
内容摘要:传统的传输层的协议已经成为卫星网络提供高速度、低时延的网络接入服务的一个障碍。过去端到端的 TCP 协议是专门为地面网络设计的,现在它并不适用易出错、传播时延大、间隙性联接的卫星链路。所以很有必要为卫星网络的传输层设计一种新的传输协议。这篇论文介绍了一种新的以信息为中心、跳到跳的传输层协议,INTCP。INTCP 在缓存和请求-响应模型的帮助下,实现跳到跳的包重传和跳到跳的拥塞控制。跳到跳的重传机制在每一跳上恢复丢失的包,这样减少重传延迟。同样 INTCP 也是在跳上实现流量控制和拥塞控制。每一跳都尽力实现带宽利用最大化,以提高端到端的吞吐量。缓存功能实现了传输层的异步组播。这将节省宝贵频谱资源。本文在模拟一系列星链上来测试 INTCP 协议的性能,通信距离设定 1000 公里以上。结果表明,在单播情形下,INTCP 可以减少 42% 的单向时延,53% 的延迟抖动,以及比过去 TCP 协议提高 60% 的数据吞吐量。在多播情形下,INTCP 可以实现 6 倍的吞吐量提高。
作者:Jinyu Yin, Li Jiang, Bin Liu
来源:HotICN 2021
论文题目:INTCP:Information-centric TCP for Satellite Network
论文链接:https://ieeexplore.ieee.org/document/9680870
内容整理:李冰奇
引言
最近几年,随着卫星小型化和火箭回收技术等新技术的发展,卫星网络蓬勃发展。Amazon 的 Blue Orign 计划在 590/610/630 公里等高度轨道上发射 3296 颗卫星,同时星链计划将在 340/550/1150 公里等三个轨道高度上发射 11943n颗卫星。到 2030 年,空间将有超过 25000 颗卫星。这其中大多数是地球低轨道卫星(LEO),他们旨在提供“联结全球的高速、低时延的宽带连接”(Starlink’s 标语口号),特别是对于农村、发展中国家、航空、海洋领域。
地面网络系统传输层使用端到端的 TCP 协议避免网络拥塞和端到端的可靠传输。其中,TCP 模型假设网络丢包是基于网络拥塞这个前提来控制拥塞窗口。然而,卫星网络具有高传输通道错误和动态拓扑结构的特点,丢包不仅仅是因为网络拥塞,也有可能是因为物理层的错误引起的。这就会导致基于丢包来判断网络拥塞的控制模型在卫星网络中表现不好。第二,卫星网络大的带宽-延迟积也会使 TCP 协议表现不好,由于卫星链路传输距离有可能远大上千公里,较大的 RTT 使得 TCP 窗口增加缓慢,从而影响 TCP 效果。第三,卫星和地面接收站的相对位置变化,使得传输链接路径频繁中断,LEO 卫星从每个基站头顶飞过的时间可能只有几分钟,星-地之间的链接经常转换,另外星际之间的通信链接启动时间从几秒钟至十几秒钟。经常暂时中断的路径对当前 TCP 协议实现端到端的可靠传输是非常困难的。
