
背景介绍
作业帮实时音视频ZRTC经过流媒体技术团队的持续打磨和优化,已在大规模复杂的生产环境稳定运行3年以上,不仅有力地支持了作业帮丰富多彩的互动课程类型,同时也积累了丰富和宝贵的实践经验,今天我们一起来回顾并总结其中的关键技术要点。
一、技术总体架构
1.技术总体框架
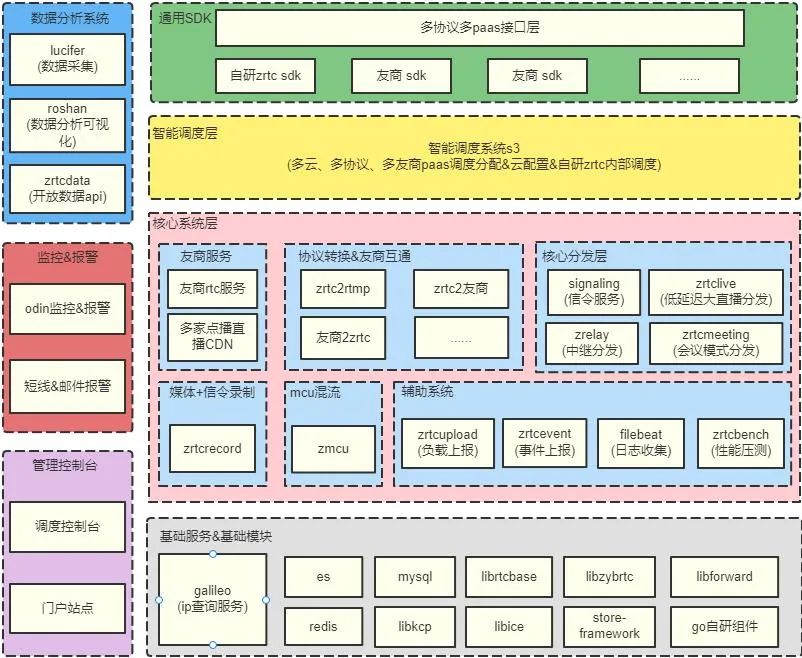
作业帮直播系统是一套多云、多协议、多paas的融合架构,从SDK到服务端,在协议上不仅支持基于CDN的传统RTMP直播,也支持RTC低延迟直播;在多paas接入上,接入了两家主流RTC服务厂商和三家CDN厂商,以提供冗余灾备;在服务部署上,异地多活部署在多家云服务器上,以保证稳定可靠。
- 通用SDK层
作业帮通用直播SDK为业务抽象出一套统一的调用接口,可以同时支持低延迟直播、多人连麦、传统直播和点播等功能。SDK配合智能调度系统,底层选择何种流媒体协议、何种音视频引擎以及哪家云厂商的服务器,业务均无需关心。SDK通过灵活的底层抽象和分层,把采集、编解码、传输、音视频同步和渲染等全部模块化,可以实现灵活多样的组合,其中推多、拉多、渲多等各种组合,为作业帮复杂多样的课程模型提供了最大限度地支持。
- 智能调度
调度系统是整套系统的大脑中枢,在上层可根据成本、质量、突发容量以及容灾需求等因素,对多paas服务进行动态分配,也可根据业务场景选择不同的协议以及协议的动态降级(比如RTC动态降级为RTMP),同时管理着各个服务和SDK相关的动态配置和灰度策略;在底层负责内部实时系统ZRTC的边缘节点调度、智能路由选择、多云容灾切换等。这些调度粒度可以精准到单个用户,即一节课的学生可以分布到不同的paas、不同的云服务器上,指定的学生也可降级到RTMP协议上,这样的实现带来了系统上的高度灵活,可以应对各种突发情况。
- 核心系统层
核心系统层主要是对媒体数据进行分发和加工,zrtclive和zrtcmeeting分发服务是基于webrtc源码高度定制的高性能SFU;zrelay中继服务是基于开源KCP协议的服务间中继多跳转发服务;协议互转服务是在服务端接入友商linux SDK与自研RTC实时互转,是实现多paas的核心;录制服务可以实时录制媒体和信令,最终能够完整地还原出上课中的所有体验;MCU混流服务实现多路流的音视频混合,为录制和CDN提供混合源。
- 其他
