
本文介绍了 AVX-512 在 FFmpeg 中的应用。首先,本文介绍了 AVX-512 的基本信息,包括它与 SIMD 指令集的关系、其特点和新型指令。接着,本文探讨了 AVX-512 在早期 CPU 中的性能限制问题以及随着新处理器的推出而得以解决的情况。此外,还介绍了 AVX-512 指令集在多媒体中的应用,包括排列、变量移位和位选择等。通过 AVX-512 指令集,可以实现以前不可能实现的通道交叉技术,从而提高代码性能。最后,文章提到下一个需要考虑的问题可能是视频或图像的交错扫描。
来源:FOSDEM 2023
链接:https://fosdem.org/2023/schedule/event/om_avx512/
主讲者:Kieran Kunhya
内容整理:陈予诺
什么是 AVX-512?
AVX 指“Advanced Vector Extensions”,意为高级矢量扩展技术。它是一种由英特尔开发的 SIMD(Single Instruction Multiple Data,单指令多数据)指令集,近期也开始适用于 AMD CPU。与上一代相比,AVX-512 具有更大的 512 位寄存器大小,并且加入了许多新型指令,包括新的 opmask 指令、比较指令等等。此外,AVX-512 还包括其他与多媒体不太相关的功能,例如加密和神经网络。
可能你会好奇为什么现在才开始讨论早在 2017 年就已经问世的 AVX-512。这是因为支持 AVX-512 的英特尔第一代 CPU 是 Skylake,但当它使用这些指令时会出现显著的性能限制,导致 CPU 速度大幅下降。在高性能计算领域,通常需要执行大量的计算任务,并且这些计算任务可以被完全优化为使用 AVX-512 指令集。由于这些任务通常需要大量的计算资源,并且在处理过程中可以使用所有可用的 CPU 资源,因此在这种情况下,即使在 Skylake CPU 上使用 AVX-512 指令集也可以获得很高的性能。相反,对于混合使用汇编和 C 代码的多媒体领域,任务通常比较复杂,并且不一定始终可以使用 AVX-512 指令集。因此,在 Skylake CPU 上使用 AVX-512 指令集可能会导致性能下降,所以这些指令的使用仍然相对较少。然而,随着第 10 代和第 11 代 Ice Lake 处理器的推出,这些处理器不再受到 AVX-512 的性能限制,因此基于 ZMM 寄存器的指令可以成为一流的指令。
近年来,访问支持 AVX-512 的设备一直是一个挑战。尽管 AVX-512 具有更大的寄存器和更多的指令,但并不是所有的设备都支持这种指令集。一些 CPU,如 AMD Zen 4 和部分云服务器供应商的 CPU 仍然支持 AVX-512,例如 AWS。
需要注意的是,从第 12 代 CPU 开始,英特尔已经移除了对 AVX-512 的支持。因此,如果需要使用 AVX-512,最简单的方法是购买一款第 11 代英特尔 CPU,它非常安静,并且提供完整的 AVX-512 堆栈。
在多媒体领域中,已经有一些使用 AVX-512 的工作。例如,Dav1d 是一个针对 AV1的跨平台开源解码器,它于一两年前添加了 AVX-512 支持,这对于 AV1 特别有益,因为它比更传统的编解码器如 H.264 和其他编解码器具有更大的块大小。在 Dav1d 中使用 AVX-512 可以提高整体解码性能,而不仅仅是在特定函数中。对于那些需要处理大量视频或需要快速处理高分辨率视频的人来说,使用 AVX-512 具有很大的好处。
FFmpeg 中的 AVX-512
在 FFmpeg 中,我们使用 Dav1d 以及经典的 FFmpeg x264 汇编方法来处理视频数据。这些方法不依赖于内置函数、内联汇编或特殊库,而是使用原始的汇编语言进行手动优化。此外,我们不会编译它们并强制您使用特定的 CPU 代。与此相反的例子是,MongoDB 在某些情况下会强制使用特定的 CPU 代,这可能会引起争议。在 FFmpeg 中,我们检测 CPU 功能,并使用函数指针来执行代码,以确保它们在可用的 CPU 上实现性能最大化。虽然英特尔的 CPU 功能具有复杂的交错关系,但实际上,我们只需要关注与 AVX-512 相关的功能。
CPU flags in FFmpeg
这些是在 FFmpeg 中使用的 CPU 标志(flags)。与 AVX-512 相关的标志大致可以分为传统的 Skylake 和更新的 ICL 两类,其中用粗体表示 Ice Lake。可以看到实际上有许多不同的子类别,但目前只能选择其中一个。也就是说,不同的 CPU 可能具有不同的 AVX-512 子集,但在使用时必须选择适用于该特定 CPU 的子集,不能同时使用多个子集。然而,英特尔以添加和删除功能而闻名,甚至可能为某些功能收取订阅费。因此,这意味着将来的新功能可能需要订阅或付费。