最近几种基于卫星链路的新的传输层协议被提出来,比如 TCP Hybla,TCP Spoofing 和 TCP splitting 等传输层设计,但这些设计都没有完全考虑卫星链路的特点。跳到跳的传输层协议设计被认为更适合 LEO 网络,基于此的一种 RCP 协议计算每个路径的发送速率,并且反馈路径上最小的发送速率给发送方,用来限制实际的发送速率。但是,RCP 的控制环仍然是端到端的,因此它并不能灵活的应对暂时的拥塞和带宽波动。另外一种跳到跳的设计使用后向压力算法来决定是否在每一路径限制发送速率,这一设计是基于瓶颈链路的缓存占用情况或者链路可用带宽,但是这些参数并非是网络天然就能提供的。
本文中,我们提出了在 LEO 网络(地球低轨卫星网络)上一种统一的跳到跳的拥塞控制机制(INTCP)。INTCP 的设计结构如图 1 所示,其中包含三个模块:缓存、拥塞、重传。
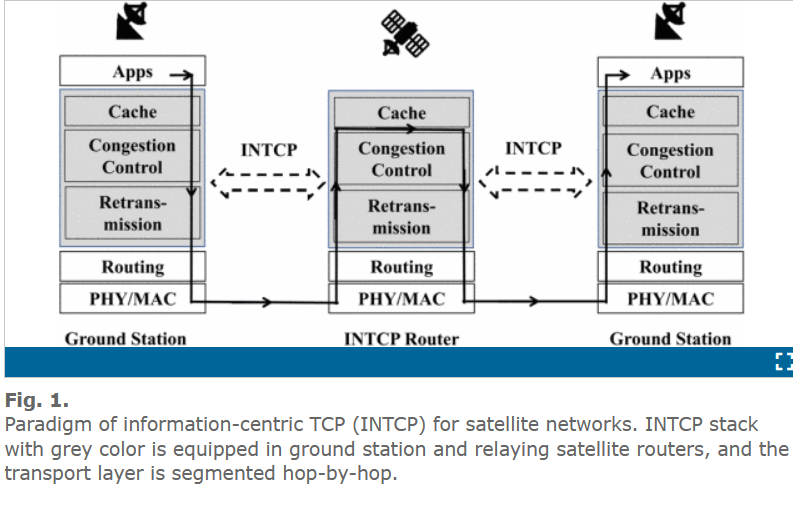
这一设计将端到端的路径划分为几段,并且提供跳到跳的可靠传输的和拥塞控制。INTCP 在每一跳上恢复丢失的包,而不是像之前的 TCP 在端到端上实现包重传。这就极大的减少了包恢复的时延,特别是对卫星链路这种 RTT 很大的链路尤为重要。跳-跳的拥塞控制在每一跳上最大化链路利用率,这将最大利用卫星链路,同时避免其中的瓶颈链路。另外,嵌入到网络中的缓存能够处理流入流出的流量,并且缓存下来多播和跳重传的数据包。
INTCP 协议保留了信息中心网络(ICN)在传输层三个基础的设计。1)命名数据。每一个用来请求和响应的数据包被名字识别。2)请求-响应模型。3)缓存。所有进来的数据包都将被缓存在本地。不同于之前的 ICN 和 NDN (命名数据网络),INTCP 协议不是设计的网络层协议,而是传输层协议。它和其他的路径协议机制是协调一致的,例如 IP 等协议。
INTCP 协议很好的解决了卫星链路面临的问题,首先,跳-跳的拥塞控制,每一跳的响应方可以对连接状况的变化快速响应,并且在跳级别而不是端到端级别的拥塞控制提高带宽利用率。另外,在缓存的帮助下,INTCP 可以提高端到端的吞吐量通过多路复用。每一跳都是独立工作的,并且尽自己最大的努力来发送更多的数据给下一跳。由于卫星链路每一跳的传输时间变化,缓存器可以缓存额外的数据,等网路条件变好之后传递给下一条。第二,INTCP 能够实现跳-跳的丢包恢复,从而减少数据重传时间。
为了评估 INTCP 的性能表现,我们用星链卫星的 trace 进行了大量的模拟实验。实验包括 1160 颗运行在 1000 公里高度的地球低轨卫星。对于地球上任意两个终端,它们连接移动的卫星。平均下来,INTCP 能够提高端到端的吞吐量 60%,节省 20% 的带宽消耗。
