
1.CPU与GPU
CPU内部组成:
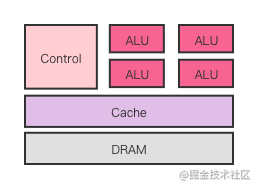
GPU内部组成:
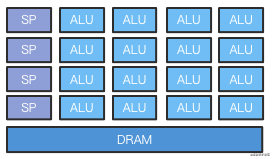
ALU:算术逻辑单元,是能实现多组算术运算和逻辑运算的组合逻辑电路。
CPU和GPU因为设计之初需求就不一样,所以它们的组成不同,在计算机中的分工也不同。
可以看到,GPU有更多的ALU,而CPU有Control单元和Cache单元,普通的业务代码因为逻辑复杂,数据类型复杂,跳转复杂,依赖性高等,就更适合CPU来做。
而GPU不擅长处理这些复杂的逻辑,它更擅长处理单一的运算,大量的算术逻辑单元可以保证做到真正的高并发,所以大量的计算任务是适合它的工作,就比如GLSL代码。
关于CPU和GPU的分工如下图所示:
为了并行计算,每个计算单元都必须独立。意味着所有数据必须沿一个方向流动,不可能检查另一个计算单元的结果。GPU使计算单元一直处于忙碌状态;一旦他们获得自由,就会接收新的信息进行处理。一个计算单元不可能知道它在前一刻在做什么。每个计算单元都是盲目且无记忆的。– 来自翻译《The Book Of Shaders》
可以很明显看到二者区别的是:
一个OpenGL程序,如果是跑在真机上,那毫无疑问是使用GPU运行的,非常流畅。如果是跑在模拟器上,是使用电脑的CPU在运行的,复杂的特效就会出现卡段。
扩展:Metal的使用就更极端,它必须使用真机运行,并且是6s及以上的真机。
2.计算机显示方式演变
首先需要说明的是,计算机的显示原理离不开视觉暂留现象。
视觉暂留:人眼在观察景物时,光信号传入大脑神经,需经过一段短暂的时间,光的作用结束后,视觉形象并不立即消失,这种残留的视觉称“后像”,视觉的这一现象则被称为“视觉暂留”。
物体在快速运动时, 当人眼所看到的影像消失后,人眼仍能继续保留其影像0.1-0.4秒左右的图像,所以当图像的刷新帧率高于每秒16帧时,在人眼看来就是不间断的显示。
2.1 随机扫描显示
随机扫描显示是早期的显示方式。CRT产生的电子束只在屏幕上显示图形的部分移动,电子束逐条地跟踪图形的组成线条,从而生成线条图。
这就决定了随机扫描显示的刷新频率依赖于显示的线条数,和图像的复杂度高度相关。图形的定义是存放在称为刷新显示文件存储区的一组画线命令。
