
摘要:针对算力网络场景下的微服务调度问题,考虑了微服务对网络服务质量的需求和节点能耗优化问题,研究了算力网络场景下服务质量约束的能耗优化微服务调度问题。首先建立了由算力网络调度模块、算力网络调度执行模块和算力网络信息表构成的算力网络调度框架。基于该框架,同时考虑了节点资源限制和网络服务质量约束,建立了能耗优化的微服务调度模型,并采用深度确定性策略梯度算法解决该问题。最后通过仿真实验证明了该调度算法的有效性。
01 概述
算力是互联网时代的基础能源,正在驱动不同行业的信息化转型。目前,广受关注的云计算、边缘计算、人工智能计算等都属于算力的分支。随着产业信息化、数字化的不断深入,互联网、大数据、云计算、人工智能、区块链等技术不断发展与创新,海量的应用与技术创新对算力提出了新的需求,包括更大的算力供给、更高的计算性能标准和更多样的算力服务需求。因此,将算力与网络深度融合,实现云、边、端多级计算的高效协同部署是必然趋势。2021年5月24日,国家发展改革委、中央网信办、工业和信息化部、国家能源局联合印发了《全国一体化大数据中心协同创新体系算力枢纽实施方案》,文件提出要在全国各地布局建设全国一体化算力网络国家枢纽节点,加快实施“东数西算”工程,提升跨区域算力调度水平。
目前,业内将算力网络的发展主要分为算网分治、算网协同、算网一体化3个阶段。为了最终实现算网一体化,为用户提供泛在协同的连接与计算服务,算网感知功能、算力路由、算力编排调度等关键技术都是业界研究的重点。微服务架构也是算力网络发展的潜在技术。微服务架构是基于面向服务的架构(Service Oriented Architecture,SOA)思想,将大型项目根据需求拆分为多个小应用服务,每一个小的服务即一个微服务。多个项目的不同微服务可以灵活部署在不同的节点上,有利于提高资源利用率。从2016年开始,为了满足业务部署的个性化、简便化需求,微服务这一架构风格开始普及。目前,各大网络运营商都有自己特色的微服务框架,微服务的普及也带来了大量的微服务处理需求。
在算力网络场景下,采用微服务架构,可以将多样化异构的算力网络服务请求拆分为多个小应用服务,不同的算力网络服务请求可以共享同一个微服务,从而满足业务个性化、简便化的需求。算力网络中,微服务的部署调用需要考虑微服务部署、微服务请求调度和动态扩缩容3种业务请求。对不同业务请求调度的合理性直接决定了算力网络的资源利用率和算力网络服务性能。有文献针对边缘计算场景下微服务调度问题,提出了一种新颖的分布式延迟优化的微服务调度机制,保障传输速率以最小化微服务完成时间。有文献提出了一种边缘计算场景下动态微服务调度方案,优化了网络吞吐量、总时延和微服务利用率,为用户提供了公平的网络服务质量,提高了终端用户的满意度。