以信息为中心的传输层
在 INTCP 协议栈里,信息中心的传输层协议被部署在地面基站和 INTCP 路由器中。它控制每一跳的拥塞控制和丢包重传。如图 2 所示,INTCP 主要包括三个模块:缓存器,拥塞控制和重传机制。其他层的协议和和现在的 TCP/IP 协议族中的协议一致。
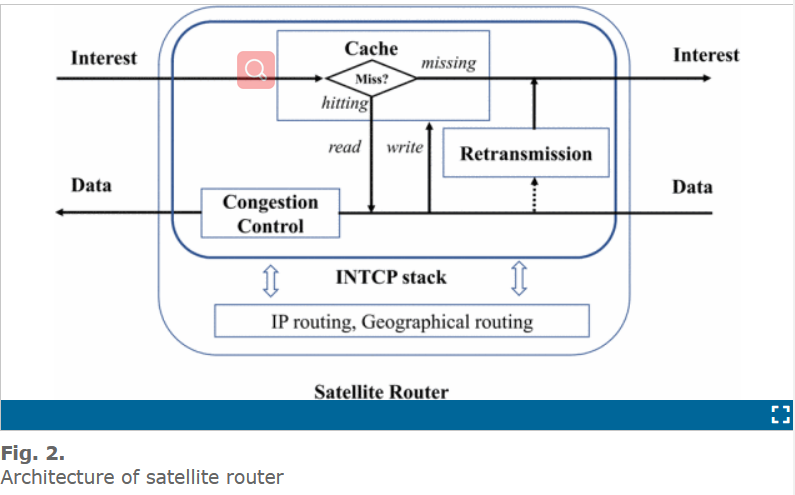
INTCP 协议的传输范式是 请求-响应-缓存,当 INTEREST 信息到来,响应者首先在缓存中检索数据,如果找到,数据将传递给请求者,如果没有,INTEREST 信息将传给下一跳。当 DATA(数据)信息到来,数据首先被存在缓存中用来将来的重传和广播用。同时,缓存中的数据被传给请求者。
在一跳中,请求者根据每一跳的网路状况来运行拥塞控制算法,例如基于包丢失,RTT,可用带宽等等,然后定时发送控制结果,例如数据发送速率,给这一跳的响应方响应者调整发送速率在这一跳上控制拥塞。另外,它根据请求者的 INTEREST 信息重传丢失的数据包。丢失的数据包存在缓存中,因此可以立即重传。这样就避免了传统 TCP 中端到端丢包恢复的长时间时延。
INTEREST 信息:形式为( Requester, Responder, Name, RangeStart, RangeEnd, SendRate ),通过 Name 来表示所要代表的内容或者服务。响应者的发送速率取决于请求者根据包时延、到达速率和丢包信息计算出来的数据,通过请求者反馈的数据 SendRate ,响应者来进行拥塞控制。
由于请求-响应模型是无状态的,因此,响应者并不知道是谁请求数据,因此,请求者的 INTEREST 数据中 Requester 表明请求信息的拥有者。当网络层使用 IP 协议,IP 地址表明请求者的身份,响应者把相应数据发给这个地址。Rsponder 表明发送方的地址。(RangeStart, RangeEnd)表示接下来被分隔成包的传输数据的字节范围,Interest 信息表示它所请求的数据。
DATA 信息:DATA 信息表示响应者发给请求者的信息。格式为:Requester, Responder, Name, RangeStart, RangeEnd, Timestamp, Data。其中 Name, RangeStart, RangeEnd, Requester, Responer 在上面已经解释了,Timestamp 表示响应者发送数据的时间,请求者用它来计算在这一跳上的单向数据时延。Data 段由传输的数据载荷组成。
跳-跳的拥塞控制