完善的系统还需要监控报警和管理后台,我们自建了流媒体相关的监控系统和报警体系,能做到实时报警,也可以事后进行统计分析,为系统持续优化提供数据支持。另外将一些高度可复用的功能抽象为基础模块,例如webrtc抽象出了libice、librtcbase、libzybrtc等组件,KCP抽象出了可实现会话管理的libkcp,同时开发了一套高性能网络库store-framework。
下面主要围绕ZRTC分发做相关的介绍,后续更加细化的模块分享可以持续关注作业帮技术团队公众号。
2.大直播分发架构
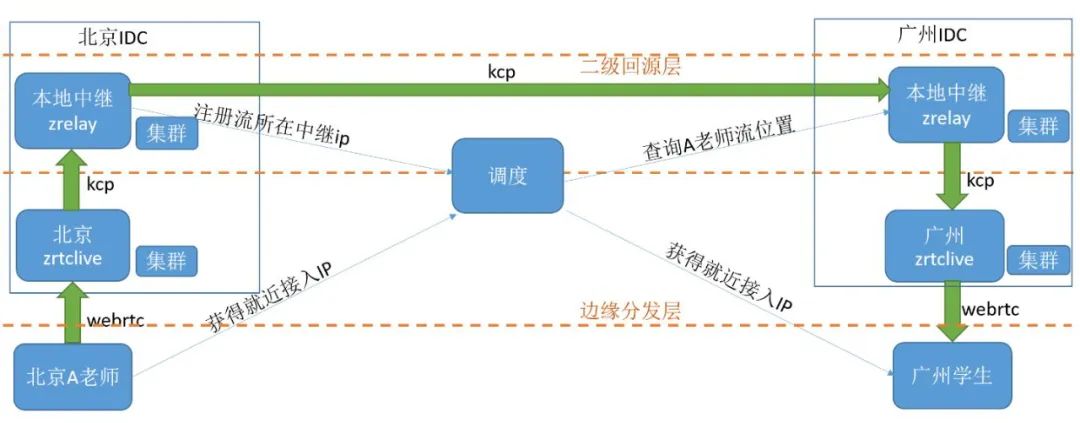
总体的分发架构是比较简明的,以北京的老师和广州的学生举例来阐述大体的流程,首先北京的老师访问调度服务获取一个最佳的服务器IP,然后通过http接口与这台服务器进行SDP的交换,交换成功后通过RTC协议连接到这台边缘zrtclive分发服务器进行推流,推流成功后,zrtclive通过KCP协议将媒体流推送到本IDC的中继服务zrelay,zrelay同时将推流信息注册到调度服务。此时广州的学生拉流,同样通过调度系统获取到一个最佳的边缘服务器进行拉流,如果该学生是广州IDC覆盖区域的第一个学生,他获取的边缘服务器以及广州的中继服务器都没有北京老师的媒体流,此时广州的zrelay会访问调度系统拿到老师的推流信息进行KCP动态回源。
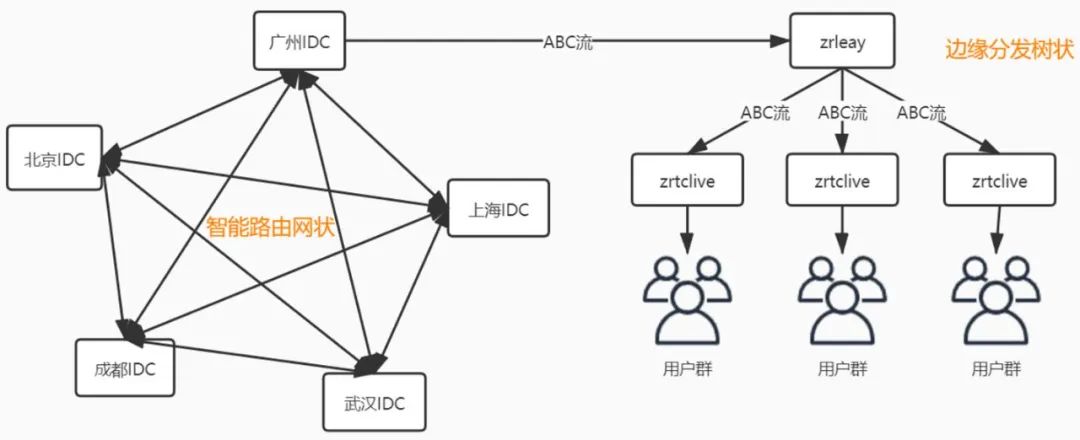
注意上图中北京IDC和广州IDC回源并不一定是直连回源的。整个中继节点其实是一个网状结构,每个中继节点都彼此相连并且实时测试网络状态,并上报给调度系统,调度系统根据历史数据和实时数据进行路由的预配置和实时切换。而zrelay和zrtclive节点又是一个树状结构,支持多级级联,此种设计具备极灵活的扩展能力,从而能够支持更高的并发规模。
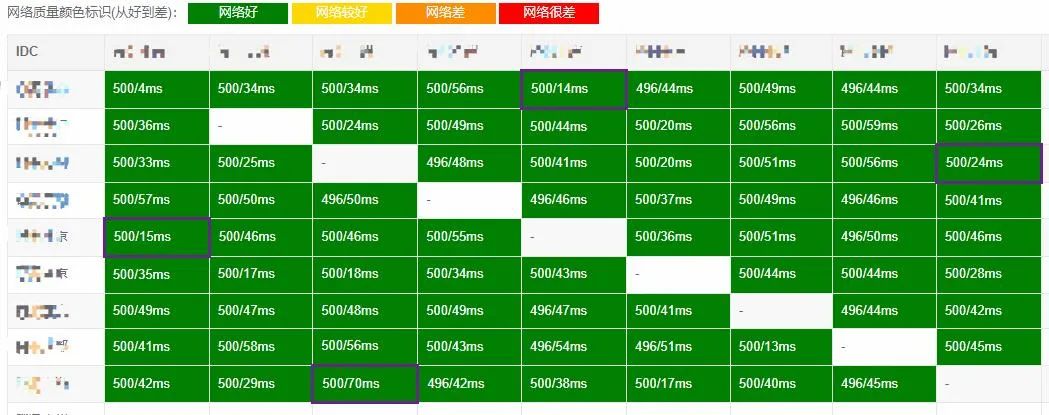
例如,上图一部分中继节点的实时测速结果,因为我们的节点都是异地多云的,经过观察我们发现同云的网络较为稳定,而跨云且地理位置较远的节点经常发生网络抖动,所以我们预配了几个多云的固定pop点来提升网络的稳定性,这些pop点都是同省或者同市,当然如果pop点发生故障调度系统会动态调整路由。
二、如何高并发
1.架构方面