有文献提出了一种基于强化学习的在线微服务协调算法来学习最优策略,该算法可以在降低服务延时的同时降低微服务迁移成本。有文献提出了一种基于奖励共享机制的深度Q学习算法来解决边缘计算中的多目标微服务部署问题,有效降低了服务平均响应时间,优化了负载均衡,提高了服务执行的可扩展性。现有工作主要集中于边缘计算场景下的微服务部署,考虑的因素包括时延、服务质量、成本等,模型基于边缘计算框架建立,未考虑算力网络场景下,云边端协同调度和网络高动态性。同时,上述文献模型没有考虑云计算、数据中心、边缘计算发展面临的高能耗问题,降低能耗是服务提供商关注的重点问题之一。
因此,本文从降低能耗和提升网络服务质量的角度出发,研究了微服务调度问题。降低能耗是降低服务成本的关键因素之一。从用户角度出发,服务质量是用户对算网服务的基本要求。服务层协议(Service Level Agreements,SLA)是指提供服务的企业与客户之间就服务的品质、水准性能等方面所达成的双方共同认可的协议或契约,是解决Web服务中这些问题的基石。SLA有助于在网络服务之间划分责任和风险,从而使网络服务更加有序。因此,SLA约束下能耗优化调度策略是一种在保障算网基本服务质量的同时,降低服务提供商服务成本的调度策略。
本文针对SLA约束下能耗优化的微服务调度问题,首先针对算力网络调度服务需求特点,建立了算力网络调度框架。在此框架基础上,针对算力网络资源有限性、网络高动态性,建立了网络模型、微服务需求模型、能耗模型、SLA约束模型和资源限制模型。最后,本文以能耗最小作为优化目标,以保障网络的服务质量为约束,建立了马尔可夫决策模型,并利用深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法自动寻找最优的调度策略,仿真结果证明了该算法的有效性。
02 系统模型
2.1 算力网络调度框架
由于网络算力节点的计算资源有限,且节点间通信能力受到带宽、信道状态等通信资源与环境因素影响,因此对算力服务进行最优部署与灵活调度,提升服务性能,是算力网络框架中的重中之重。如图1所示,本文设计的算力网络调度框架主要由算力网络调度模块、算力网络调度执行模块和算网信息表3个模块组成。
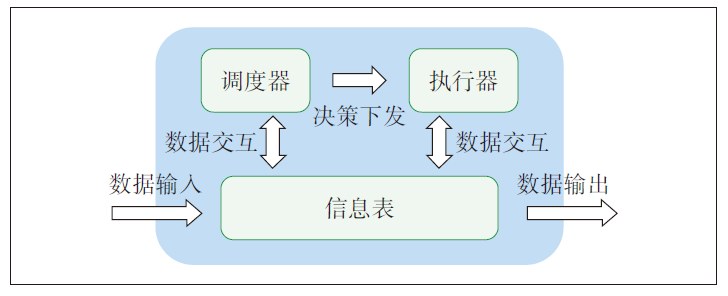
图1 算力网络调度框架
算力网络调度模块负责根据算力网络信息表中存储的多维资源信息和微服务需求,根据优化目标生成微服务调度策略。算力网络调度策略的优化目标有负载、成本、服务质量、能效等等。本文针对SLA约束的能耗优化这个目标,设计了系统模型。
算力网络调度执行模块负责将算力网络调度模板生成的微服务调度策略,将微服务调度部署到相应的算力网络服务节点,并将对应的信息变化更新到算力网络信息表中,帮助更新算力网络资源信息。
