
在声音事件检测应用中,训练数据主要有两种类型:强标签数据和弱标签数据。
- 强标签数据:在一段音频中,每个事件有明确的起始时间和结束时间的标注,具体的形式如下:{“event_type”: onset: offset}。
- 弱标签数据:在一段音频中,音频事件没有起始时间和结束时间的标注,只有段级别的标签。具体的形式如下:{“clips”: [event_type1, event_type2, …]},对于弱标签数据,通常采用Multi-Instance-Learning(MIL)的方式进行处理。
强标签数据的获得是一件费时费力的事情,因为需要进行明确的时间标注。所以本文介绍一个声音事件合成库Scaper, 它能够合成多事件音频,并且生成每个事件音频的起始时间和结束时间标注。一定程度上可以用于提升声音事件检测模型的检测能力。本文的目录结构如下:
- 概述
- Scaper介绍
- 结果展示
- 总结
Scaper介绍
Scaper是一个用于声音事件合成的工具,它的一个工作流程可以用下图表示
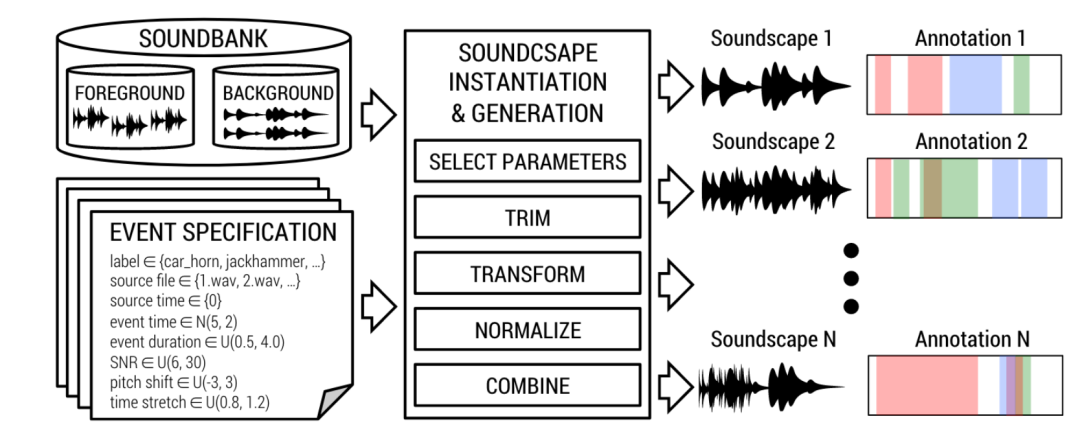
从上图可以看到,要想使用Scaper,所需要的准备工作如下:
- 准备
foreground和background文件夹,其中foreground表示事件音频,如siren、gunshot等,尽量保证每条wav音频只包含单一事件且避免静音段出现。background表示背景声,如街道、公园、广场以及风声等类型的wav音频,并且保证背景声中不要包含相应的事件音频片段。另外Scaper将每个文件夹当做标签,比如文件夹siren在合成的时候,就会被当成siren这一类标签,所以需要保证每个文件夹下的数据类型是正确的。
一个可参考的目录结构如下

- 参数配置,合成事件时需要指定的参数,主要包括:
label、source_file、source_time、event_time、event_duration、snr、pitch_shift以及time_stretch等。并且参数(如event_time和snr这种类型的参数)赋值的方式有多种,
- (‘const’, value): 给定一个常数值。
- (‘choose’, list): 从给定的list中均匀采样。
- (‘uniform’, min, max): 从min~max间均匀采样
- (‘norm’, mean, std): 从均值为mean,方差为std的正态分布中取值
- (‘truncnorm’, mean, std, min, max):带min和max参数限制的正态分布中取值。
- 音频变换:可以进行归一化等操作。
具体的参数配置可以参考官方文档:
https://scaper.readthedocs.io/en/latest/tutorial.html
参数准备好后,就可以调用Scaper的方法generate进行事件音频的合成了。
结果展示
Scaper合成音频时,每条音频会生成三个文件:
- *.wav: 合成的音频
- *.txt: 标签以及相应的onset和offset
- *.jams: annotations文件,包含完整的参数记录。
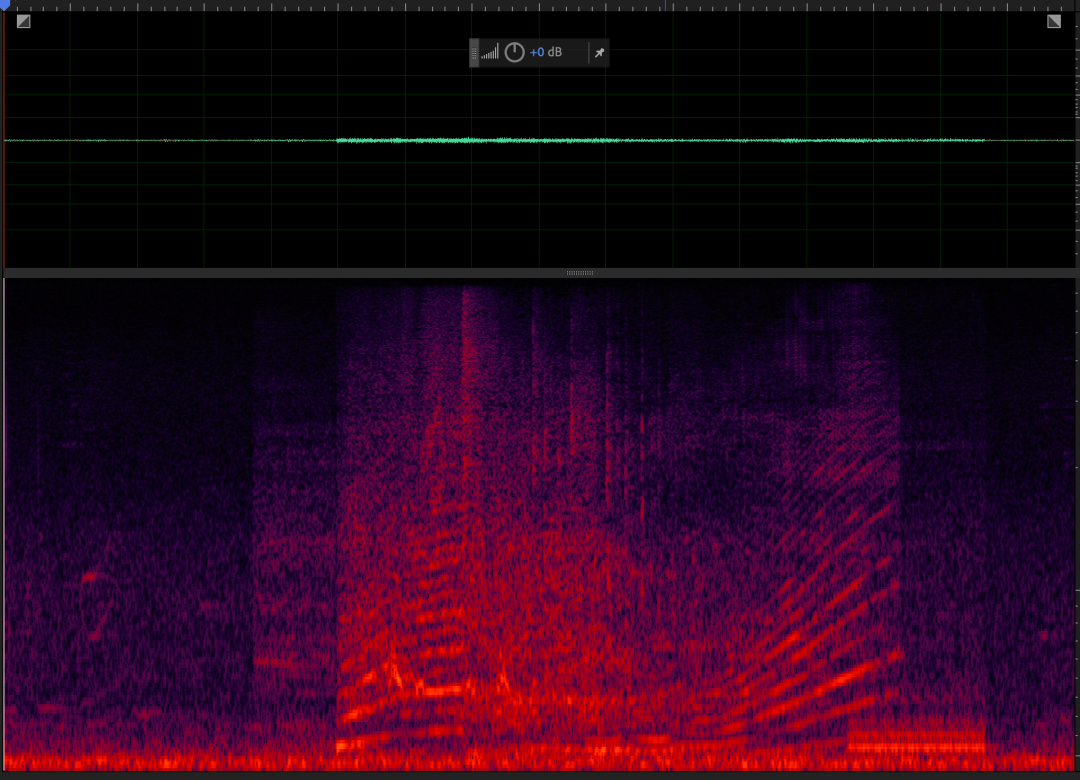
对应的txt文件

jams部分内容如下

相应的合成代码以及示例音频文件可以参考
https://gitee.com/Wilder_ting/study_-note/tree/master/SED_scaper_demo
总结
Scaper能够很方便的合成强标签事件音频,能在一定程度上提升声音事件检测模型的性能,但是考虑到声音事件检测应用的场景复杂性,纯粹的使用合成音频在实际场景中效果并不是很好,所以合成的强标签音频可以当成一个辅助手段。
作者:ctwgL | 来源:公众号——音频探险记
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。