
摘要:在本次演讲中,我们讨论了基础模型如何开始验证 70 多年前形成的假设:更好地压缩源数据的统计模型最终会从中学习更多基础和通用功能。我们首先介绍压缩的一些基础知识,然后描述跨越数千亿个参数的更大的语言模型实际上是最先进的无损压缩器。我们讨论了在实现最佳压缩的过程中可能会出现的一些新兴功能和持续限制。
内容整理:张志宇
来源:Stanford MLSys Seminar
主讲人:Jack Rae(OpenAI)
视频链接:https://www.youtube.com/watch?v=dO4TPJkeaaU
背景:Jack Rae 是 OpenAI 的团队负责人,主要研究大型语言模型和远程记忆。此前,他在 DeepMind 工作了 8 年,领导大型语言模型 (LLM) 研究组。
演讲主题
- 深入思考基础模型的训练目标
- 思考我们正在做什么,为什么这样做是有道理的,局限性是什么
要点
- 找到解决感知问题的最小描述长度
- 生成模型是无损压缩器
- 大语言模型是 SOTA 的无损文本压缩器
- 现有压缩方法的局限性
最小描述长度

想象一个电脑软件需要把英文翻译成中文,如果它是通过查找字典把所有可能的词组翻译成中文,那么我们可以认为它对翻译任务有着最差的理解,因为任何出现在字典之外的词组它都无法翻译。但如果将字典提炼为较小的规则集(例如一些语法或基本的词汇),那它将会有更好的理解能力,因此我们可以根据规则集的压缩程度对其进行评分。实际上,如果我们可以把它压缩到最小描述长度,那么我们可以说它对翻译任务有着最好的理解。



目前我们通常使用的基础模型是生成模型,我们可以使用生成器模型以非常精确的数学格式来表征数据集的无损压缩,因此我们可以尝试使用生成模型来找到最小描述长度。
图中 | D | 表示数据集 D 的无损压缩,无损压缩的大小可以表示为对 D 评估的生成模型的负对数似然加上估计函数的最小描述长度(对于神经网络,我们可以将其视为初始化网络的代码量,并不被神经网络的大小所影响)。需要注意不能给 f 输入过多的先验(即使输入先验会使得模型表现更好,但实际压缩性能会下降)。

假设我们在 D 上预训练 f,使得对数似然为 0,那么这个模型对于 D 的描述是完美的,但此时 f 的描述长度包含了 D 的描述长度,即 f 对于 D 的压缩毫无帮助。
用大语言模型进行无损压缩
下面针对大语言模型来具体讨论。