算力网络信息表负责存储算力网络多维资源信息,包括计算资源信息、存储资源信息和网络资源信息等。同时,算力网络信息表还需存储算力网络调度模块生成的调度策略信息。
基于上述算力网络调度框架,算力网络调度的工作流程为:算力网络收到微服务调度请求,主要包括微服务部署、微服务调度、动态扩缩容3类;根据微服务调度请求和算力网络资源信息,算力网络调度模块生成微服务调度策略;算力网络调度执行模块根据调度策略,将该微服务部署到相应的集群上,并绑定。
2.2 网络模型
网络由多种集群和综合纳管调度平台组成。集群内由主节点和多个工作节点组成,主节点根据微服务对各类资源的需求和集群内节点的算力资源、负载、网络资源等信息调度部署微服务。
综合纳管调度平台连接用户和集群,是用户部署微服务的接口。用户上传微服务,综合纳管调度平台在接收到用户的服务请求后,根据微服务的需求和SLA约束下能耗优化的微服务调度策略,将微服务调度部署到合适的集群。在微服务处理完成后,综合纳管调度平台将服务处理结果反馈给用户。
2.3 微服务需求模型
对微服务的建模主要包括微服务的种类和微服务对计算资源、存储资源和网络资源等各种资源的需求。微服务用si表示,si∈S,S表示微服务种类的集合,微服务种类的个数为I,微服务si副本数为ni。微服务建模如下:
si={nicopy,vCPUi,cCachei,Storagei,GPUi,FPGAi,Typei}
vCPUi={Num}
Storagei={Size}
GPUi={Type,FLOPS,Size,MBW}
FPGA={BoardType}
Typei字段代表微服务si的需求类别,微服务的需求类别主要分为CPU需求型、GPU需求型和FPGA需求型3种类型。微服务的模型描述了该微服务对计算资源、网络资源等资源的需求,需求参数的详细解释见表1。
表1 微服务需求参数注解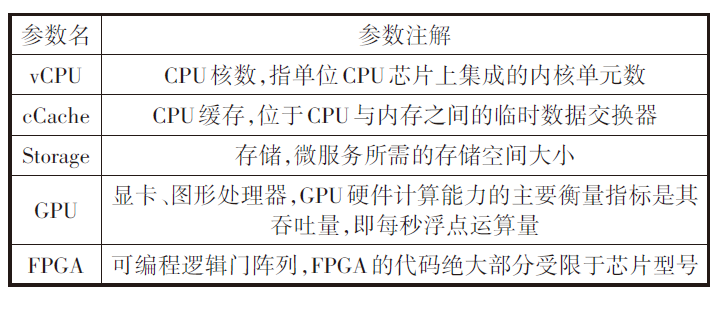
2.4 能耗模型
已知微服务共有I种,微服务si所需的资源类型与数量,可提供服务的算力网络节点共有M个。微服务运行在该节点上的能耗与该节点的CPU峰值功率、CPU空闲功率、CPU频率、CPU利用率等有关。待处理的微服务请求集合S={s1,s2,⋯,sI},可部署的算力网络节点集合M={m1,m2,⋯,mM},引入变量xij,用于说明微服务si部署在算力网络节点mj上,具体如下:

节点mj的利用率uj与该节点的总核数![]()
![]() 与该节点已被其他微服务占用的核数
与该节点已被其他微服务占用的核数![]()
![]() 有关,计算公式如下:
有关,计算公式如下:
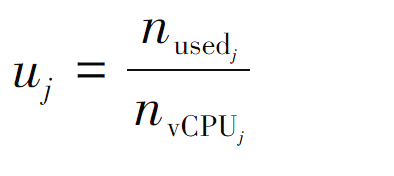
此时节点mj的利用率为uj,该节点mj的全速率工作的平均功率为Pjmax,空闲状态的平均功率为Pjidle,则该使用状态下该节点mj的平均功率为Pju,具体计算公式如下:
Pju=(Pjmax-Pjidle)×uj+Pjidle
用![]()
![]() 表示节点资源利用率为uj的时间长度,则节点的能耗Eij为:
表示节点资源利用率为uj的时间长度,则节点的能耗Eij为:
Eij=Pju×![]()
![]()
则将I个微服务部署到J个节点上的总能耗为: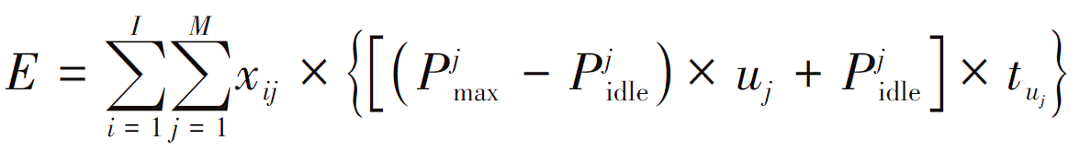
2.5 SLA约束模型
SLA是指提供服务的企业与客户之间就服务的品质、水准性能等方面所达成的双方共同认可的协议或契约,因此保证服务SLA即保障服务的质量。为了衡量算网服务质量,本文选取了带宽、时延、SD-WAN切换时延、抖动和丢包率5种网络服务质量指标。微服务si对网络服务质量的要求,既SLAi建模如下:
SLAi={BWi,tDelayi,sdDelayi,Jitteri,Dropi}
各网络服务质量指标的详细解释见表2。
表2 SLA指标注解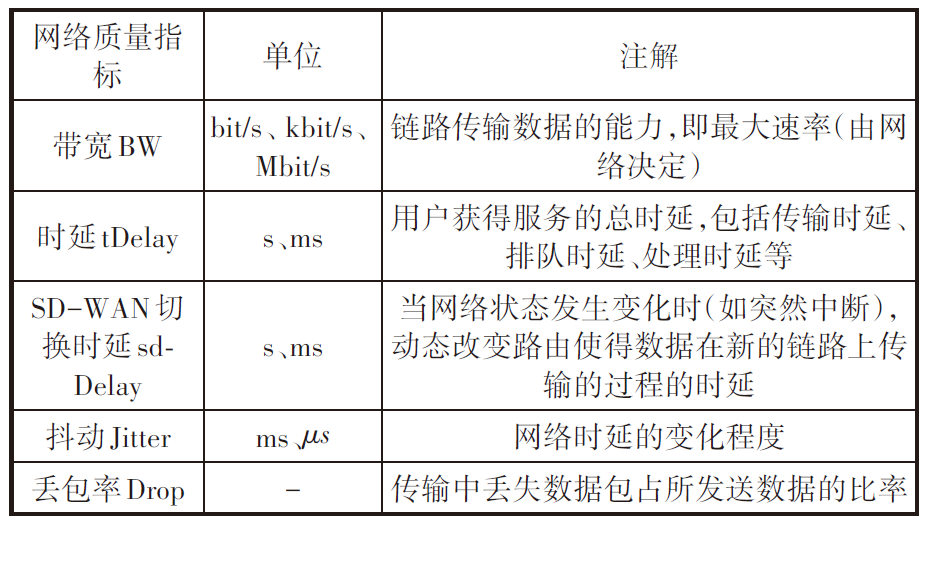
在生成微服务调度策略时,还会生成资源分配策略,分配给各微服务的资源包括计算资源、存储资源和带宽资源,微服务请求集合S={s1,s2,⋯,sI },分配给各微服务的计算资源、存储资源和带宽资源分别表示为C={c1,c2,⋯,cI},K={k1,k2,⋯,kI },B={b1,b2,⋯,bI},计算资源和存储资源根据微服务的需求分配,带宽资源则需根据微服务对时延的需求和信道状况进行分配。根据资源分配可以计算微服务的传输时延tDelayi,主要包括转发时延和链路时延。链路时延为tijlink,可由探针周期性探知。转发时延为tijtrans,是所需传输的数据总量dijall和被分配带宽bi的比值,具体公式为:
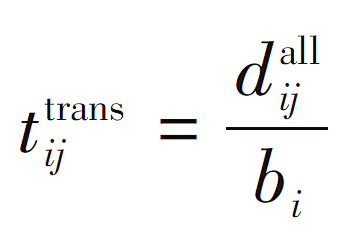
则传输时延tDelayi为: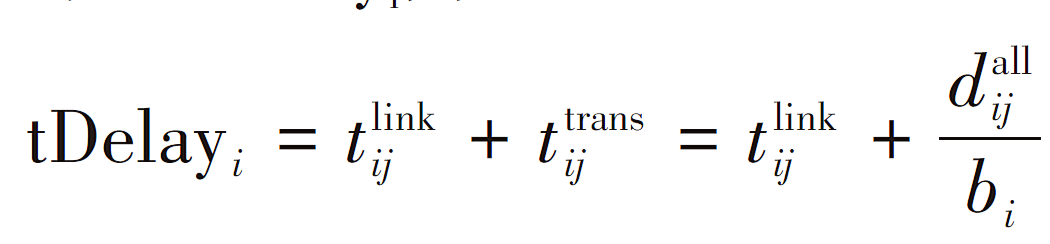
调度策略和资源分配必须满足微服务si所被调度到的节点mj满足该微服务si对网络服务质量的要求SLAi。微服务si对带宽、时延、SD-WAN切换时延、抖动和丢包率5种网络服务质量的要求分别为BWi、tDelayi、sdDelayi、Jitteri、Dropi,节点mj可提供的相应的网络服务质量为BWj、tDelayj、sdDelayj、Jitterj、Dropj,则必须满足:BWi≤BWj,tDelayi≥tDelayj,sdDelayi≥sdDelayj,Jitteri≥Jitterj,Dropi≥Dropj。
