
基于多假设的预测已被反复证明在提高预测精度和增强编码性能方面是有效的。这篇论文将多假设的原理引入压缩失真屏幕内容图像的超分辨率任务。训练时,输入多个 LR 低分辨率图像块,包括当前块和五个相邻块,为高分辨率图像的学习提供更多信息。推理时,输入的 LR 图像将以随机的偏移量进行偏移,产生五个辅助 LR 块。LR 块和辅助 LR 块使用不同的模块进行特征提取,然后串联起来并经过多个连续的残差块,最后使用 PixelShuffle 获得重建 SR 图像。
随着数字移动设备的迅猛发展,屏幕内容图像已经渗透到人们的工作和娱乐中。用户经常会在会议或课程期间放大图像尺寸,而这些屏幕内容已经有了编码失真。因此,有必要研究一种针对屏幕内容压缩失真图片的超分辨率(SR)方法。
现有的 SR 方法主要集中在自然场景图像上。与通常包含传感器噪声的自然场景内容不同,屏幕内容是由计算设备产生的无噪声内容,具有高对比度和锐利的边缘。此外,现有的方法主要是对未受编码失真污染的图像进行恢复。因此,现有的图像超分方案不能很好地处理被压缩的屏幕内容图像的高分辨率恢复。
在视频编码中的运动补偿中提出了多假设的概念,在其中对假设的数量、编码比特率和补偿精度进行了全面的探讨。本文首先将多假设建模为一般意义上的平均加权预测,并找出影响补偿精度的因素,随后提出了多假设 SR 框架。多假设可以被看作是一个插件功能,它可以很好地与不同的网络结构合作,只需在接口上做微小的修改。最后,通过大量的实验评估了所提方法的优点。
提出的 SR 方法
作者首先证明,基于多假设的图像补偿,对于特定的补偿精度 (像素整数精度),随着假设数 的增加,误差的功率谱密度 呈下降趋势。因此,引入多假设可以降低预测误差的谱密度,提高预测或补偿的准确性。
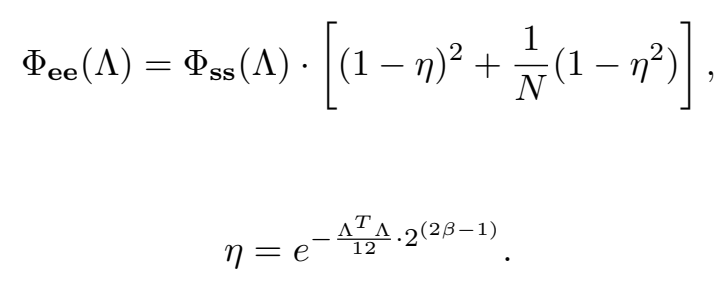
下面在 SR 学习中引入多假设的思想。将 HR 块的左上角的坐标表示为(x0,y0)。一般来说,在 LR 中位于 (x0/s,y0/s) 的图像块用于重构 HR 中位于 (x0,y0) 的图像块,其中 s 表示 HR 和 LR 之间的比例因子(如 2X,3X,4X 等)。这里使用多个低分辨率图像块输入网络训练,除了对应的 LR 图像块,还包括其邻近的 4 个图像块。如下公式,四个图像块(n=1,2,3,4)的偏移为 :

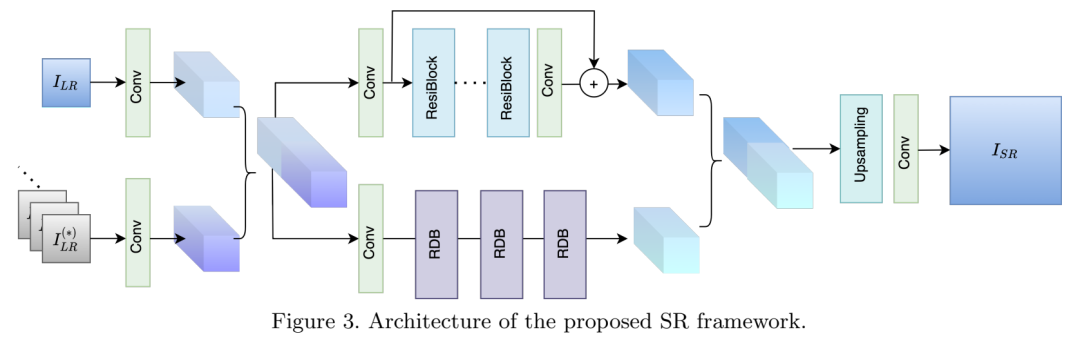
超分网络的结构如下图所示。给定当前的 LR 和邻域的四个图像块 LR*,分别输入单个卷积层转为特征域,之后拼接在一起。拼接的特征分两路分别输入残差模块和 RDB 稠密连接网络,以学习当前图像与其假设的相似性和差异性,之后再拼接到一起。最后,使用 PixelShuffle 和一个卷积层获取重建图像。
