
1、引言
视频修复是一项为视频帧中的缺失区域填补合理内容的任务,具有多种实用的应用场景,例如对损坏的视频进行修复、对不需要的对象移除、视频重定位和曝光不足的图像修复等。然而保证画面内容的时间逻辑性一致一直是一个难题。

2、传统方法
在最先进的方法中,为了解决内容的逻辑一致性问题,加入了attention机制用于保持对长时间的视频帧的关注。
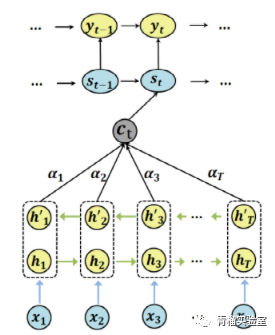
●输入:(x1,x2,…,xr),输出:(y1,y2,…,yt)
●Encoder:双向的RNN或LSTM,计算得到每个位置的隐状态,下面用hi表示
●Decoder:对当前输出位置 t,使用Decoder中上一个隐状态st-1与Encoder的结果(也就是向量ct)计算t位置对应的yt。
这类方法通常假设全局仿射变化或者齐次运动,这使得它们很难建模复杂的运动;另一种局限性是所有视频都是逐帧处理的,而没有专门设计的时间一致性优化。
3、时空联合的Transformer网络
Spatial-Temporal Transformer Network(STTN)将视频修复描述为一个“多到多”的映射问题,它以相邻帧和远帧作为输入,同时填充所有输入帧中的缺失内容。为了填补每个帧中的缺失区域,Transformer通过一个基于多尺度块的注意力模块搜索相关内容,包括时间维度和空间维度。
具体的说,STTN从所有帧中提取不同尺度的块,以覆盖由复杂运动引起的不同外观变化,Transformer的不同头部计算不同尺度上空间块的相似性。通过这种设计,聚合不同头部的注意力结果,可以检测并且为缺失区域匹配到最相似的patch。此外通过堆叠多层,可以改善对缺失区域的注意力结果。
总体来说,STTN网络的主要优势如下:
1.通过深度生成模型和联合时间和空间维度的对抗训练,学习时空域的转换完成视频修复;
2.所提出的基于多尺度块的视频帧表示可以实现快速训练和推理,这对于视频内容的理解非常重要;
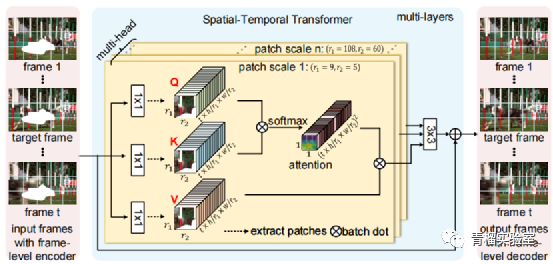
为了填补每个帧中的缺失区域,Transformer设计为从所有输入帧中搜索相关内容,用一个基于multi-head multi-patch的注意力模块沿着空间和时间维度进行搜索。不同Transformer的头部计算不同尺度的空间块块,这种设计使得网络能够处理由复杂运动引起的外观变化。例如大尺寸的块块关注于完成修复不变的背景,小尺寸的块块完成对移动的前景的修复。
Multi-head 结构能够针对不同块大小的情况同时对输入的图像序列中所有图像同时进行“编码-匹配-注意力”。在编码过程中,每一帧的特征被映射为query和memory(即key-value对)以供进一步检索。在匹配过程中通过匹配从所有帧中提取的空间块块之间的query和key计算区域相似性。最后在注意力过程中检测并转换每帧中缺失区域的最相关区域。
4、效果分析
DAVIS数据集由150个具有挑战性的摄像机运动和前景运动的高质量视频组成。下表展示了五类模型在DAVIS数据集上的定量测试效果,其中*指数越高越好,+指数越低越好。
| Models | PSNR* | SSIM(%)* | Ewarp(%)+ | VFID+ |
| VINet | 28.96 | 94.11 | 0.1785 | 0.199 |
| DFVI | 28.81 | 94.04 | 0.1880 | 0.187 |
| LGTSM | 28.57 | 94.09 | 0.2566 | 0.170 |
| CAP | 30.28 | 95.21 | 0.1824 | 0.182 |
| STTN | 30.67 | 95.60 | 0.1779 | 0.149 |
Table1.与最先进的方法在DAVIS数据集上的定量比较数据
从表中可以看出,STTN网络具有更好的视频重建质量,在很大程度上优于最先进的模型,具有技术先进性。
作者:魏云娜 | 来源:青榴实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