引入变量yij,用于说明微服务si部署在节点mj上是否满足其对网络服务质量的要求,具体如下:

2.6 资源限制模型
各集群都有特定数量的可用计算资源。假设这些资源已经专门分配给每个节点。那么,分配给节点中的虚拟机的资源在任何时候都不应该超过其总量。因此在生成资源分配策略时,需检查各节点被分配的计算资源和存储资源是否超出其总量。
微服务si所请求的计算资源为vCPUi,存储资源为Storagei,节点mj在时刻t可提供的计算资源为CPUtj,可提供的存储资源为STORtj,则资源分配必须满足:
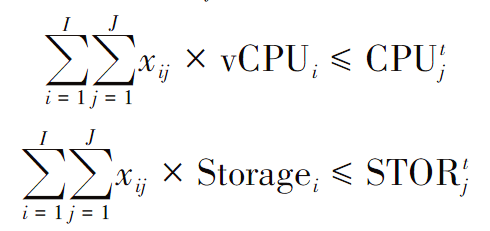
2.7 问题描述
本文的优化目标是在满足微服务对网络服务质量需求的同时降低本地端的能耗开销。微服务被成功地部署到节点上首先要保证该微服务请求的硬件资源小于该节点的硬件资源,其次还需考虑部署到该节点的能耗开销和服务质量,可以通过有约束的马尔可夫决策过程来进行建模。它的动作、状态、奖励和状态转移矩阵定义如下。
a)动作:动作包括微服务调度和资源分配决策,即![]()
![]() ={ot,ct},需注意的是,行动的组成部分应满足以下约束:
={ot,ct},需注意的是,行动的组成部分应满足以下约束:
(a)![]()
![]() ∈{0,1}是二进制微服务调度决策。
∈{0,1}是二进制微服务调度决策。
(b)∑m∈Mctm≤1,0≤ctm≤1约束一个连续的计算资源分配决策。
b)状态:状态包括待处理的微服务Sti、节点空闲计算资源状况Ctj、节点空闲存储资源状况Rtj、各信道状况Htm,即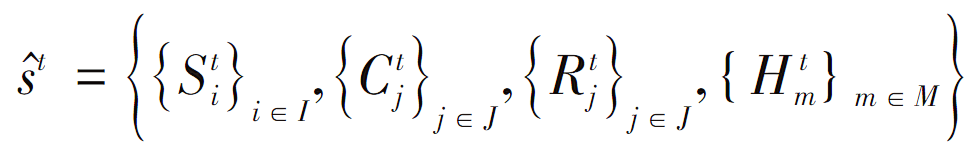
c)奖励:奖励的目的是使时隙t中调度的微服务整体能耗最小化,它被定义为:![]()
![]() =-D(ot)=-E(ot)。
=-D(ot)=-E(ot)。
d)状态转换概率:状态转换概率公式如下: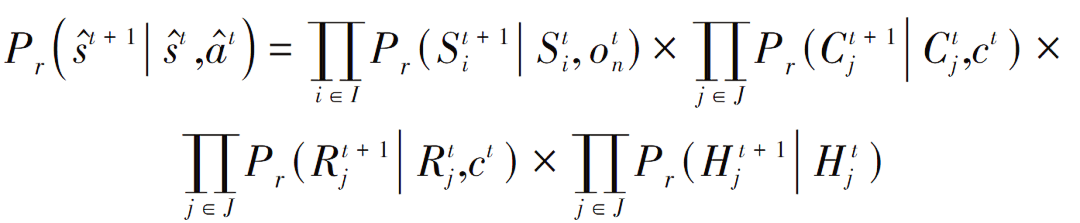
不同状态成分的独立性、平等性成立,第1个状态受待处理微服务队列和微服务调度决策影响,第2个和第3个状态都受资源分配决策影响,第4个状态是根据信道条件的离散时间马尔可夫链演化的。需注意这些状态分量中的每一个都只取决于它之前的状态分量,因此状态转换符合马尔可夫模型。
本文的目标是找到一个静止的策略π∈Π,根据状态![]()
![]() 动态配置调度决策ot和节点资源分配ct,使满足微服务对服务质量要求的同时,使能耗最小化,这被表述为以下问题:
动态配置调度决策ot和节点资源分配ct,使满足微服务对服务质量要求的同时,使能耗最小化,这被表述为以下问题:
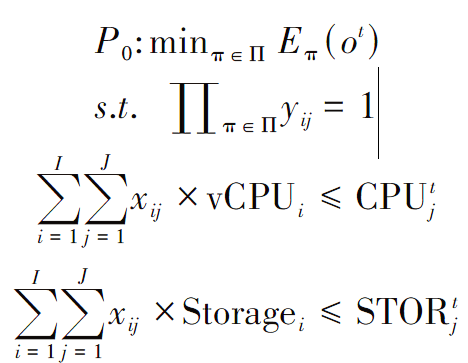
03 用深度确定性策略梯度算法求解
本节使用深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法解决上述问题。
DDPG是由深度Q网络(Deep Q-network,DQN)算法扩展开发的一种算法。DDPG是一种具有处理高维和无限动作空间的深度强化学习算法,它试图为代理找到一种最大化奖励的行为策略,以完成其分配的任务。这种确定性策略梯度(Deterministic Policy Gradient,DPG)算法能够在连续动作空间上运行,克服了Q学习等经典强化学习 (Reinforcement Learning,RL)方法的主要障碍。
DDPG是基于演员-评论家算法的一种算法,演员-评论家架构如图2所示。它本质上是一种将策略梯度和价值函数结合在一起的混合方法。策略函数μ称为演员,价值函数Q称为评论家。本质上,演员输出的是根据当前环境状态从连续动作空间中选择的动作![]()
![]() 。评论家的输出
。评论家的输出![]()
![]() 是一个具有时间差(Temporal Difference,TD)错误形式的信号,用于评价演员在了解当前环境状态的情况下所做的动作。
是一个具有时间差(Temporal Difference,TD)错误形式的信号,用于评价演员在了解当前环境状态的情况下所做的动作。
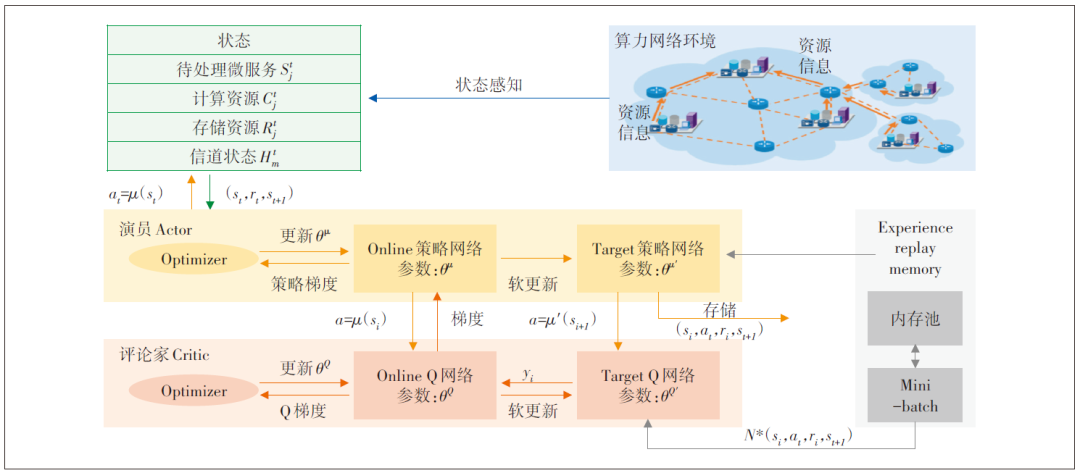
图2 演员-评论家架构
DDPG模型的训练阶段执行M个回合,其中每个回合迭代T次。使用索引t来表示单个回合中的迭代,其中t=1,⋯,T。演员和评论家是用神经网络设计的。价值网络的更新是基于贝尔曼方程,通过最小化更新的Q值和原点值之间的均方差损失来实现。策略网络的更新是基于确定性的策略梯度定理实现。
还有一些实用的技巧被用来提高框架的性能。探索和利用之间的权衡是通过使用ε-贪婪算法来实现的。在这种算法中,随机行动at是被以概率ε进行选择,否则就根据当前策略以概率1-ε选择一个准确的行动![]()
![]() 。在训练阶段,一个大小为B的经验重放缓冲区b被用来打破时间上的相关性。与环境的每次互动都以[st,a,r,st+1]的形式存储,st 是当前状态,a是要采取的行动,r是在状态st下执行行动a的奖励,st+1表示下个状态。在学习阶段,算法使用从缓冲区随机抽取的数据集。同时,利用目标网络来避免直接更新网络权重与从TD错误信号中获得的梯度而产生的分歧。