在 INTCP 中,拥塞控制如图 3 所示,在每一“hop(跳)”独立地进行拥塞控制,在每一跳的 Requester 端,Requester 测量网络状况并且运行拥塞控制算法,计算出合理的发送速率,定期反馈给 Responder 端。在 Responder 端根据反馈的发送速率进行发送数据,避免拥塞和实现带宽公平。
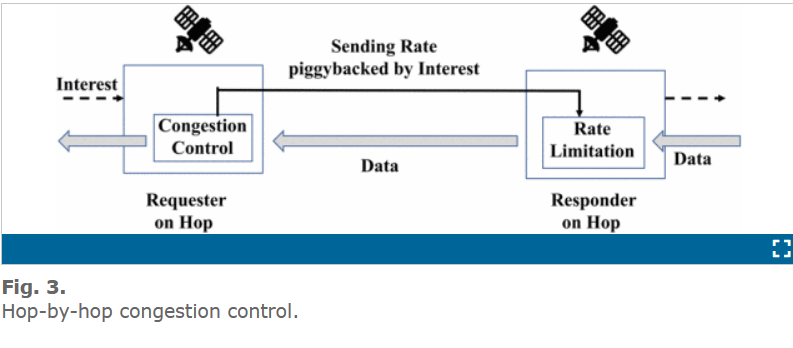
每一跳的网络状态包括:OWD(单向时延)、丢包状况和可用带宽。OWD 通过响应端( Responder )发送数据时打上时间戳,请求端( Requester )根据接受时间减去时间戳的时间记作 OWD。包丢失情况和历史上的吞吐量可以直接在 Requester 端计算,并且在 Requester 端考虑 缓冲区(buffer)的可用大小。另外,当多流同时到达一跳时,卫星交换机上的拥塞控制模型收集所有数据流的信息并且计算可用带宽,然后公平分配给每一路数据流。
当响应端收到发送速率的信息,不论是前一跳还是 cache 上的,都要按照收到的发送速率进行控制,本文使用令牌桶算法实现发送速率控制功能。
我们在每一跳上的拥塞控制算法目的是实现公平性、高带宽利用率和低排队时延。当 Requester 端缓冲接近耗尽时或者输出带宽减少时,产生并发送给 Responder 端一个小的发送速率数据,Responder 端将降低发送速率。并且Responder 端在前一跳中又是 Requester 端,将根据自身网络状况调整上一跳 Responder 端的发送速率。因此当瓶颈链路即将发生堵塞时,上游的跳将降低发送速率避免拥塞。另外,INTCP 协议支持在每一跳使用不同的拥塞控制算法,比如,在地面的跳仍然可以使用基于丢包或时延的拥塞控制算法,卫星链路上使用我们提出的基于速率的拥塞控制。
重传机制
INTCP 使用选择性重传机制确保卫星网络的可靠性数据传输。当接收方发现丢包时将重新请求重传的 INTEREST 信息,请求丢失的数据包。在 INTCP 中有两种重传机制:SeqHole 重传 和 Timeout 重传(超时重传)。如图 4 所示。
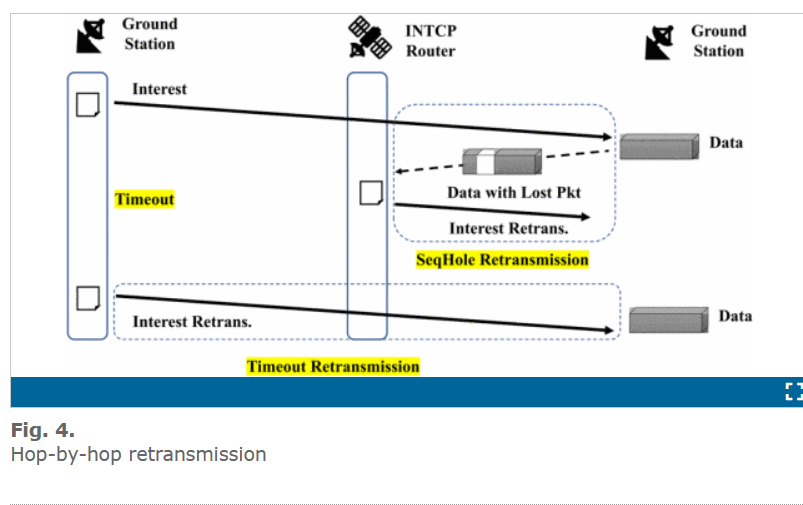
SeqHole 重传:属于跳到跳的重传,在每一跳上检查和恢复丢失的数据包。当每一跳的请求者收到 DATA 数据,根据 数据结构中 RangeStart 和 RangeEnd 段的信息,当一段数据被跳过并且在收到接下来连续 3 个包,INTCP 中重传机制就认为这一段丢失,然后重新发送 SeqHole Retransmission Interest 信息,结构为 INTEREST(name, LostFrom, LostEnd, TTL),其中(LostFrom, LostEnd)段表示丢包重传的包范围。TTL 代表 此 INTEREST 信息往前传递的跳数,通常设置为 1 ,防止前面的节点重复发送重传请求。
