
近年来,线上音视频的产品形态和应用场景越来越丰富,疫情更加速了许多行业线下转线上的布局,音视频技术也越来越受到各大厂的重视,Zoom的股价飞升,腾讯、字节、阿里等等巨头的大力投入,令这个赛道的竞争越发激烈。在这个激烈的竞争环境下,所有的赛道玩家都很清楚,好的音视频体验,将是决定产品成功与否的最重要因素之一。在本篇内容中我们将主要围绕音频质量评估的一些重要标准,来讲讲不同评价体系里的标准、内容、相互关联和一些个人见解。

01

有些人可能觉得这个标准好简单,不就是1-5分的打分么?可是事实上并不是,主观的质量评价要想成为可重复使用的评价标准是很难的。不同环境、心情、知识储备、职业、听力范围及灵敏度等等背景的人都可能会对同一个声音给予不同的评分,甚至一个人在不同时间和背景下对于同一段语音质量,也会给予不同的主观评分。所以光有一个MOS评分是远远不够的,在标准里面还推荐了多种可行的测试方案,比如在Listening-opinion tests测试方案中给出了”Absolute Category Rating” (ACR) 。里面规定用短分组的不相关的句子测试,并且这些句子是通过一系列标准测试验证过的,然后在相同的测试方案下,相同的物理条件和传输系统下,来对比测试的结果。这样测试方案就具备较高程度的结果一致性。而这里说的物理条件包含非常的细致,例如测试线材、噪声(底噪;环境噪声)、噪声测量的位置。其中环境噪声还分为(房间噪声、车内噪声等)。除此以外对噪声测量的位置、创建连接、监听、仪器设备设计、对话任务等等都有一些建议。
说白了,这个标准事无巨细地列举了所有可能对主观评分一致性产生影响的因素,用很多不相关意义的短句组,在实验室可以控制的物理条件下,让很多被测试人员在相同环境下做对比测试,再做平均。这样的测试才能达到一致性标准,同时也具备了可行性。
但同时我们也发现,组织这样的一场测试耗时耗力,实在是不适合快速的质量验证。尽管如此,它对于今天依然非常有意义,比如现在很多产品在通话结束后给用户的质量反馈打分,1星到5星,虽然不能控制在相同的物理条件下,但是大量的用户主观评分概率分布依然可以相对客观地评价产品的主观质量。
最后,主观音频质量评价标准除了给出MOS 这个有意义的评分标准,还给出了两个标准MOSle 和 MOSlp,也非常有参考意义。


-MOSlp-
02
做一个成熟稳定高度逼近人类听觉体验的评价标准非常难,所以客观标准的制定最初是建立在一套有参考信号的评价体系之上的。也就是评价的时候,同时需要待测信号和参考信号(不经过待测系统只经过测试设备环境回环的信号)。相较于无参考评价方案,有参考的客观评价方案更容易做得贴近主观评价体系。
PESQ
ITU-T 在2001年02月发布的P.862里推出了一个新的方法:Perceptual evaluation of speech quality (PESQ),也是在一段时间内,业界广泛使用的方案。标准里这么说道:这是多年积累的结果,是一款不仅适用于音频编码器,同时也适合end-to-end 测试音频质量的评估方法。我们从下面几个角度谈一谈PESQ吧。
1、PESQ的测试方案