由于多假设可以辅助当前图像的恢复,识别假设间的相似度就显得尤为重要。这激励作者采用一个残差稠密连接块(RDB)网络作为残差网络的平行分支。
实验结果
作者针对屏幕内容压缩失真图片构建了一个 SR 数据集,共收集了 200 个屏幕内容图像,包括游戏场景、网页、文档和计算机生成图形。LR 图像由 HR 图像做 bicubic 下采样生成。之后使用 VTM-8.0 在 AI 配置下对 LR 进行压缩,量化参数设置为 22、27、32、37 和 42。在每个数据集中,160 张图像用于训练,20 张用于验证,20 张用于测试。
在该网络中,中间卷积层的滤波器大小为 3×3。残差网络分支中残差块的数量为 16。此外,RDB 网络分支包含 3 个 RDB,每个 RDB 包含 8 个卷积层。batchsize 为 16,输入图像块大小为 48×48,使用 ADAM 优化器,和均方误差(MSE)损失函数。学习率初始为 1×10^-4,每 2×10^5 个 batch 将衰减一半。
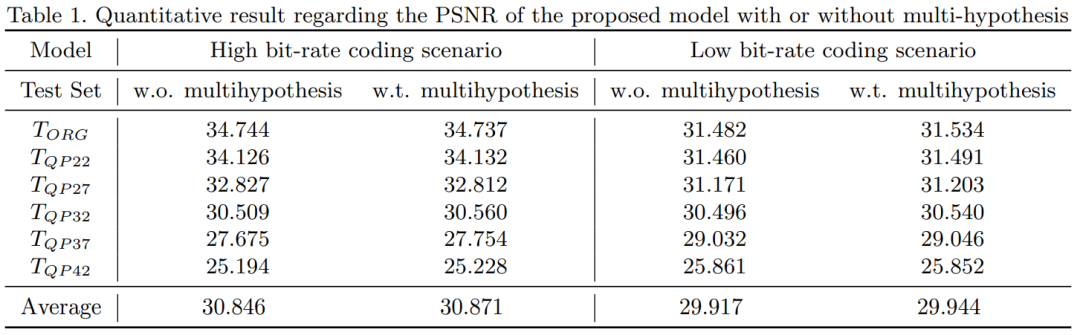
作者训练了两个模型 S-HB 和 S-LB,分别适用于高比特率和低比特率的编码场景。作为比较,使用经典的 EDSR 基线 (EDSR-BL) 模型,并在提出的数据集上重新训练。表 1 和表 2 列出了 X2 超分的亮度分量的 PSNR 性能。在高比特率编码和多假设预测情况下,提出网络的平均性能分别为 30.846dB,EDSR-BL 的性能分别为 30.442dB。在低比特率编码场景中也可以观察到类似的趋势。
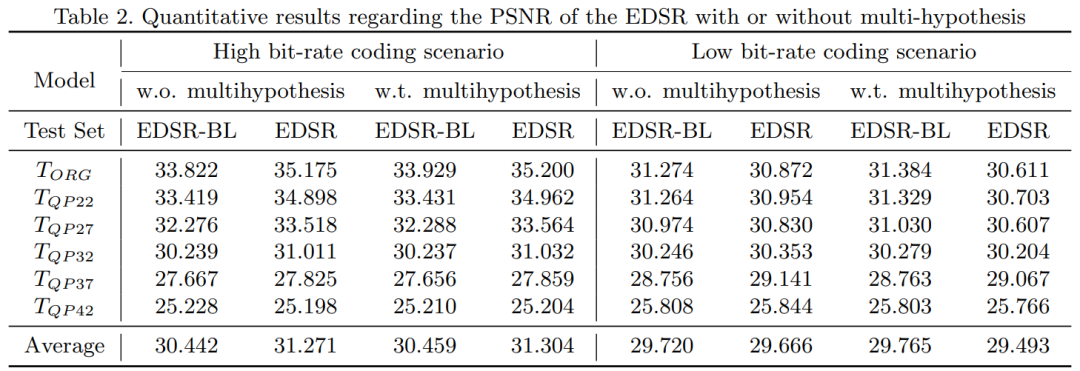
随后,作者在 EDSR 网络的基础上验证了多假设策略的优点。在本实验中,EDSR-BL 为 16 个残差块 64 通道,EDSR 为 32 个残差块 256 通道,都在提出的数据集上进行了训练。如表 2 所示,高码率情况下,对于两个网络,多假设的增益分别为 0.017dB,0.033dB。在低比特率编码情景下则是 0.045dB,-0.173dB。因为在低比特率时,屏幕内容图像会严重失真,EDSR 模型虽然具有较大的模型容量,但它更注重畸变补偿而不是高分辨率恢复。
来源:SPIE 2021
主讲人:Meng Wang
内容整理:冯冬辉
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