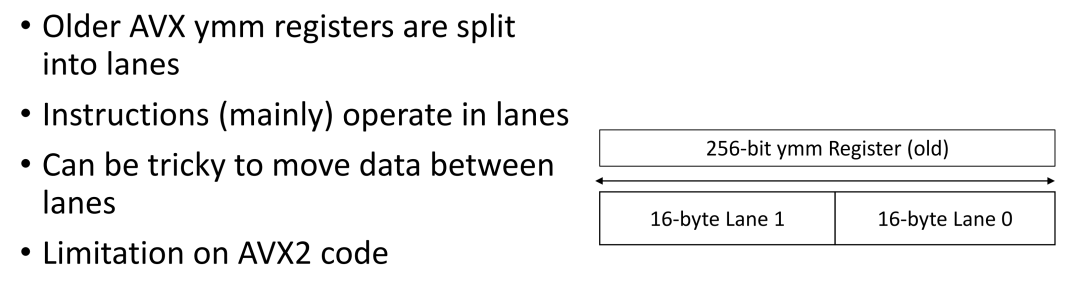
Lanes
在旧版 AVX 指令集中,寄存器的大小为 256 位(32 字节),并且被分成了四个 32 位的通道(Lane),每个通道都可以存储一个 32 位的浮点数或整数。指令在这些通道中操作数据,但要在通道之间移动数据相对困难。因此,为了执行某些操作,需要进行通道交叉和各种技巧来补偿这些通道,这实际上会消耗 CPU 周期并占用时间。后来的 AVX-512 指令集使用了更大的 512 位寄存器,它们被分成更多的通道,可以更有效地进行数据操作。
K-mask registers
AVX-512 引入了一组名为 K 掩码寄存器(K-mask registers)的新寄存器,从 K0 到 K7。K 掩码寄存器是一种新的寄存器类型,它可以用来在执行指令时对目标寄存器进行保护。在 AVX-512 之前,当执行指令时,寄存器的值通常会被覆盖,这意味着您需要在执行指令之前将寄存器中的值保存到内存中,然后在指令执行后再从内存中恢复这些值。这会增加程序的开销并降低性能。而使用 K 掩码寄存器可以避免这种情况的发生。
具体来说,使用 K 掩码寄存器,您可以通过掩码来保护目标寄存器中的某些位。掩码是一组二进制值,它指示哪些位可以被修改,哪些位应该保持不变。当指令需要修改目标寄存器中的位时,它会根据掩码来判断哪些位可以被修改,哪些位需要保持不变。这样,您可以在不覆盖寄存器中其他值的情况下,修改目标寄存器中的部分位。
此外,K 掩码寄存器还可以用于强制某些元素为 0 或 1。这对某些特殊的应用场景非常有用。通过使用K掩码寄存器,您可以在 AVX-512 指令集上实现更精细的控制,从而提高程序的性能和效率。Dav1d 就很好地利用了 K-mask registers。

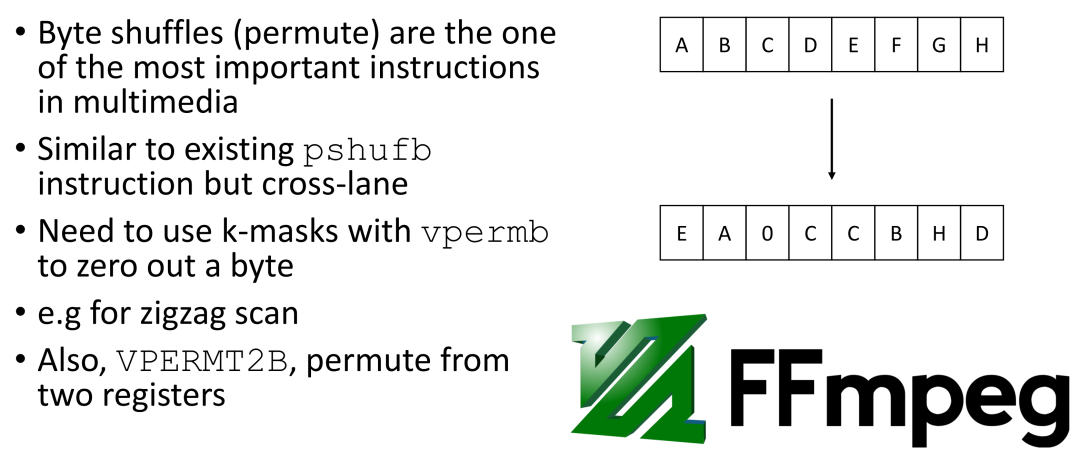
Vpermb
在多媒体中,洗牌(shuffles),也称为排列(permute),是最重要的指令之一。如图所示,洗牌可以让您以任何想要的方式重新排列各种数据位,复制它们,甚至将单个元素设置为 0。其中一个用例是 FFmpeg 的 ZigZag 扫描,其用于将块中的系数按大小排序并将它们分组。
AVX-512 的 Vpermb 指令是一个新的指令,它可以跨越通道,这在以前是不可能的。在许多情况下,Vpermb 可以提高性能。Pshufb 可能是所有开源多媒体中最常用的指令之一,因此在代码中,您可以看到许多 pshufb 指令。Pshufb 的一个有用的特性是,如果将索引设置为负一,您可以自动执行清零操作。不过,使用 Vp2B 指令时,您必须使用 K 掩码来清零。
AVX-512 提供了许多其他有趣的排列指令,例如 Vp2B。Dav1d 就很好地利用了它。使用 Vp2B 指令,您不仅可以对一组数据进行排列,还可以从两个不同的寄存器中提取数据,并将它们混合后输出。
Variable shift
变量移位(variable shift)是另一个有趣的特性。通过 AVX-512,您可以进行变宽移位。举一个例子:VpsrlvW 是逻辑右移位,VpsllvW 是变量左移逻辑。在编写幻灯片和代码时,这些术语混用非常容易混淆。历史上,进行变量移位相当复杂。人们使用各种技巧和习惯用法来模拟移位,但是它们存在限制。例如,在某些技巧中,不允许移位 0,因此如果您需要 0 移位,必须采用其他方式。但是现在有了 AVX-512,您可以使用这些变量移位指令,它们更易于使用。同样,在左移方面,相比于使用乘法的低效模拟方法,这些指令实际上更快,因此仍然具有优势。

