
每天在世界各地都有海量用户在短视频 App 上分享充满创意的视频或是生活中的精彩故事。
由于使用者所在的环境不可控(高铁、电梯等弱网环境),若直接播放原始画质的视频,可能导致观看影片的过程中出现卡顿甚至无法播放的情形,导致观影感受不佳。为了让不同网络条件的使用者,都能顺畅地观看这些视频,每一条视频的发布,都需要经过转码的过程,生成不同档位的视频,即使用户在网络不好的环境中,也能提供适合档位的视频,让使用者有顺畅的观影体验。
针对视频转码的场景,目前业界通用的解决方案大多为原始视频上传到物件储存后,通过事件触发媒体处理过程,当中可能涉及使用工作流系统做媒体处理任务的调度或是编排,处理完成的视频存档至物件储存后再透过内容分发网络(Content Delivery Network,CDN)分发给观影者。

[来源]https://aws.amazon.com/media-services
在业界通用的公有云解决方案中,对开发者而言需要整合公有云上各个子系统,来完成视频转码的生命周期,以及管理虚拟机计算资源,这需要较大的认知成本以及对各种云服务的学习成本,对开发者来说是比较大的负担。
在字节,视频架构团队经过长年的技术积累,在视频这个领域已经形成了一个内部多媒体处理 PaaS 平台。用户通过上传系统上传视频到物件储存中,接着会触发媒体处理平台的任务编排系统,下发转码、生成动图、封面照等任务到具有海量资源的计算资源池,最后透过内容分发网络分发给观影者。多媒体处理 PaaS 平台主要由两大子系统构成,工作流系统与计算平台,并提供多租户的接入方式,用以支撑字节整个生态系的视频处理需求。
计算平台主要提供了一个大型的计算资源池,将各种异构资源(CPU、GPU)封装起来,让团队内媒体处理专业的开发者无需关注计算资源整合相关工作,可以专注于开发具有各种原子能力的无伺服器函数,提供转码、生成封面照、生成动图等丰富功能。工作流系统则提供了任务编排的能力,能够定义视频上传后需要执行各种媒体处理任务的先后顺序,并将任务下发到计算平台利用大型的计算资源池来完成媒体处理的工作。
透过这两大子系统提供的基础能力,可以大大减少开发者的负担以及提高功能迭代的速度。
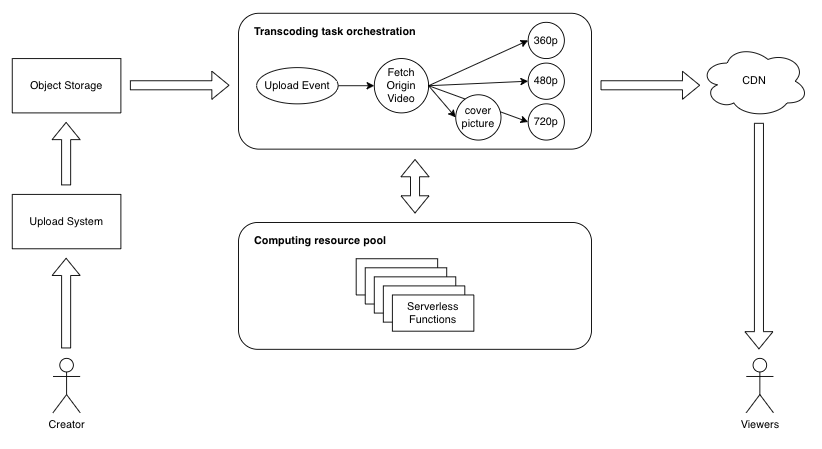
图 2:视频架构团队媒体处理系统解决方案
技术框架 1.0
这么庞大的一个线上系统,如何保持它的稳定性,并且在线上有任何异常情况时,能够准确、快速地处理问题,减少对用户的影响就显得特别重要。针对部署在世界各地的多媒体处理 PaaS 平台都会定义服务水准指标 (SLI),并以此为基础定义服务水准目标 (SLO),并配置针对 SLO 的适当报警规则。