PESQ 如标准的描述,可以进行端到端的音频质量测试,把参考信号(Reference speech) line in 传入发送端(如下图是一个电话),经过电话网络到接收端,再Line out传出和直接回环(图里叫做参考路径Reference path)的参考信号传入PESQ 算法进行,有参考评估,最后生成PESQ score。
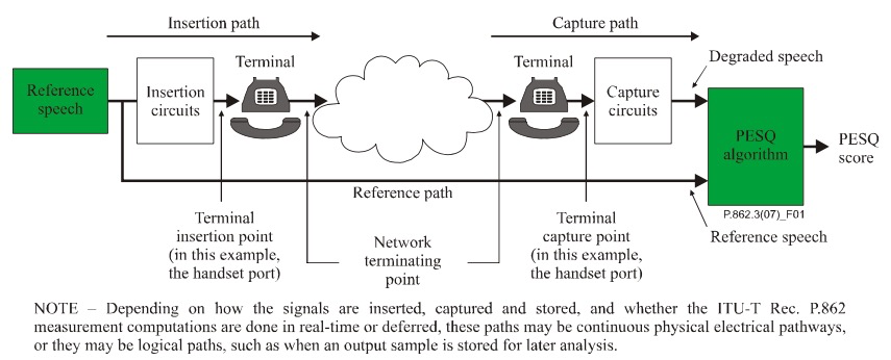
需要注意的是,参考信号并非是随意选取的,标准对于输入的参考信号有较严格的限制,比如长度:8-30s 的长度,里面的每个短句不能低于3.2s,活动语音的占比40%到80%,语音音量:参考ITU-T P.56 在-30dBov 同时避免溢出,等等。
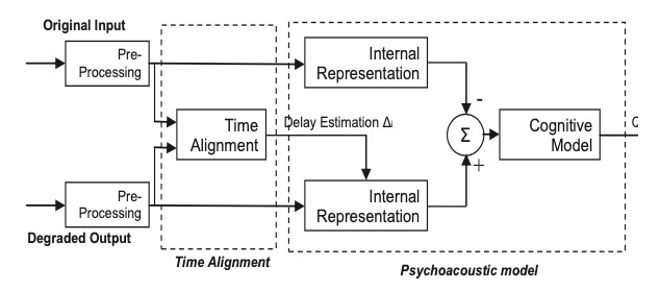
2、PESQ 算法流程
标准在PESQ算里面针对多个部分做了详细的阐述,这里给出一个简单的PESQ的算法框架如下图:
3、PESQ 的有限性
POLQA
随着时间的发展,更多的适用范围、更广泛的标准也一一涌现,如2004年P.563 的3SQM,还有一个就是一直沿用到今天、在有参考客观音频质量评价领域最新也是最大范围被应用的在P.863里出现POLQA标准。
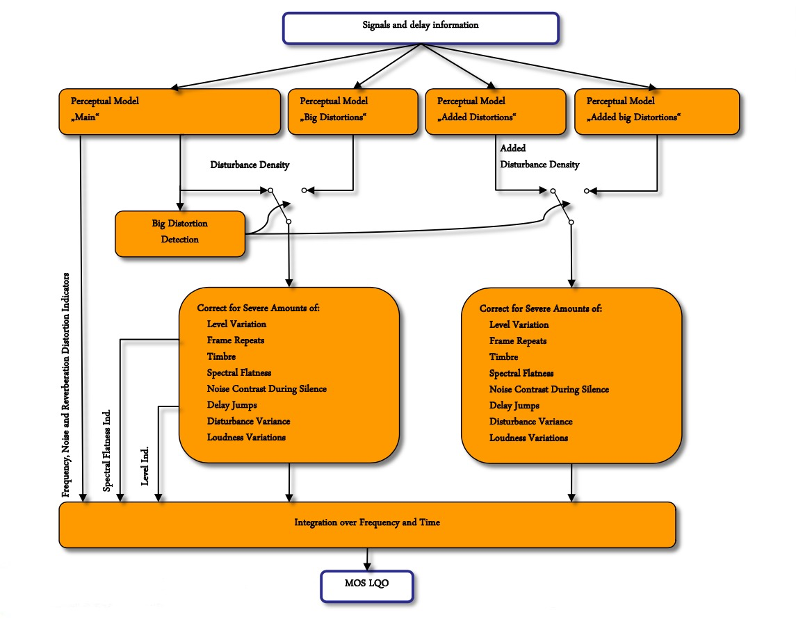
1、POLQA 测试方案与算法框架
2、重点说一下 POLQA 和 PESQ 的区别
这里转载Pomy在一份报告里面描写关于两个算法的一些地方的区别:
|
PESQ |
POLQA |
|
|
Acoustic measurements |
× Not easy |
√ |
|
Correct scoring with high background noise |
× |
√ |
|
AMR vs EVRC codec comparison |
× |
√ |
|
Representative scoring of reference signals |
× |
√ |
|
Effects of speech level in samples |
× |
√ |
|
Narrowband(300Hz – 3400Hz) |
√ |
√ |
|
Wideband(100Hz-7000Hz) |
√ |
√ Use SWB |
|
Superwideband,SWB(50Hz-14000Hz) |
× |
√ |
|
Linear Frequency distortion sensitivity |
× |
√ |
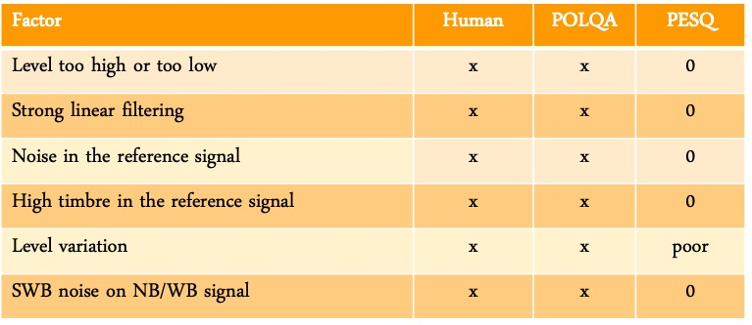
除了两个算法外,他还专门组织了”Absolute Category Rating” (ACR)测试,测试了Human、 POLQA、PESQ 之间的区别,如下图:
03
前面介绍了主观音频质量评测标准和客观有参考音频质量评测标准,特别是当有了客观的有参考音频质量评价标准,企业可以很方便地测试系统的端到端音频质量,虽然不能完全取代主观测试,可随着标准的更新,客观有参考评价标准会越来越接近主观评价且越来越稳定。但是很多企业也发现,即使有端到端的客观有参考评价标准,依然很难解决线上音频质量的实时监控。有没有一种指标可以在不需要参考信号的情况下,在某种程度上反应出主观音频质量的变化呢?