Vpternlogd
Vpternlogd 是 AVX-512 中非常强大的一条指令,这个指令可以做出很多惊人的事情。您可以在一个指令中编写一个真值表,并且在理论上可以替代多达 8 个不同的指令。关于 Vpternlogd,有很多可以探讨的话题,但接下来将重点介绍它最简单的用法——三元操作。这是 C 语言三元运算符的按位等效操作。在每个寄存器中,每个位都被迭代,根据该位是否被设置,从两个选项中选择结果。如果您想了解更多关于 Vpternlogd 的信息,可以参考这篇文章。除此之外,位选择和多重操作也非常有趣。

Example
这里介绍的是 v210enc,它可能是 FFmpeg 中最简单的汇编函数之一。该函数的作用是从不同的内存位置获取 10 位样本,将它们扩展为 16 位,然后将这 3 个 16 位字打包到 32 位中。
这个函数有趣的地方在于,我们已经开始使用以前不可能实现的通道交叉技术。我们将 Y(亮度)样本加载到低 256 位中,将 U 和 V(色度)样本加载到高 256 位中。然后,一个单独的 vperm 指令可以一次性地重新排列所有内容。这在过去要复杂得多。Pmaddubsw 是一种技巧,用于乘法和加法运算,以模拟移位。我们使用它来将 U 和 V 值移动到正确的位置。但是,每个元素中存在一些位的取值相互矛盾,需要采取措施来解决这些矛盾,以便能够正确地对 U 和 V 值进行移位。具体来说,这些矛盾的位会影响到元素的某些位,在使用 Pmaddubsw 指令将 U 和 V 值移位时,需要解决这些冲突以确保结果正确。

接下来讲述的是位选择,之前需要使用 2-3 个指令才能完成,但现在可以使用单个 VPternlogd 指令完成。它基本上相当于 C 语言中的三元运算符,在其中,如果设置了某个位,则从一个寄存器中选择相应的位,否则则从另一个寄存器中选择相应的位。这提供了显著的速度提升,如基准测试所示。尽管这些基准测试不是非常完备,但它们确实显示出,即使在使用较短寄存器的旧硬件上,使用 AVX-512 也可以提供可观的性能增益。事实上,使用 VPBLENDB 和 ZMM 寄存器时,遗留的 AVX-512 代码的速度可以提高一倍,从而显著提高基于行或基于帧的处理过程(例如过滤或缩放)的性能。

这段内容包括了多个基准测试结果,其中涉及到位选择的优化。具体来说,基准测试结果显示使用 VPternlogd 指令实现的位选择比使用传统方法快得多,尤其是在较短的 ymm 寄存器上。此外,通过使用 Vpermb 和 ZMM 寄存器,基于 AVX-512 的代码速度可以提高一倍,比使用 AVX-512 YMM 寄存器快近一倍。最后,基准测试结果还表明,使用 AVX-512 指令集的 v210_planar_pack_8_avx512 代码比使用 C 语言实现的代码快了约 20 倍。
What AVX-512 code next?
主讲人认为下一步需要考虑的是视频或图像的交错扫描(interlacing),可能有涉及到比较(comparisons)操作的问题,尽管还没有详细讨论过比较,但代码中常常需要进行比较操作,这也是AVX-512得以应用的一个的领域。如在许多需要三元操作的情况下,我们几乎总是可以使用vpternlogd来代替它们。另外,在代码库中,有各种不同的惯用语和技巧来模拟变量左移和右移,例如对于左移使用乘法,对于右移使用逻辑移位。这些模拟可以通过使用一系列指令来实现。英特尔提供了官方手册,其中包含了非常详细的内容,对于了解指令的详细工作原理非常有用,但不幸的是,它并不容易理解。因此,有一些网站试图简化这些内容。主讲人认为这个网站非常好,虽然它是一个日本网站,但用英语编写,并且将所有功能按照某种逻辑顺序进行了分类,这使得理解变得更加简单。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