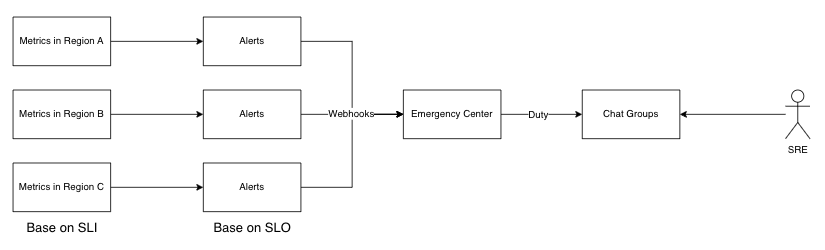
图 3:应急响应流程
如图 3 所示,当服务发生异常,例如:5分钟内请求正确率低于 99.9% 时,触发报警,并发送 Webhook 消息给团队内研发的应急响应中心平台,平台会将当下的值班人员创立一个告警处理群组,并把后续相关的报警信息都聚合到群组中,随后就由 SRE 开始介入处理。当前流程在创建告警处理群组之后,主要仰赖 SRE 去自主搜集与应急事件相关的异常指标,缺乏自动化工具提前做讯息的汇总,可能导致整体事故处理流程需要花费较多时间先梳理目前异常的指标才能做事故止损操作。
当前的痛点
微服务及依赖数量多
在团队中,服务的开发大部分走的是微服务架构,并且作为一个内部的 PaaS 平台,势必得提供全球跨区域的服务因此在服务本身以及基础设施方面,需要有多区域以及多机房的部署。目前只看单一区域媒体处理任务调度的微服务就有 30 个,此外还需考虑相关的基础设施的监控,如:数据库、缓存、分布式锁以及消息队列等……
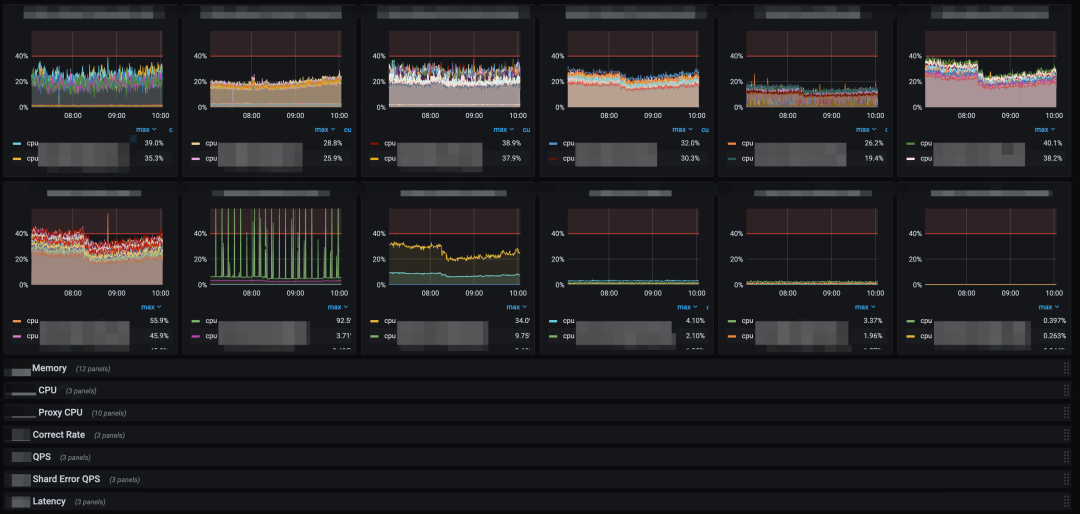
图 4:数量庞大的微服务监控仪表板
因此,即使制作了如上图全局视角的监控仪表板,但在应急事件发生的当下就能迅速的定位如此庞大的服务拓扑中的异常点,仍然是一个具有挑战的任务。
不同指标比较基准不同
对于应急事件发生时,通常可以分为以下两种情况:基础设施异常、突发流量。
第一个例子:数据库基础设施。通常在正常运作下的查询延迟都会处于一个固定的水平,例如 10ms 。延迟上升分为:整体数据库延迟上升(可能是当下负载高),部分实例延迟上升(可能是部门网段有抖动)。
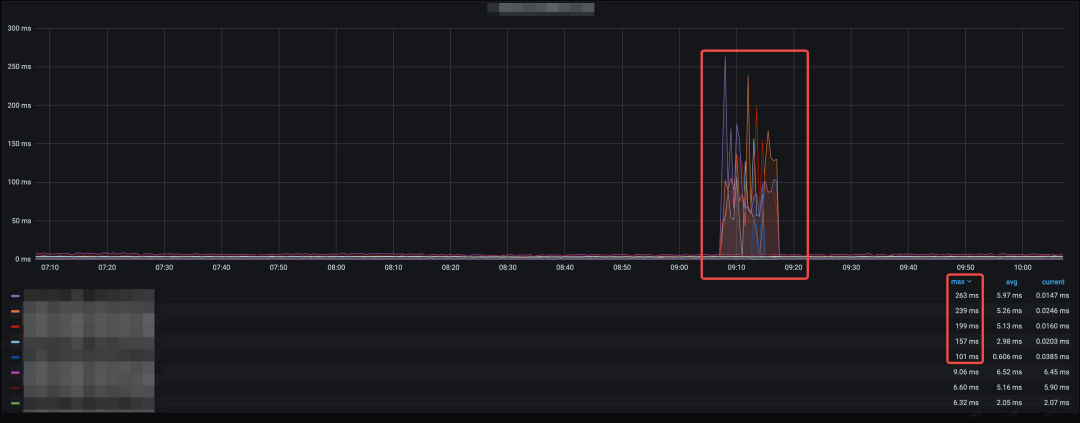
图 5:数据库延迟异常指标
第二个例子,突发流量。作为一个内部的 PaaS 平台,势必是提供了多租户的功能以服务字节内诸多团队的需求,且当租户数量达到一个量级,逐个租户去了解他们何时有活动或是有突发流量已经是不太合乎经济效益的事情,以下方的例子为例,可以看到指标呈现以天为周期的规律分布,但可以看到红框处紫色的指标较昨天明显得更多,这称之为昨日同比上升。
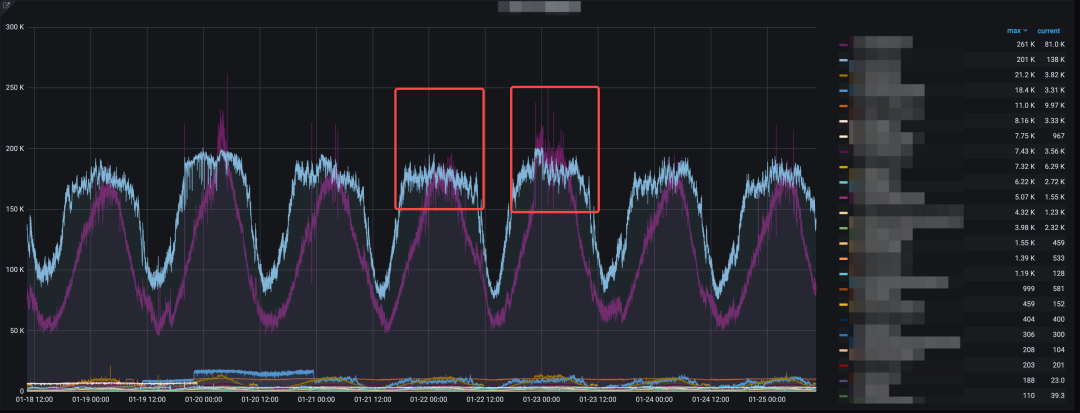
图 6:流量指标同比上升
错误排查涉及不同内部系统
第三个例子,涉及依赖系统的错误。以下图为例,红框处的错误量明显比过去半小时要高得多,这称之为环比上升。针对这种情况则需要到内部的 PaaS 平台去查询详细的错误码以及对应的错误日志。