- 去除房间等业务逻辑
系统只抽象出推拉流粒度的原子能力,并不维护流之间的复杂关系。这样就避免了过于复杂的系统带来的木桶效应,从而就不需要过多考虑其它依赖可能带来的性能瓶颈。例如整个流媒体系统里是不依赖长连接服务的,信令通过http短连接来交换(当然我们也有独立的长连接服务,但是由业务使用者维护的,他们可根据课程模型实现复杂的房间逻辑,这样有利于快速支持不同的业务需求)。
- IDC单元下树状分发
大直播模式下zrtclive回源通过策略只会命中少数zrelay,从而减少内部消耗,而树状结构则可以方便大规模水平扩展来提高并发。
- IDC单元间网状中继
云服务提供商在单IDC的容量,特别是网络出口带宽是有限的,通过中继互联可以扩展多云多地域的IDC机房来实现高并发,其中多云服务器级联网络问题由基于网状的智能路由算法来解决。
- 结合业务属性优化调度方式
在对作业帮的课程模型充分分析的基础上,对不同模型、不同角色、不同时机做了定制优化。比如超级小班课的老师流非常关键,优先选用成本比较高质量最好的大直播模型;而小组之间学生的互看其实主要是起到烘托学习氛围的作用,并不需要频繁交流且人数不大于6人,所以这种模式,就选用低成本的会议模式,这6人都会调度到同机房的同一服务器的同一CPU上,从而极大地减少了各个环节的回源流数,性价比极高。顺便强调一点,拥抱变化、贴合业务,更接地气是自研RTC的优势,这是第三方云厂商通用RTC服务很难做到的。
2.程序方面
- 改良webrtc的架构
从多线程模型改为异步事件驱动模型。webrtc原生定位是客户端的点对点实时通信框架,多路流下会开辟很多线程,这样在高并发的服务器内,多线程的切换开销变大,不同线程之间的锁机制也使开发难度增加,有些开源的SFU其实就是这个模型,实际测试32C服务器只能运行1500路左右的媒体流而且抖动比较大。
- 多核分发
对于live大直播,我们使用无锁队列+共享指针+消息通知实现了单进程的多核分发模型,充分利用了多核性能。具体的介绍上一篇文章《在线教育场景下高并发低延迟直播技术实践》已经说明过,此处不在赘述。
- 系统优化
一般云厂商的虚拟机需要针对UDP收发做一些必备的优化,否则会遇到各种丢包或者CPU不均匀问题,当然首先要确认好云服务器的PPS(每秒收发包数,UDP分发服务器的关键指标)是否满足你的需求。
