
在过去几年中,去噪扩散概率模型(DDPM,简称扩散模型)在许多生成任务中获得了最先进的结果,优于GAN和其他类型的生成模型。特别是,他们在各种图像生成子任务中取得了令人印象深刻的结果,其中条件生成任务如文本引导图像合成。鉴于DDPM在2D生成中的成功,它们最近被应用于3D形状生成,超过了以前的方法,并达到了最先进的结果。然而,3D数据带来了额外的挑战,例如3D表示的选择,这会影响设计选择和模型效率。虽然在生成质量方面达到了最先进的结果,但现有的3D DDPM工作很少或根本没有使用指导,主要是无条件或类条件的。在本文中,作者提出了IC3D,这是第一个通过图像引导生成3D形状的图像条件3D扩散模型。这也是第一个采用体素作为3D表示的3D DDPM模型。
来源:https://arxiv.org/pdf/2211.10865.pdf
作者:Cristian Sbrolli
内容整理:桂文煊 —— 煤矿工厂
文章概述及其贡献
该文章提出了第一个基于单视图图像条件生成三维形状的DDPM Model。文章的主要贡献有以下几点:1、提出CISP——一种利用对比预训练来学习联合图像形状嵌入的模型。2、利用CISP指导DDPM进行图像引导形状生成。3、证明可以采用DDPM来生成基于体素的3D数据。4、IC3D比SoTA形状生成模型的结果更真实,并有强大的图像一致性 5、研究了CISP学习的嵌入空间的正则化和泛化能力,得出:(1)可以通过流型学习进行插值,生成一致的形状;(2) 学习的空间泛化到相关的输入域,可以实现草图到形状的生成。选择体素是因为无需引入其他额外的体系结构复杂性例如点云的使用需要特定的权宜来正确处理无序点集,如排列不变量(permutation invariance)和局部性利用(locality exploitation)。
整体模型
IC3D的形状生成流水线如图1所示,预训练模型CISP(对比图像形状预训练)预先学习联合图像形状嵌入空间。给定一个查询图像,生成其CISP嵌入,并将其与附加的token一起用于条件化3D去噪扩散概率模型(DDPM)。以这种方式,IC3D可以生成不同的3D形状,整个流水线都保持了与查询图像的真实性和一致性。
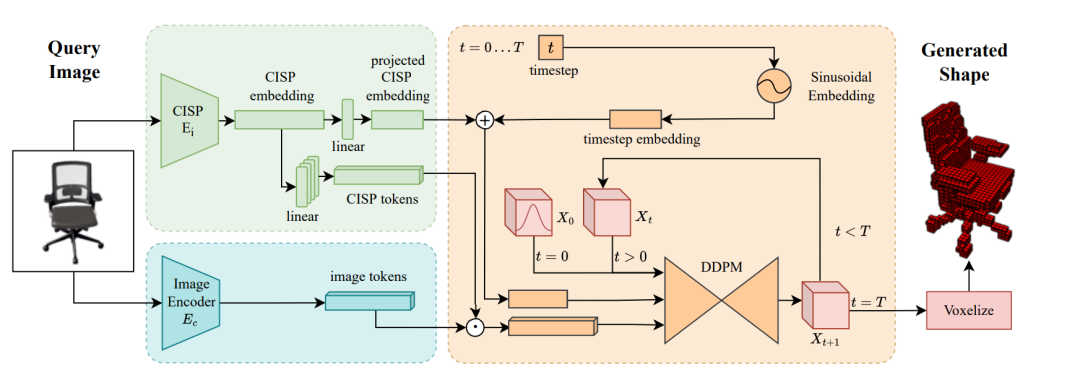
CISP(对比图像形状预训练)
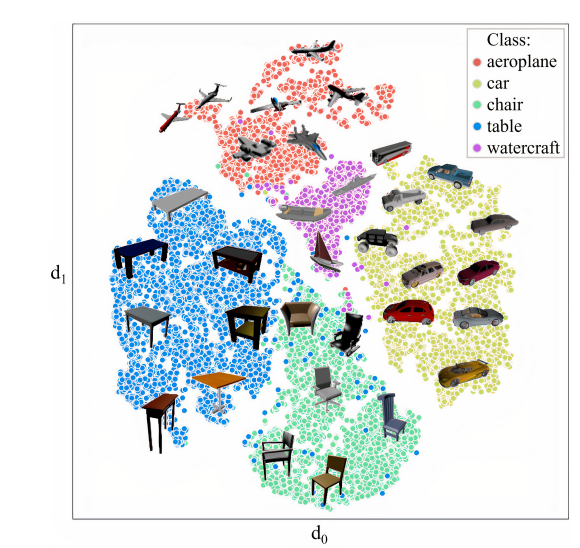
定义处理形状的编码器Es和处理图像的编码器Ei然后他们能够输出一个大小为f的embeddings,以作为后续DDPM模块的条件,进行图像引导形状生成。对于Ei来说,不同于CLIP中利用Vit作为image encoder,这里由于数据集有限,使用了DeiT(高效数据图像转换器),DeiT Base 使用768维隐藏嵌入和12层,每个层有12个关注头。而对于形状编码器Es来说,作者将ViT模型扩展到3D。具体做法如下:将2D卷积(将图像映射到面片嵌入)替换为3D卷积(将体素形状映射到面片插入)。一个可学习的token被预先添加到输入序列中,由网络处理,然后被投影到期望的嵌入维度。该技术使模型能够轻松地提取图像(或形状)CISP嵌入。图2显示描述了shape在embedding space的示例图像。对于上图可以观察模型如何捕捉细节和子类别,比如桌子的高度随着d1增大而减小。