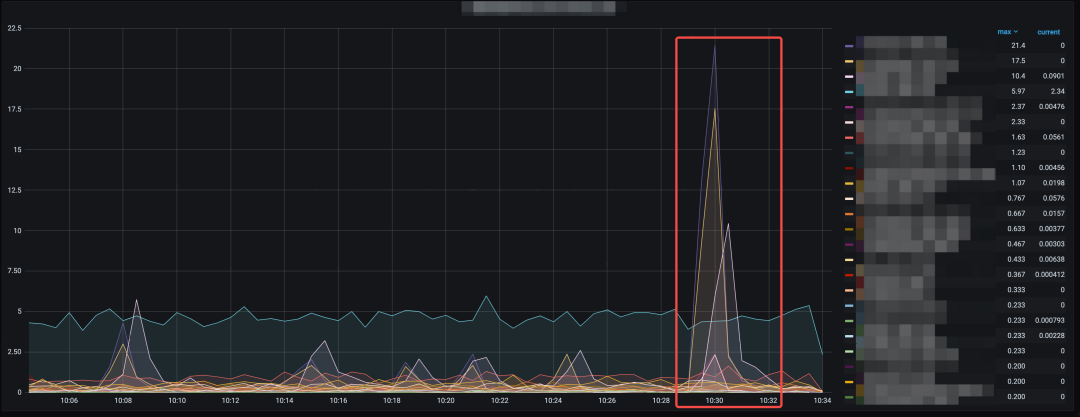
图 7:依赖系统错误指标环比上升
目标
以上三种情况,以现有的监控以及排查手段,在应急事件发生时,整个排查的过程需要比对多个仪表板甚至是不停地在仪表板上切换不同的查询时间段来比较指标的正常性,更甚者需要打开其他内部系统来查找日志,这都大大延长了定位问题以及做应急处理的决策时间。
因此如果能够把上面的排查工作做一定程度的自动化,那就能大大提高 SRE 成员在值班时对照值班手册 SOP(标准作业流程)来排查的速度,并能减少值班的辛苦感受。
量化指标
平均修复时间(Mean time to repair,MTTR)包含了发现故障(Identify)、故障定位止损(Know)以及故障恢复(Fix)的整体时间。导入自动化排查工具的主要目的是减少故障定位止损的时间,目前系统都有设定针对 SLO 目标的告警发生以及恢复时间的数据统计,因此决定以 MTTR 这个指标来作为这次自动化系统导入的成果量化指标。
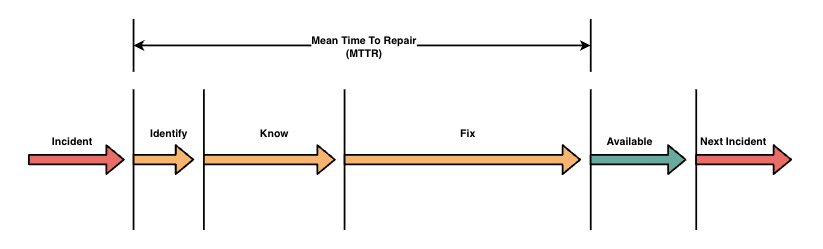
图 8:平均修复时间在事故时间序中的范围
架构
技术架构 2.0
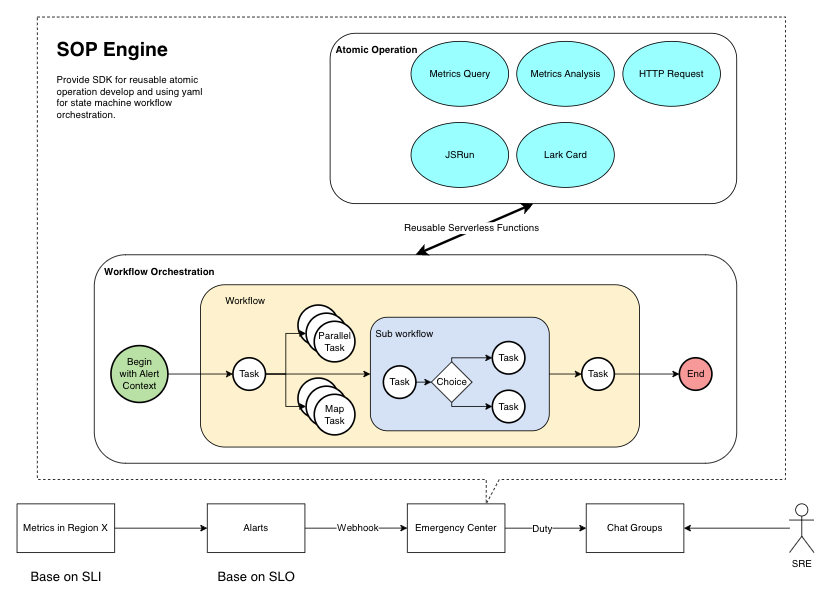
图 9:改善后的应急响应流程
视频架构稳定性团队研发的应急响应中心平台(Emergency Center)内建了名为 SOP Engine 的集成解决方案,提供了 SDK 让 SRE 的成员能快速开发,如:Metrics 查询、分析、发起 HTTP 请求等通用的无服务器函数,并能够利用 yaml 定义状态机工作流编排,来实现自定义的告警诊断或是应急处理预案的工作流编排使用。
自动化工作流设计
整个自动化告警处理流程可以归纳成如下图的步骤:
- 工作流被告警的 Webhook 触发,平台携带告警上下文(时间、区域),以及预先设定在工作流中的 Metrics 查询目标(为服务名称、数据库名称、消息队列 Topic)和异常阈值
- 使用 Parallel Task 方式触发子工作流分别做:作业系统(CPU、Memory)、基础设施以及微服务的告警诊断
- 每个告警诊断子工作流中,都会经过 Metrics 查询、分析以及结果聚合三个阶段
- 最后组装要发送到应急响应群组的卡片并发送
图 10:自动化工作流内部流程
Metrics Query 函数
Metrics 查询函数设计了如下方范例的 API,能对接字节基于 OpenTSDB 搭建的 Metrics 平台,主要提供以下几种功能来大幅提升本函数的重用性。