①合理配置网卡多队列属性。简单而言,网卡多队列是将收发数据的中断合理分配到不同的CPU核心上,充分利用多核分发能力。下图就是一个没有合理配置的CPU占用图,明显看出软中断集中到了前8核,从而产生性能瓶颈,无法充分利用CPU资源。
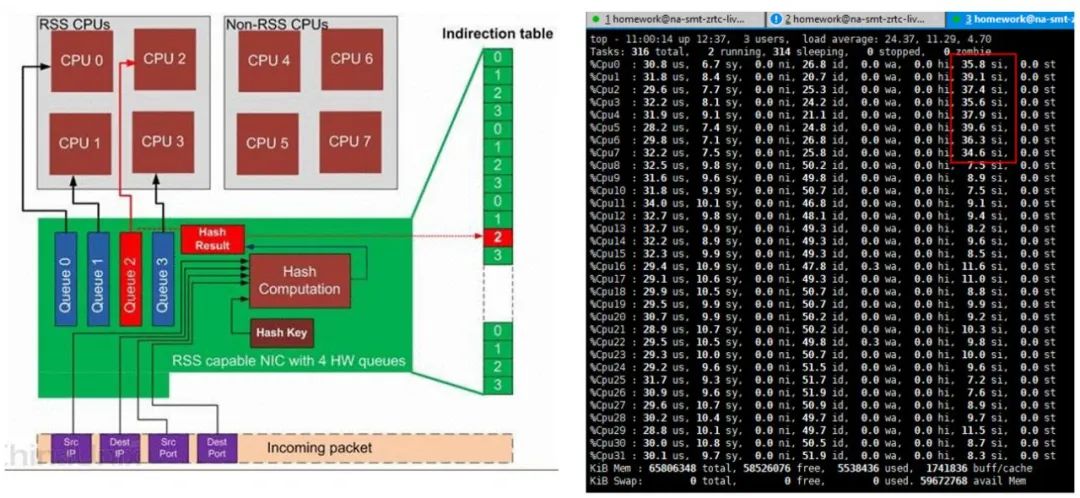
②配置足够的net.core.rmem_default/net.core.rmem_max/net.core.wmem_default/net.core.wmem_max。配置socket足够大的读写缓存大小,这个在UDP高带宽的分发服务中很关键,缓存不够大可能带来明显的丢包。
③系统版本,我们之前使用UDP的connect方式实现过单端口UDP服务器,但在低版本的内核下会出现随着UDP句柄数增大而性能非线性陡降问题。还有LINUX某内核版本下,UDP使用OPT_REUSEPORT接收数据在多核胡乱漂移的bug。之所以提到这些,主要是UDP的分发服务不像TCP那么成熟,因而每个团队的侧重点不同选择了不同的技术路线,但是遇到一些诡异的问题可以考虑下内核版本问题。
- 使用性能分析工具逐一优化代码
利用perf、valgrind等性能分析工具生成火焰图精细优化,尤其在数据分发链路上要更加苛刻,追求极致。由于valgrind不需要root权限,使用起来可能更加方便些。
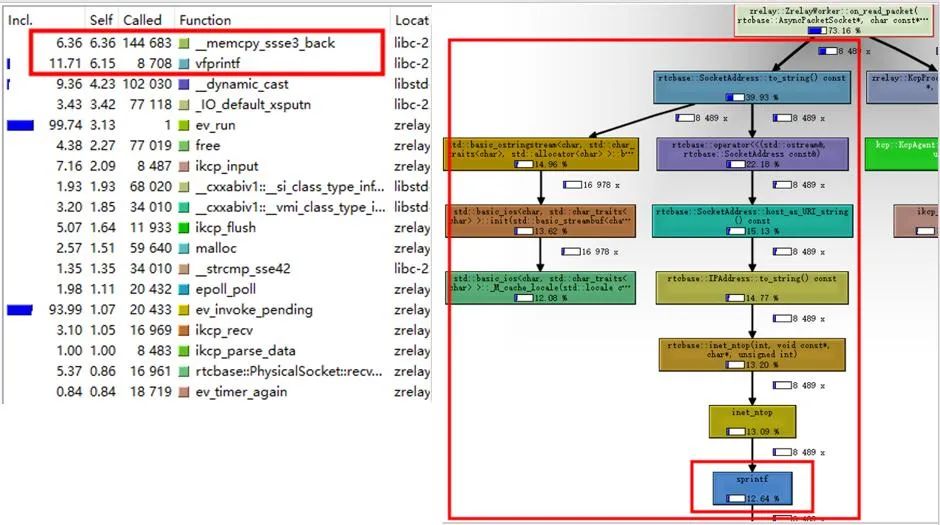
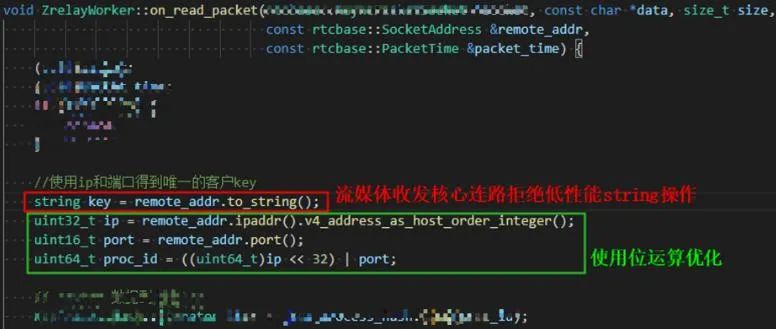
如上图左图,这是valgrind的性能分析结果,可以看到vfprintf这个函数占用了过多的消耗且调用次数频繁,我们继续跟踪这个函数得到如右图,发现sprintf函数来自on_read_packet中的to_string,这是一个字符串相关的操作,分析代码发现问题并且优化如下
- 多线程绑定CPU亲和性
ZRTC的分发服务是单进程多线程(一般单台服务器多少核就开多少线程),通过绑定到固定核心上不使用系统的自身调度,减少线程间的切换,从而提升性能。这个优化需要合理使用,要对服务设计、部署有充分的了解,不能有其他程序过分的抢占CPU,否则还不如交给内核自己调度,以免得不偿失。
- sendmmsg接口
sendmmsg,这个接口是可以减少系统调用频次的,实现一次调用发送多个包,实际测试时可以提高性能,但是改造的成本比较大,而且需要结合paced sender一起使用。