对于该模块的训练,目标为将图片和形状进行良好的配对,训练过程如下:给定一个batch,其中包含N对相关的image-shape对,经过Ei和Es生成image-shape embeddings,再计算image embedding(行)和shape embedding(列)之间的对称N×N相似矩阵,计算余弦相似度。训练Loss由两个交叉熵组成,衡量预测给定图像形状的能力。训练目标为最大化匹配N个image-shape对的相似度,类似于CLIP。
架构
作者扩展了GLIDE中使用的架构,该架构基于ADM模型。改动如下:(1)用3D卷积代替2D卷积;(2) 将文本编码器替换为图像编码器Ec,选择其作为DeiT模型;(3) 以两种方式使用CISP图像嵌入:首先,将它们投影并添加到时间步嵌入中;第二,在网络的每个关注块中,我们将CISP嵌入到四个额外的token中,并将它们连接到attention context(键、值)中;(4) 我们将8个可学习的token添加到Ec中,并使用相应的输出作为额外的attention context,就像CISP嵌入一样。
分类器引导
利用classifier-free guidance(分类器引导)来训练模型,消除了单独分类器的需要,获得了与分类器引导相似的结果。首先,作者联合训练一个条件模型和一个无条件的模型,然后通过组合他们的分数估计来朝着分类器引导的方向做出预测。联合训练条件模型和无条件模型的过程中,作者用概率p替换为空token∅的输入条件。在生成过程中,用学习到的空token∅替换image token不会影响模型性能,且表明Ec只在训练过程起关键作用,因为若用空标记代替CISP embedding,则无法生成和引导图像一致的形状。
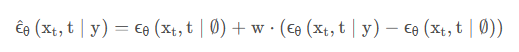
y是guidance token,w为guidance scale。
实验及其结果
定量结果
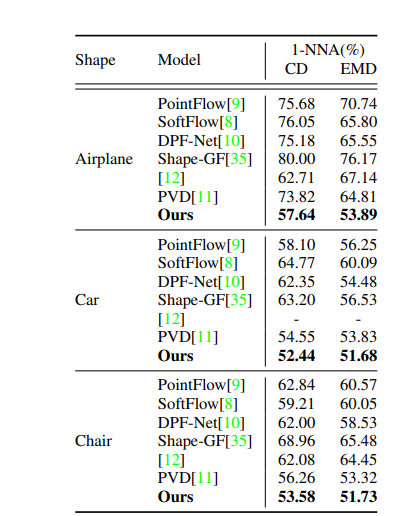
作者将模型生成结果与SoTA生成的结果进行了比较,比较值为最近邻精度(1-NNA)。定量比较结果如图3所示,结果表明作者提出模型明显优于其他的SoTA 3D生成模型。
从草图生成形状
图4展示了输入草图后生成最终形状的结果,良好的结果表明了模型具有良好的有效性以及泛化能力。

插值
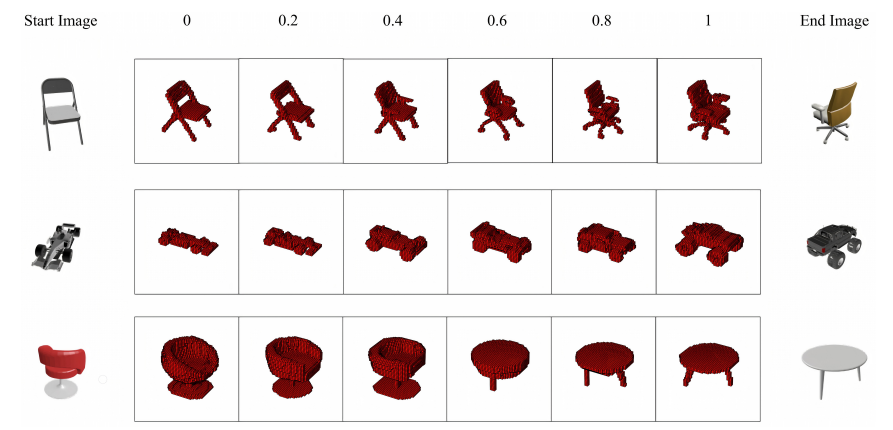
图5显示了模型获得的插值形状的一些示例。作者证明了类内和类间插值都是有效的,进一步证明了CISP嵌入空间捕获的知识的相关性。请注意第一行中的轮子和扶手是如何添加到原始椅子结构中的,然后再将其转换为办公椅。还要注意最后一行中,椅子首先被填满,然后底座被移除,最后腿被添加,完成了向桌子的转换。
局限性及展望
目前的局限性为IC3D的采样速度低,同DDPM一样存在相同的问题。作者对于未来工作的展望有以下几点:1、目前该模型只在ShapeNet上进行训练,若在更大的数据集上训练CISP可以有更强的泛化能力。2、利用CISP embedding将单视角拓展到能获取多视角。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
