征。首先将语义向量转化成话语向量构造成节点,其次对中心节点采用上下文滑动窗口构建边,最后通过注意力机制给与中心节点特征相识度高的邻居节点分配更大的权重使它们在空间上更聚合。最后通过图卷积神经网络[4]提取全局特征。
分类层
将通过预训练模型提取的顺序上下文的语义特征和通过图网络学习的会话语境的全局特征相结合进行分类。
实验结果分析
实验使用了Fisher数据集对上述模型方案展开训练和测试,表1列出了对比的级联形式的模型,表2列出了端到端形式的模型。
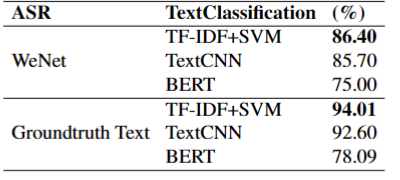
表1 不同级联形式的表现
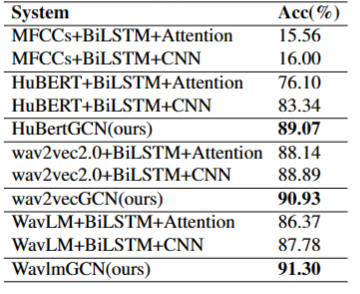
表2 不同端到端形式的表现
通过对比可知我们提出的方法优于使用WeNet[5]转录的文本通过TFIDF+SVM的级联形式方法,也优于其他的端到端方法。同时WavlmGCN接近于真实文本分类效果(94.01%)。由此可见端到端形式的分类在一定程度上缓解了ASR的转录错误对后续分类造成的影响。同时在对长时间的语音文档理解时,既需要关注局部的顺序语义特征又需要关注会话语境的全局特征,从而使语音主题分类达到更好的效果。
小结
我们通过将预训练模型提取的具有顺序结构的语义特征和图网络提取的会话语境的全局特征相结合在语音主题分类上得到了良好的效果。据了解在该领域,我们是第一个提出会话语境的概念并且使用图网络来构建语音中这种非连续的全局结构。在以后的研究中我们将通过对语音结构信息更深入的挖掘,在语音主题分类上达到甚至超过真实文本的分类效果。
参考文献
[1]Wei-Ning Hsu, Yao-Hung Hubert Tsai, Benjamin Bolte, Ruslan Salakhutdinov, and Abdelrahman Mohamed, “Hubert: How much can a bad teacher benefit asr pre-training?,” in ICASSP 2021 – 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6533–6537.
[2]Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, Eds. 2020, vol. 33, pp. 12449–12460, Curran Associates, Inc.
[3]Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
[4]Christopher Morris, Martin Ritzert, Matthias Fey, William L Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe, “Weisfeiler and leman go neural: Higher-order graph neural networks,” in Proceedings of the AAAI conference on artificial intelligence, 2019, vol. 33, pp. 4602–4609.
[5]Binbin Zhang, Di Wu, Chao Yang, Xiaoyu Chen, Zhendong Peng, Xiangming Wang, Zhuoyuan Yao, Xiong Wang, Fan Yu, Lei Xie, and Xin Lei, “Wenet: Production first and production ready end-to-end speech recognition toolkit,” CoRR, vol. abs/2102.01547, 2021.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