总之,系统配置还有关键路径的极致优化(有些从火焰图也无法发现的问题,就只能凭借经验和多次折腾了,比如事件驱动模型读写和分发表如何提升性能)才能实现单机的高并发。通过综合各种调优手段,最终ZRTC稳定承载了作业帮数百万流数的并发级别,单机32C虚拟机下提升到1.2W路以上(上一篇的并发数据4500是比较早期的),PPS在200W左右,单机总带宽6-8Gbps,idle50%。
三、如何高可用
1.架构方面
综合考虑负载均衡、熔断、限流、灾备、降级,实时报警、事后分析等,保证系统最大自愈时间15-20秒。其实这些是一般服务器的通用设计,在流媒体架构设计领域同样需要一一考虑,不同点在于流媒体服务其实是一个带“长连接”属性的服务,过程中稍微存在抖动,或者某种原因短暂中断,对用户的感受来说就是卡顿,所以各个节点的重连、异常捕获和自动切换机制必须非常完善,对异常判断的时间也要最大限度地快。
2.单一程序上
每一版程序在研发侧必须通过测试用例、valgrind内存检测、压测工具测试和“老化对抗测试”一整套流程后才可上线。webrtc的压力测试在业内一直是比较头疼的,无法找到那么多终端去模拟,所以我们又开发了自己的压测工具zrtcbench。我们去除CPU占比比较多的编解码和渲染,并配合多维度的数据统计来评估结果,实现了高性能的压测工具。“老化对抗测试”是一套常态化的类似测试巡检系统,通常会比较暴力的碰撞的调用流媒体的各种推拉流接口,观察服务是否有异常发生。
3.多云多协议多paas
系统设计初期,我们将系统定位成一个超级融合架构,无论从底层的云厂商还是上层rtc服务提供商,我们都考虑融合进来,最终实现相互容灾(服务不受单云主机或者网络故障影响,也不受单pass服务故障影响)、突发流量应对(合理调度流量分配到不同云、不同pass服务)、QOS互补(优先调度到区域质量好的服务上)、灵活降级(得益于统一的SDK接口,极端情况下以极低的代价可降级为RTMP)。融合架构为自研ZRTC在前期争取了平稳上线的时间,缓解业务压力;而容灾其实是相互的,由于总体并发流数相当高,对第三方服务商同样极具挑战,自研ZRTC期间多次帮助第三方服务商兜住了问题,防止重大事故发生。
四、如何高质量
1.建立客观指标,实验和线上双验证
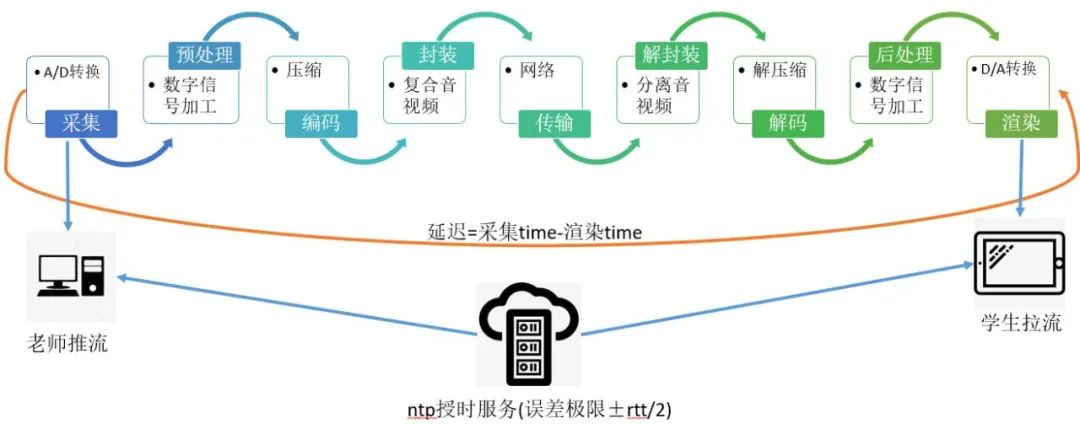