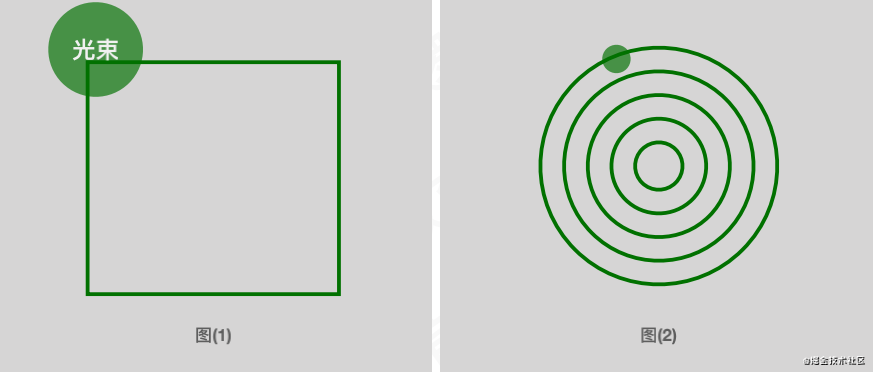
当显示的线条数很少时,则延迟每个刷新周期,以避免刷新速率超过每秒60帧。否则,线条的刷新速率过快,会烧坏荧光屏。
随机扫描显示的优点在于作为一组画线命令来存储而非每个像素点的强度值,因而生成光滑的线条,而非有锯齿的像素点。缺点是无法显示逼真的有阴影的场景。
2.2 光栅扫描显示
光栅扫描显示是目前的主流。
在光栅扫描显示中,电子束横向扫描屏幕,一次一行,从顶到底依次进行。电子束在屏幕上逐点移动时,从被称为帧缓存的存储区取出每个像素点的强度值控制其显示状态。
这种实现原理决定了光栅扫描显示的刷新频率和图像复杂度无关,刷新频率可以是恒定的。

光栅扫描显示对屏幕上的每个点都有存储强度信息的能力(除颜色信息外,其他的像素信息也存在帧缓存中),从而使得适用于包含阴影和彩色模式的逼真场景。
在某些光栅扫描系统中,采用了隔行扫描刷新的方式来显示每一帧。第一次从顶到底扫描奇数行,第二次从顶到底扫描偶数行。
隔行扫描使得扫描时间只需要原先的一半就能看到屏幕的显示。不过隔行扫描技术主要应用于较慢刷新频率的场景。
2.4 光栅扫描显示系统组成
光栅扫描系统除了使用CPU之外,还用视频控制器来控制显示设备的操作。
2.4.1 简单光栅扫描显示系统结构
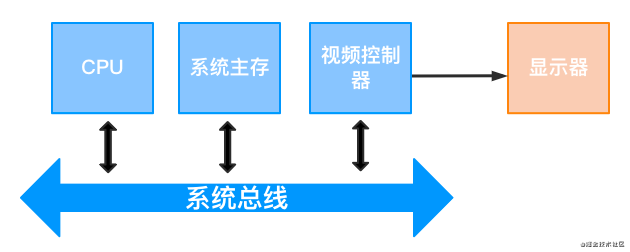
简单的光栅扫描系统如上图所示。其中,帧缓存可以在系统存储器中的任意位置,视频控制器通过系统总线访问帧缓存来刷新屏幕。
2.4.2 常用光栅扫描显示系统结构
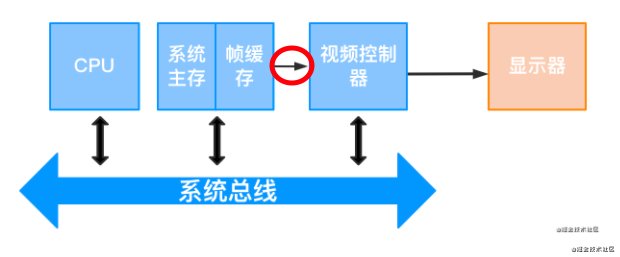
与简单结构的相比,这个结构明显提升了显示效率,原因在于:
帧缓存使用了系统主存中的固定区域来存储,且由视频控制器直接访问。
2.4.3 高级光栅显示系统结构
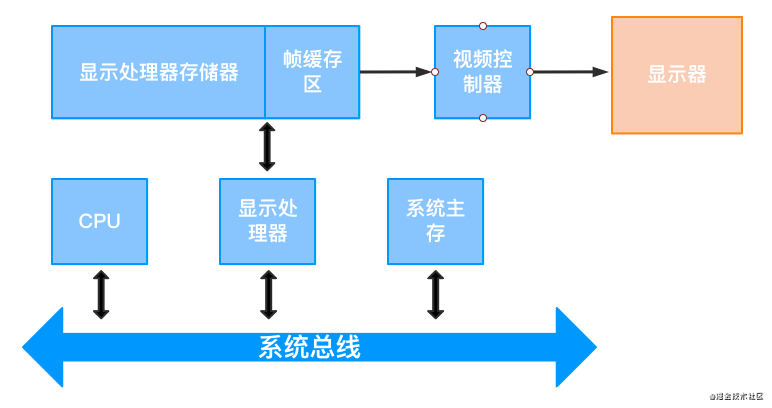
高级的光栅显示系统包含独立的显示处理器,也就是独立显卡。显示处理器使CPU从图形的复杂处理中解脱出来,还提供独立的显示处理器存储区域。
2.4.4 视频控制器的工作流程
无论何种结构,都存在视频控制器,说明它是必不可少的。那它是如何工作的呢?