- Metrics 查询模板化,针对 indicator、tags、filters 都可以撰写 go template 语法并从 template_values 栏位带入值。
- 支援一次查询多种时间区段资料,利用 time_ranges 栏位下可定义如:30分钟前、1天、1周前等……不同时间范围,在一次函数呼叫中全部取得。
- Metrics 下钻功能,在 drill_downs 栏位可以定义针对原有 tags 上再额外追加 tags 来取得如:原本查询整体服务的 CPU 使用率,再额外查询该服务每个主机的 CPU 使用率。
{
"zone": "xx",
"indicator": "service.thrift.{{ .service_name }}.call.success.throughput",
"template_values": {
"service_name": "my_service_name",
"to": "redis_cache"
},
"aggregator": "avg",
"tags": {
"idc": "literal_or(*)",
"cluster": "literal_or(*)",
"to": "literal_or({{ .to }})"
},
"filters": {
"cluster": "my_cluster_name"
},
"rate_option": {
"counter": false,
"diff": false
},
"start_at": "now-5m",
"end_at": "now",
"time_ranges": {
"5mago": {
"start_at": "now-10m",
"end_at": "now-5m"
}
},
"drill_downs": {
"instances": {
"top": 1,
"top_aggregator": "max",
"tags": {
"host": "literal_or(*)"
}
}
}
}Metrics Analysis 函数
Metrics 分析函数设计了如下图的 API ,让阈值、同环比分析甚至是针对 Metrics 中某一个 Tag 的下钻分析,都能够定制要分析的汇总结果(最大、最小、平均、总和),此外比较运算子跟阈值也能够随意调整,这对于后续要修改阈值或是分析的逻辑都提供了很大的便利性。
{
"display": { // 必填
"namePrefix": "今日", // 可选,显示名称前缀,默认:当前
"name": "延迟", // 必填,分析结果指标显示名称