- 延迟指标建立
使用NTP校时服务器进行时间同步,ZRTC实现了采集到渲染的真正意义上的端到端延迟监控。校时误差取决于端上与NTP服务器的RTT对等程度,理论误差在正负RTT/2,实际测试延迟总体误差一般在10毫秒左右。
- 卡顿指标建立
卡顿是一个主观意识很强的指标,比较合理的方式是依据视觉惯性和最低忍耐帧率做一个综合计算。我们结合自己的场景(帧率15-20,两帧间隔67ms-50ms)为了更敏感的发现问题,同时简化指标计算,定义两帧间隔大于200毫秒为一次卡顿,卡顿率=卡顿总时长/播放总时长。经过和主观感受对比,老师讲课场景,200毫秒-300毫秒的卡顿需要仔细观察才能察觉,剧烈晃动200毫秒以上就能察觉,大于600毫秒以上的卡顿感官较明显。
- 单一化测试
ZRTC在SDK源码里嵌入了推文件流、模拟通用弱网环境(丢包、抖动、延迟、乱序)和特定弱网环境(对指定序号、帧类型的包数据弱网)等程序代码,最大限度的在优化测试中保证环境的一致性,当然也会结合丢包工具进行随机验证,最终综合卡顿率和延迟的变化得出结论,避免优化陷入拆东墙补西墙的怪圈。
2.webrtc合理使用
webrtc的原生定位是客户端的点对点实时通信框架,在使用其中丰富的抗弱网技术(NACK/FEC/NETEQ/jitter buffer/pacer等)时需要考虑某些边界和策略是否在自己的场景下是最优的。例如1对万大直播体系,原版由播放端请求I帧的GOP机制就不适应,需要改为固定GOP模式。
再比如webrtc源码在组完完整的I帧以后就清空了NACK列表,而I帧还未送去解码,在组完帧到解码的缓存时间里I帧前的P帧就没机会被NACK挽救。还有原版只会缓存一个I帧做依赖关系判断,不支持上一个GOP组的P帧依赖性判断,那么如果GOP的间隔是1秒,也就导致NACK只能解决1秒范围内的丢包。这些在追求极低延迟和I帧不频繁的webrtc原版定位尚可,但是一旦I帧变得频繁,场景不追求极致低延迟,似乎就不合时宜了。
3.服务端同样关键
有些SFU只做一层数据的中转,各类RTCP包,比如NACK全部由端去驱动,这种在需求单一或者人数较少的场景下可以满足。但是像一对万这种,如果推流丢包,那么必然会引起全量的接收端发送NACK,这样极大地消耗服务器性能,并且发送端跳过帧依赖关系发送数据,接收端也无法解码,服务端相当于发送了无用的数据。