。在训练阶段,一个大小为B的经验重放缓冲区b被用来打破时间上的相关性。与环境的每次互动都以[st,a,r,st+1]的形式存储,st 是当前状态,a是要采取的行动,r是在状态st下执行行动a的奖励,st+1表示下个状态。在学习阶段,算法使用从缓冲区随机抽取的数据集。同时,利用目标网络来避免直接更新网络权重与从TD错误信号中获得的梯度而产生的分歧。
04 实验与结果分析
为了验证本文提出的问题模型求解算法的有效性,本文使用数值结果来评估DDPG算法生成的调度策略的性能。仿真环境基于Python3.6,在100个回合训练后进行20个回合推理,并取20个推理结果的平均值进行进一步的分析和比较。为了使仿真结果更有说服力,本文使用3个基准解决方案进行比较,分别是:基于DDPG算法、基于平均调度和非合作模式(每个任务都在本地处理不进行调度)。
在仿真中,节点有150个微服务任务待执行,每个微服务所需的CPU周期数设置为3 Gcycles/s。节点CPU计算能力设置为8 Gcycles/s。DDPG算法的学习率和折现因子分别设为0.0001和0.85。为了得到准确的性能估计,所有的数值结果都是通过多次实验得到的。
本文评估了所提方案在不同计算能力下的性能,对比了5个、10个、15个算力网络服务节点状态下,3个解决方案的微服务调度效果,如图3所示。随着节点数量的增加,非合作模式下,微服务都在本地处理,传输时延为0,但受限于本地计算能力的限制和能耗问题,服务效用低,因为微服务都在本地处理,故节点数量变化对非合作模式处理效用无影响。对平均调度算法和DDPG算法,待处理微服务数量不变,节点数量增加,对微服务处理效用提高。因平均调度算法未考虑各微服务对网络服务质量的需求和各节点能耗状态,故平均调度算法生成的调度策略效用低于DDPG算法。仿真实验结果证明本文由DDPG算法生成的SLA约束的能耗优化微服务调度策略是有效的。
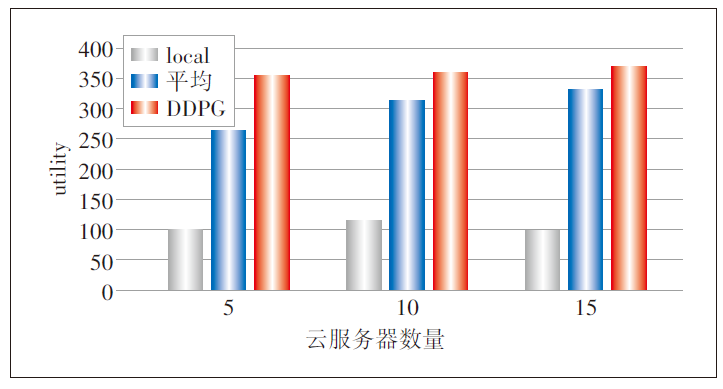
图3 不同节点数量不同方案的性能
05 总 结
本文以SLA约束为出发点,研究了云计算场景下SLA约束的能耗优化微服务调度问题。本文考虑了微服务对网络服务质量的需求和云计算节点能耗优化,建立了微服务部署调度优化模型,并基于该模型选用DDPG算法生成微服务调度策略。仿真实验结果证明了该调度策略的有效性。
作者简介
刘博文,助理工程师,硕士,主要从事数据骨干网相关技术研究工作;
梁晓晨,工程师,硕士,主要从事数据骨干网相关咨询设计与技术研究工作;
张桂玉,毕业于吉林大学,高级工程师,主要从事数据网络的规划、设计工作;
韩振东,毕业于清华大学,高级工程师,硕士,主要从事算网基础设施规划编制、新技术研究等相关工作。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