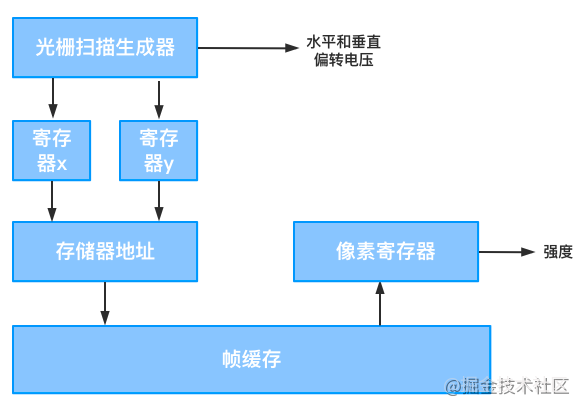
开始时,将x寄存器置为0,将y寄存器置为顶部扫描行号。存储在帧缓存中该像素对应位置的值被取出,并用来设置CRT电子束的强度值。然后,x寄存器加1,并沿该扫描线对每个像素重复执行。
在处理完顶部扫描线的最后一个像素后,x寄存器复位为0,y寄存器减1,指向顶部扫描行的下一行。
然后,沿该行依次扫描各像素,并且该过程对每条后继的扫描线重复执行。当循环处理完底部扫描线的所有像素后,视频控制器将寄存器复位为最高行扫描线上的第一个像素,刷新过程重复开始。
为了加速图像处理,视频控制器每次从刷新缓存中取出多个像素值。这些像素强度存放在单独的像素寄存器中,用来为一组相邻的像素控制CRT电子束的强度。当处理完改组像素后,从帧缓存取出下一块像素值。
由于多数设备都提供多缓冲的机制,视频控制器取像素强度值时还会在每个缓冲之间做切换。
2.4.5 总结
GPU的渲染流程大概如下:
GPU进行渲染时,会把数据先存储在帧缓冲区里,然后视频控制器读取帧缓冲区里的数据,完成数模转化,逐行扫描显示画面。
理论上,完美情况时,每扫描一张图,就显示一张,然后下一张也扫描完成等待刷新。
依次反复,屏幕就会保持流畅,那为什么有些时候屏幕还会出现不流畅的现象,不流畅现象产生的原理是什么?
3.撕裂与掉帧

画面撕裂是比较影响用户体验的异常。画面撕裂产生的原因如下:
当视频控制器读取读取完一帧画面显示后,会去帧缓存读取下一帧,如果帧缓存依然保持着上一帧的数据没有被刷新,视频控制器照常工作读取帧缓存中的数据。
当寄存器工作到某一行时,帧缓存的数据被更新为下一帧,视频控制器就读取到新的数据,而此时已经显示的画面是上一帧的数据,后续将要显示的是下一帧的数据,撕裂也就产生了。
所以,撕裂的产生是因为帧缓存的刷新频率没有跟上屏幕的刷新频率,根本原因就是CPU或GPU工作超时。
为了解决撕裂的问题,苹果宣布iOS一直会使用垂直同步Vsync + 双缓冲的机制。
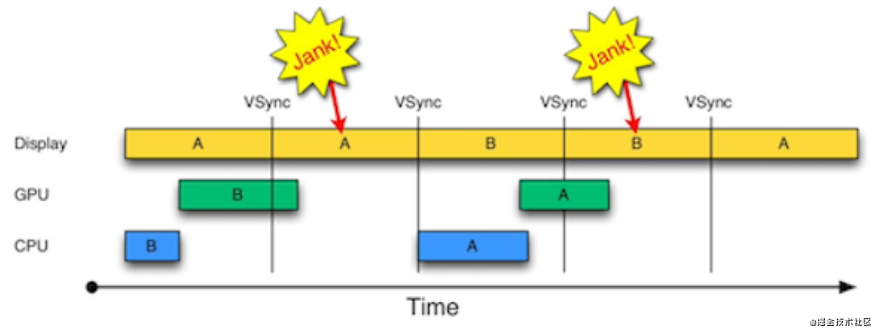
在VSync信号到来后,会在CPU中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。
然后CPU会将计算好的数据提交到GPU,由GPU进行变换、合成、渲染。然后GPU会把渲染结果提交到帧缓存,等待下一次VSync信号到来时显示到屏幕上。
由于垂直同步的机制,如果在一个VSync时间内,CPU或者GPU没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时屏幕会刷新显示上一帧的内容。
通过这种机制,就解决了撕裂的问题,但同时引入了新的问题 — 掉帧。
当CPU或GPU渲染流⽔线耗时过⻓,前后显示同一帧时,也就出现了掉帧现象(所以掉帧不是不渲染数据,而是重复渲染同一帧数据)。
至于掉帧无法被完全解决,因为CPU或GPU的工作是不可预估的。只能尽量合理的使用CPU或GPU减少掉帧次数。
这里引入三缓冲机制的概念:
开辟三个帧缓冲区,尽可能保证总有个缓冲区中有下一帧需要的内容。不过这也是治标不治本的手段。
总结:
撕裂是由于CPU或GPU耗时过⻓而产生的,iOS解决的方式是引入垂直同步Vsync + 双缓冲的机制,而解决撕裂是以掉帧作为代价的,掉帧不能完全被解决。
4.iOS下的渲染框架和流程
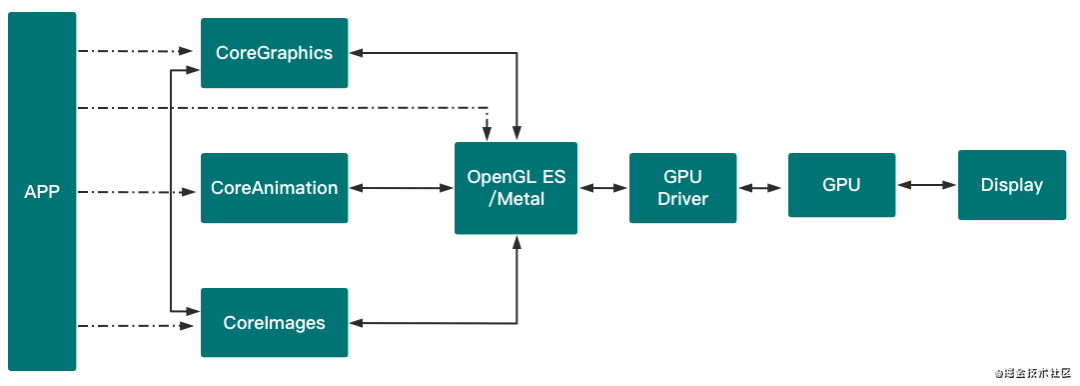
当然,APP也能直接使用OpenGL/Metal提供的接口进行绘制。
总结:
-
UIKit:通过UIKit提供的街交口进行布局和绘制界面,UIKit本身不具备显示能力,是通过底层的layer实现的。
-
CoreAnimation:本质上是一个复合引擎,主要职责在于渲染,构建和动画。CAlayer属于CoreAnimation,是界面可视化的承载。
-
CoreGraphics:基于Quartz的高级绘图引擎,提供了轻量级的2d渲染能力,主要是用于运行时绘图的。CG开头的类都属于CoreGraphics。
-
CoreImage:一个高性能的图像处理分析的框架,运行前绘制图形,主要提供图形的滤镜功能。
-
OpenGL ES:针对嵌入式设备,是OpenGL的子集。直接操作硬件服务,是跨平台的。
-
Metal:苹果自研的针对自家设备的图形渲染标准,在苹果设备上性能最优。
5.CPU和GPU的渲染流水线
总的来说,图形的渲染分为两个部分:CPU部分,GPU部分
在CPU部分主要做了3步操作:
1.Handle Event 接收事件,包括点击事件,布局的改变等。
2.Commit transcation 提交事务,通过CPU完成显示内容的计算,然后对图层树进行打包,在下一个runloop时提交到Render server进程
3.Render Server 将收到的包进行解码,处理完数据后,再传递至 GPU
需要注意的是,app本身的进程并不负责渲染,渲染是由一个独立的进程负责,就是Render Server进程
在GPU部分主要就是渲染管线的内容:
这部分的内容在OpenGL初探 – 专有名词解析中的最后总结已说明。
最后,GPU的渲染管线结束后,需要在等下一个runloop来时显示帧缓冲区内的内容。
以上渲染流水线举个具体的例子如下:
「如果一张图片被设置为imageview的属性时会发生什么?」
首先,CATransaction捕获到图层树的变化,在下一个runloop周期到来时,Core Animation会提交这个隐式动画,会对图片做以下操作:
-
分配内存缓冲区用于管理文件IO和解压缩操作
-
将文件从磁盘读到内存
-
将压缩的图片数据解压成未压缩的位图数据,这一步操作比较耗时,且在主线程
-
CPU计算好frame等数据,对图片解压后,交给GPU做图片渲染
-
Calayer使用原始数据进行绘制Content
6.写在最后
OpenGL或者shader的编程都是面向过程的,大部分是面向GPU的,这和面向CPU编程的思想是有所不同的。
以前总觉得图形的变换总是在第一帧的基础上进行是费时费力的,如果在上一帧的基础上变换岂不是更省事,理解了屏幕成像和渲染原理之后对这个问题,或者说对图形学才有了初步的理解。
作者:小峰子
来源:https://juejin.cn/post/6990531601289936933
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