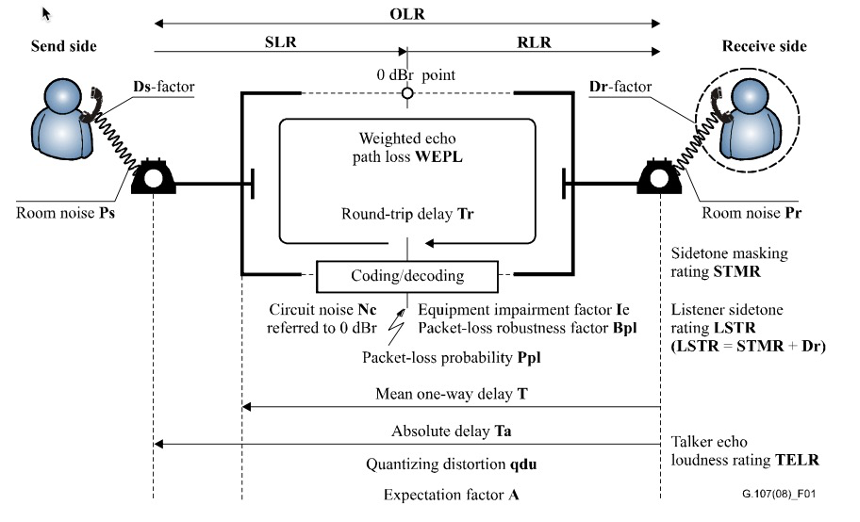
其中OLR:Overall Loudness Rating,SLR:Receive Loudness Rating, RLR:Receive Loudness Rating。E-model的传输损伤等级因子R的公式为:
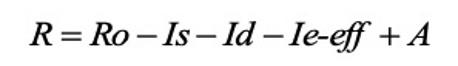
2、E-model的结果R 如何导出MOS
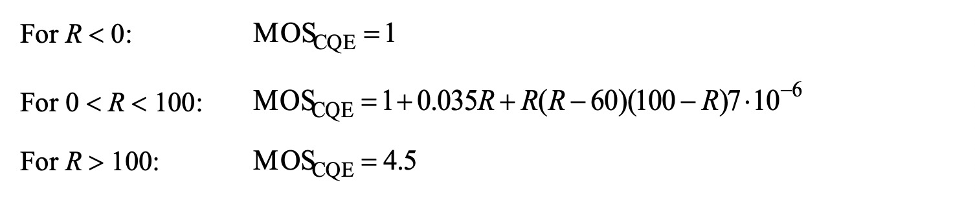
3、关于E-model的一些感想
G.107给我们带来一套复杂的、完善度也相对较高的评估模型E-model,这个模型在没有参考信号的情况下,把对于语音质量有影响的很多因子都考虑进去了。先不说能不能完全靠近主观测试的评价体系,对于企业的线上实时音频质量监控也具备很大的指导意义。另外也有人提供了一些改良方案,例如加入网络jitter的系数对评价结果产生影响,当然是不是合适也需要在实践中验证了。
以上介绍了一个音频质量主观评价标准以及两个音频质量客观有参考评估标准,以及一个音频质量客观无参考的评价标准。值得再次申明的是,客观评价标准是不能代替主观标准的。虽然随着算法的提升,它越来越接近主观评价,但在实际问题的优化中,主观的听感是不能代替的。当主观听感感受和客观指标产生了差异,既不能盲目相信少数人的少次测试听感结果,也不用盲目迷信客观标准,陷入了削足适履局面。
作者:拍乐云
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