"format": "latencyMs" // 可选,分析结果指标显示格式,不填则按原样输出,只显示到小数第二位,格式支援 default, percent, latency, latencyMs
},
"summary": "avg", // 必填,对哪一个汇总资料做显示及分析 sum, avg, max, min, count
"threshold": { // 可选,阈值分析
"value": 4, // 必填,原始数值阈值
"operator": "gt" // 必填,比较运算子,支援 gt, gte, lt, lte, eq, ne
},
"time_ranges_percentage_difference": { // 可选,分析不同时间偏移资料
"5mago": { // 键名,可自行指定名称
"display": { // 必填
"name": "5分环比" // 必填,分析结果显示名称
},
"summary": "avg", // 必填,对哪一个汇总资料做显示及分析 sum, avg, max, min, count
"precondition": { // 可选,前置条件,原始 metrics 满足条件后才进行变化率分析
"value": 4, // 必填,阈值
"operator": "gt" // 必填,比较运算子,支援 gt, gte, lt, lte, eq, ne
},
"threshold": { // 可选,变化率阈值
"value": 0.1, // 必填,阈值
"operator": "gt" // 必填,比较运算子,支援 gt, gte, lt, lte, eq, ne
}
}
},
"drill_downs": { // 可选,分析不同下钻资料
"instances": { // 键名,可自行指定名称
"display": { // 必填
"name": "单实例" // 必填,分析结果显示名称
},
"summary": "max", // 必填,对哪一个汇总资料做显示及分析 sum, avg, max, min, count
"threshold": { // 可选,阈值分析
"value": 10, // 可选,单实例原始数值阈值
"stdDiff": 1, // 可选,单实例原始数值与其他下钻值平均比较标准差阈值
"operator": "gt" // 必填,比较运算子,支援 gt, gte, lt, lte, eq, ne
}
}
},
"filter": true, // 可选,只显示有达到阈值的分析结果