Timeout 重传:超时重传机制是端到端的重传机制。当消费者发出一个 INTEREST 请求信息,在本地设置一个超时重传时钟,当在该时间收到请求的数据,将从 RTO (超时时间表)中移除记录,否则重新发出请求。超时重传机制是跳-跳重传的补充,防止跳-跳重传在卫星路径变化时无法实现重传。
性能评价
在这一部分,我们通过基于 trace 的仿真实验在单播和多播情形下对 INTCP 的性能表现进行了测试。
方法
数据设置:当前没有公开的地球低轨道卫星链路的相关实际数据,我们建立卫星链路模型进行模拟实验,根据 Starlink 发表的实验结果对模型参数进行设置。Starlink 核心的卫星包裹 1600 颗分布在 32 个平面轨道上卫星,轨道高度在 1150 公里相对赤道倾斜角度为 53 度。根据这些信息,我们可以计算每个卫星的物理坐标并且利用模型例如香农公式计算最大的物理带宽、丢包率和每个链路的延时。最后,我们用经典的 Dijkstra 算法获得路有信息。
测试平台:mininet 模拟测试平台
实验设置:开始,我们设置一系列实验在两跳之间(地-地连接和星-地连接 GSL),观察 INTCP 的改进效果。GSL 参数是人为设置用来观察各个变量变化对网络性能的影响。然后我们洲际通信作为模拟情景,这是因为长距离(超过 1000 公里)通信是卫星通信网路应用的典型场景。另外,长距离通信面临很对严重的问题例如长时延和动态拓扑变化。我们专门选择北京-纽约作为通信的两端,单播和多播实验结果如下文描述的。
评价标准:在前两个实验中,我们选择单向时延、抖动和吞吐量作为评价指标,在多播情景中我们重点关注的是吞吐量。
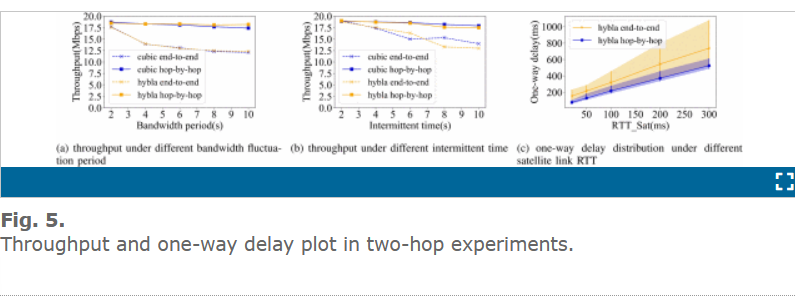
两跳实验
在图 5(a)中,我们假设星-地跳中带宽 5 Mbps-35 Mbps 波动在每个方波周期中,地-地跳中始终保持 20 Mbps 带宽。在没有缓存的情况下,端到端的 TCP 在任何时候的吞吐量 = min(groundlinkbandwidth, GSLbandwidth), 在跳-跳的情形下,卫星链路上的路由节点上的缓存能够存储来自地面的数据,因此即使星-地链路带宽比地面链路带宽大,星-地链路依然能够充分利用,使得 INTCP 的平均吞吐量高于使用端到端的 TCP 链路。
在图 5(b)中,比较了 TCP 和 INTCP 消除间歇性连通对网络影响的能力。我们假设 20s 内在 GSL 跳上发生一次连接中断,随着中断时间的增加,端到端的 TCP 明显性能下降,然而 INTCP 可以消除间歇性中断带来的影响。