基于此我们的链路其实是分段考虑QOS,第一段收流服务器具备SDK端大部分QOS能力,同时有自己独立的RTCP,如果源是一个复合场景流(例如一对万且有连麦需求),收流服务器会适当放大缓存时间保证源的流畅度。
第二段考虑到主要是IDC间的中继传输,服务器间网络一般较稳定,用好KCP(可靠的UDP)避免网络风暴,再加上动态路由切换,就能较好的满足诉求。
第三段发流服务器,服务端会判断帧的完整性和依赖关系(LTR和SVC多种形式依赖关系),根据接收端对延迟和流畅的敏感程度,确定不能解码的暂时不发送,连续的或者能恢复解码的帧才会继续发送,使用SVC和LTR多形式帧依赖关系也是平衡流畅和低延迟的有效解决方案。
第四段SDK也会根据自己的业务场景做缓存时间的设置,控制低延迟和流畅度的平衡。例如一对万且有连麦场景,吃瓜群众我们使用准低延迟重点保证流畅,连麦使用超低延迟保证交互。
4.分场景尽力优化
QOE优化是一件持续且复杂的工作,有些优化点只有在特定环境下才能发挥作用,有些优化点经过改良也能扩充使用场景,这就需要依据特定环境优化组合。比如LTR原本定位是请求应答式的使用方式,适用与1V1或者少数人的会议场景,但是我们将其改良到1对万模式下提升弱网下的流畅度。
我们将I帧设置为长期参考帧,把请求应答模式改为编码端依据上行丢包率自适应+固定间隔生成只参考I帧的P帧(“小I帧”),这样就打破了IPPP的依赖关系,如果gop中P帧丢失,“小I帧”到达就可快速恢复解码。
但是这个场景有一个限制条件就是编码场景变化不能太复杂,否则跨帧参考的压缩率太低,生成过大“小I帧”,失去了优化的意义。所以我们只在小组直播间模式下才会开启,其他复杂的场景下都是关闭的。
一些思考和反思
1.通用设计和结合业务做优化要把握好平衡度。系统架构和API接口要尽量兼顾通用性和场景个性化,做好分层设计,提供不同层次的能力,结合业务的优化点,做到有更好,如果没有也能使用,自研系统做成特定场景有优势,通用场景(满足未来)也适用。
2.一定要注意webrtc原版是端到端的追求低延迟的方案,在做1对万或者复杂场景时一定注意其特有的边界点,做适当思考。
3.一切QOE优化要考虑业务场景(有些场景流畅清晰更重要,不必过分追求低延迟,合理的满足业务才重要),过程和结果要保持严谨,避免拆东补西。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。