"metrics": [...] // 略,Metrics 查询函数返回的资料内容
}JavaScript 执行函数
在 Metrics 聚合以及机器人卡片信息组装的步骤中,不同的 Metrics 的聚合条件以及机器人卡片显示逻辑各不相同,如果分别开发会让整体函数的重用性以及开发效率降低,因此利用了 github.com/rogchap/v8go 这个套件开发了可以对输入 JSON 数据动态执行 JavaScript 的函数来处理这一系列的用途,谁叫 JavaScript 就是处理 JSON 格式数据的最好方式呢,如下,对 JSON 内的 Array 数据都能用原生的 JavaScript 做群组、排序、倒序以及映射的操作,十分便利。
{
"script": "data.flat().map(x => x * 2).filter(x => x > 5).reverse()",
"data": [
[1,2,3,4,5],
[6,7,8,9]
]
}实际案例:MySQL 延迟诊断
下图是一个实际异常诊断的例子如何用上述三个函数做组合,下图以 MySQL 延迟作为例子,可以看到大部分的 MySQL 延迟正常范围在 1s 以下,其中一台主机的延迟突然上升至 20.6s 这在应急响应中是需要被主动发现出来并且是有可能造成应急事件的异常。
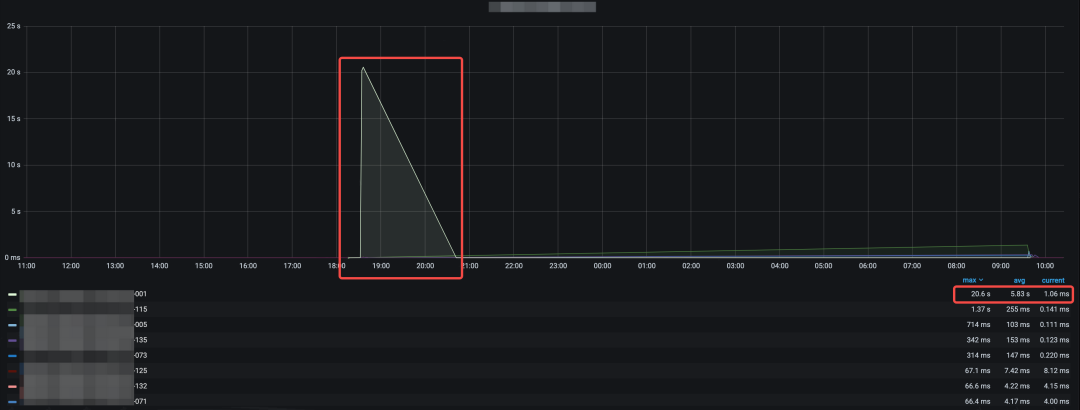
图 11:MySQL 延迟单实例异常
- 查询延迟,如下方的工作流定义,只需要从 Grafana 仪表板中把用来做图的 Metrics 以及查询条件、时间范围、下钻 tag 依照前面提到的 Metrics 查询函数的 API 定义填入就能做 Metrics 查询。
MetricQuery:
type: Task
next: MetricAnalysis
atomicOperationRef: metric_query
variables:
zone: xxx
indicator: mysql.latency.pct99
tags:
idc: literal_or(*)
db: my_database
aggregator: avg
start_at: now-30m
end_at: now
time_ranges:
1d:
start_at: now-1d30m
end_at: now-1d
drill_downs:
instances:
top: 30
top_aggregator: max
tags:
host: literal_or(*)