在图 5(c)表示丢包恢复的情况下,单向时延的变化。在这个实验中 地-地链路 RTT 是 50ms,星-地(GSL)链路的 RTT 是 20-300ms,丢包率是 5%。每个阴影带内的曲线表明平均单向延迟,每个带的上下边界分别表示 5%/95% 的累积分布点。明显可以看出,INTCP 减少平均的单向时延,并且变化更小,这对很多应用很重要,比如视频会议应用。
单播情形
为了评估单播的情景,我们在模拟环境中模拟了从北京-纽约传输数据,实验进行了 24 小时。比较基准是使用 Reno 算法的传统的TCP 协议,在图中称作 TCP 。
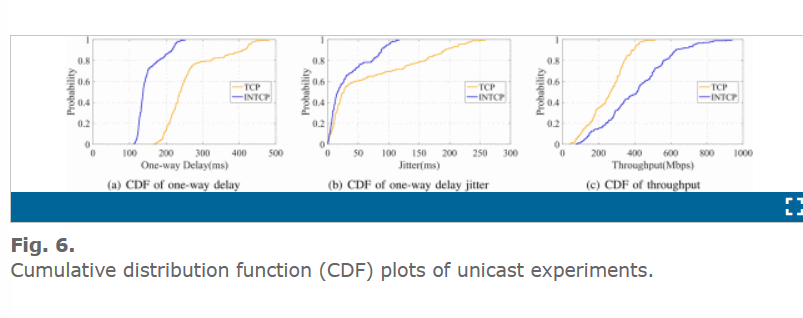
图 6(a)展示了单向时延的累积分布函数。TCP Reno 倾向于大的时延,而 INTCP 协议的 80% 时延是小于 180ms。这是因为丢包率越高,TCP 的性能下降越严重,INTCP 的跳-跳重传机制能够减弱这个问题。
图 6(b)展示了 INTCP 的抖动几乎总是小于 100ms,而 TCP 的抖动相对更大,主要是因为 TCP 中端-端的重传机制。图6(c)展示了 INTCP 带宽利用上明显更好,因为 Reno 基于丢包的拥塞控制机制浪费了部分物理带宽在高延迟、高丢包率的网络中,它的吞吐量受到瓶颈链路能力的影响。然而 INTCP 最大化利用每个链路的带宽,链路中的缓存也改进了 INTCP 的吞吐量。
多播情形
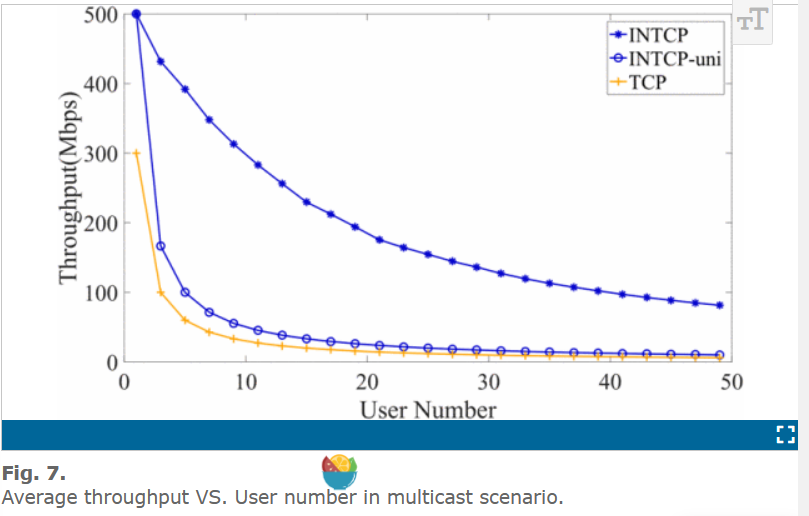
在多播实验中,我们假设大量的用户平均分布在北京-纽约的路径上,请求同样的数据,数据来源都是纽约。他们的请求时间非常集中,这就意味着因为缓存替换导致的缓存丢失情况可以忽略不计。
为了分析缓存的贡献,我们设计了 INTCP 的一个变种,称作 INTCP-uni,作为实验的基准,INTCP 与INTCP-uni 的区别是 INTCP-uni 没有缓存,它像传统的 TCP 一样直接从数据源头取数据。
图 7 展示了随着用户数量的增加,每个 INTCP-uni 用户的吞吐量下降严重,而 INTCP 用户维持较高的带宽,这对于直播视频流应用来说,用户的观看感受有很大的不同。
总结
为了在易出错的卫星链路上提供高速、低时延的网络接入,必须在卫星网络的传输层进行大的创新。INTCP 提出了一种信息中心的跳-跳的传输层协议,通过跳-跳的丢包恢复和拥塞控制实现端-端的可靠传输,仿真结果表明 INTCP 平均提升吞吐量 60%,减少时延 42% 和 53%的抖动。
下一步,基于学习的拥塞控制算法将在卫星链路上使用。通过修改缓存策略和转发策略,我们将讨论和优化运行部署 INTCP 的代价问题。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