port: literal_or(*)- 分析延迟,下方的工作流定义,会在 Metrics 查询函数执行完成后执行,主要需要提供显示分析结果的文案、Metrics 的单位、以及各项异常分析的阈值。
MetricAnalysis:
type: Task
next: GroupResult
atomicOperationRef: metric_analysis
variables:
metrics.@: "@.data" # 从查询延迟函数输出取得查询结果
filter: true
display:
name: 延迟
format: latencyMs
summary: avg # 整体延迟平均超过 500ms 视为异常
threshold:
value: 500
operator: gt
time_ranges_percentage_difference:
1d:
display:
name: 昨日同比
summary: avg
precondition: # 整体延迟平均超过 200ms 则分析当下延迟与昨日对比
value: 200
operator: gt
threshold: # 整体延迟平均超过昨日的 50% 视为异常
value: 0.5
operator: gt
drill_downs:
instances:
display:
name: 单实例
summary: max # 单一 MySQL 实例延迟最大超过 1s 视为异常
threshold:
value: 1000
operator: gt- 分组结果,这个工作流步骤相对简单,主要针对 Metrics 分析函数的结果,以特定的 tag 做分组并排序,在这个例子里,我们希望利用 IDC(机房)来做分组的键,因此在以下工作流定义中就把执行上述逻辑的 JavaScript 代码引入即可。
GroupResult:
type: Task
end: true
atomicOperationRef: jsrun
resultSelector:
mysqlLatency.@: "@.data" # 从分析延迟函数输出取得查询结果
variables:
data.@: "@"
script: | # 针对 IDC tag 分组结果
data = data.map(x => x.data).flat().groupBy(x => x.template_values?.idc)
// 排序资料并转换格式
for (const key in data) {
data[key] = data[key].
sort((a, b) => a.original_value - b.original_value).
reverse().
map(x => ({
...x.tags,
usage: {
current: x.value,
"1d": x.time_ranges_percentage_difference ? x.time_ranges_percentage_difference["1d"]?.value : "无数据"
},
threshold: {
current: x.threshold,
"1d": x.time_ranges_percentage_difference ? x.time_ranges_percentage_difference["1d"]?.threshold : "无数据突增"
"instances": x.drill_downs?.instances
}
}))
}
data最终经过以上三个工作流的执行,可以得到以下资料输出结果,基本上有异常的 Metrics 以及诊断结论都已经结构化的方式做好分组以及过滤,并附有诊断结论,可以作为聊天机器人讯息的输入使用。
{
"mysqlLatency": {
"xx": [
{
"cluster": "xxxx",
"idc": "xx",
"threshold": {
"1d": "平均延迟昨日同比大于:50%",
"current": "当前平均延迟大于:1s",
"instances": [
{
"name": "mysql.latency.pct99{cluster=xxxx,dc=xx,host=xxx-xxx-xxx-001}",
"original_value": 20600.546,
"tags": {
"cluster": "xxxx",
"idc": "xx",
"host": "xxx-xxx-xxx-001"
},
"threshold": "单实例最大延迟大于:1s",
"value": "单实例最大延迟:20.6s"
}
]
},
"usage": {
"1d": "平均延迟昨日同比:62%",
"current": "当前平均延迟:501.49ms"
}
}
]
}
}而针对应用容器相关的指标诊断,如:CPU、Memory,或是应用本身的 Metrics 指标都是遵照类似的逻辑来编排工作流,只要替换查询的 Metrics 以及诊断的阈值即可。
收益
有了以上的自动化分析工具,在视频架构团队的日常应急响应流程中得到了很大的收益,在一次应急事件中,某一个 IDC 的网路发生故障,如下图:某一个 IP 的错误以及延迟都特别高,在应急响应处理群中自动触发的诊断都能直接把这类异常直接发现出来,就能马上针对异常的实例进行处置操作。
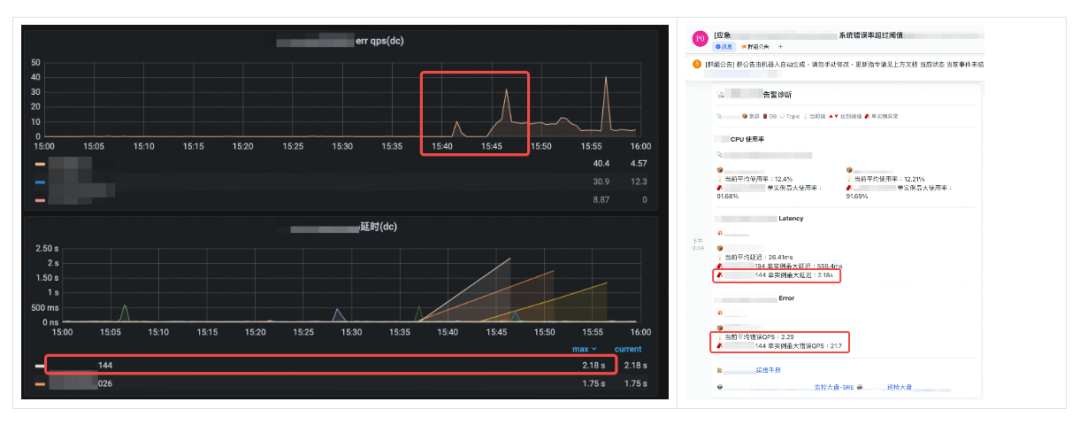
图 12:自动化工具在事故群组中展示异常指标的汇总讯息
本自动化流程完整导入后统计 MTTR 缩短成效如下图,从2022年10月初开始导入到目前2023年1月底,每双周统计一次 MTTR:从初期的 70 分钟,到目前 17 分钟,总体下降约 75.7%。
总结
在面对如此大量的微服务以及种类繁多的基础设施依赖环境下要能在应急事件发生时快速做决策以及执行应急操作,除了要有相对完整的监控之外,并且平时需要收集应急响应处理记录,才能统计出高频率发生的事件并归纳出一个自动化的排查流程来缩短 MTTR。
作者:萬俊瑋 字节跳动技术团队
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