|D| 可以表示为 next-token 预测损失加上 transformer 语言模型的描述长度(~100 KB)。
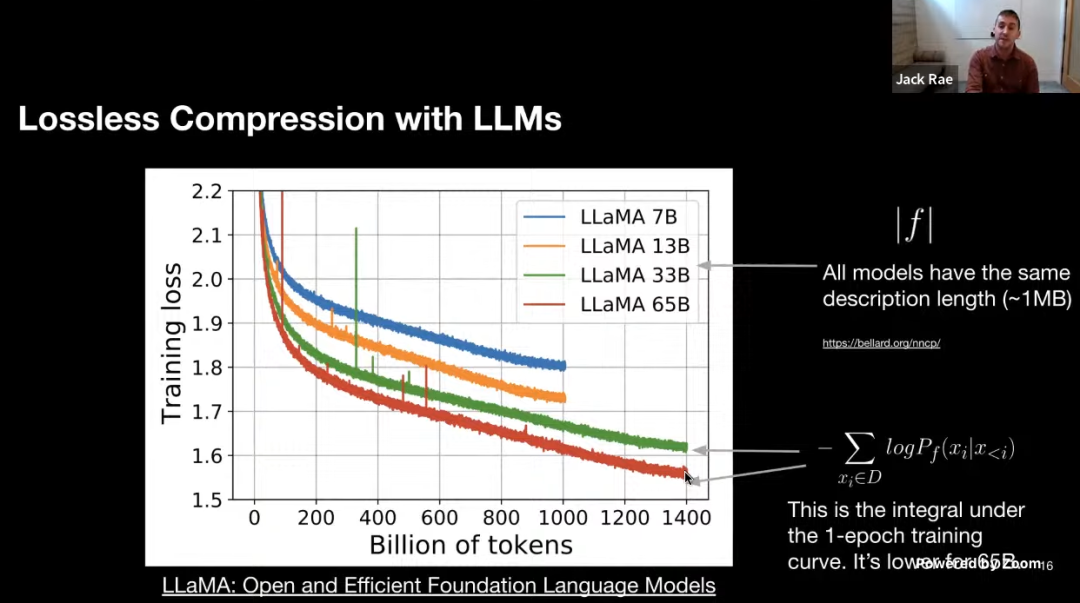
图中是 LLaMA 模型的一些训练曲线,绿线和红线表示的两个模型只在数据集上训练了 1 个 epoch,因此可以把训练损失视为 |D| 中的 next-token 预测损失。同时我们也可以粗略地估计模型的描述长度(~1MB)。即便模型的参数量不同,但 LLaMA 33B 和 LLaMA 65B 两个模型有着相同的数据描述长度(用于训练的代码相同)。但 65B 模型显然有着更低的训练损失,把两项相加,可以看出 65B 实际上是更好的压缩器。
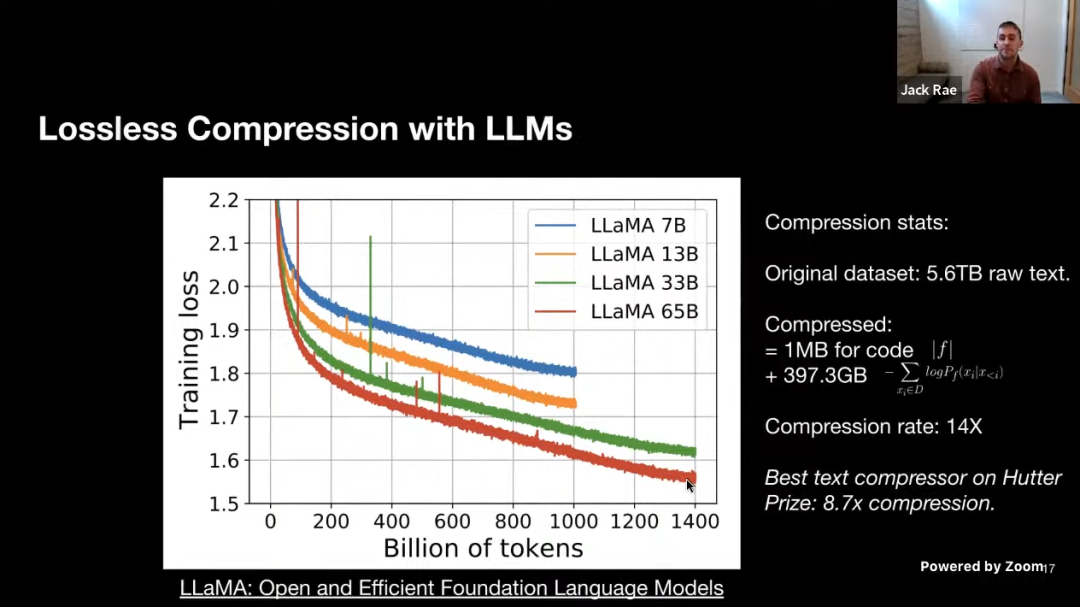
这是一些更具体的数据,用于初始化和训练模型的代码约为 1MB,粗略地计算负对数似然大约是 400GB,而用于训练的原始数据是 5.6TB 的文本,因此该模型的压缩率为 14 倍。而 Hutter Prize 上最好的文本压缩器能实现 8.7 倍的压缩。实际上我们正在创建更强大的模型,为我们的训练数据提供更低的无损压缩率,即便中间模型本身可能非常大。
具体实现
前面我们已经了解了为何大语言模型是无损压缩器,下面将讲解如何利用大语言模型实现像生成模型这样的压缩机制。
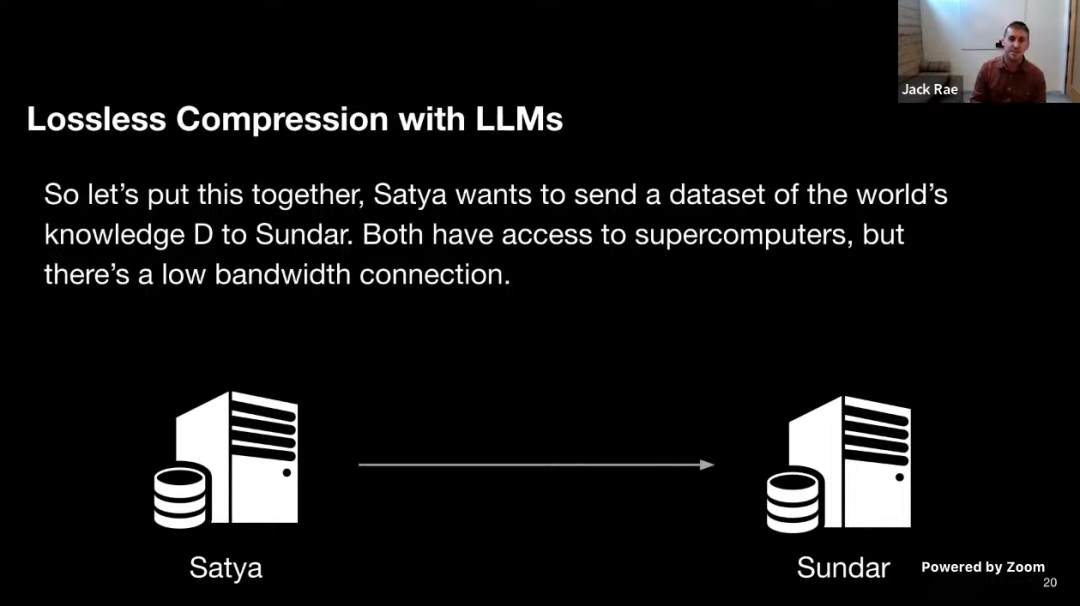
假设这么一个场景,Satya 想要传输包含世界知识的数据集 D 给 Sundar,他们都可以连接到超级计算机,但带宽连接很小。

我们可以使用算术编码,假设我们在时间戳 t 有一个 token xt,并且概率分布是 pt 。简单来说,算术编码就是将 token xt 映射为 zt(压缩后的表征),zt 占用 -log2pt(xt) bits。事实上真正实现实现算术编码可能需要无限精度的计算,而在现实使用时往往需要付出额外的 bit,但算术编码在编码方面大致可以算是最优的。解码 zt 时仍然需要用到分布pt 。
以 pt 是均匀分布为例,此时存储 xt 需要 log2|V| 的空间,这跟直接二进制存储是一样的。当我们确切地知道 xt 是什么(即pt(xt)=1 )时,不需要耗费存储空间。这是两个极端的例子,说明了我们需要一个足够好的生成模型来塑造我们的数据,它可以使用更少的空间。

回到刚刚的例子,所以在实践中我们应该怎么做?Satya 在数据集 D 上训练一个 transformer,然后记录 next-token 概率分布,然后使用算术编码来对数据进行编码。
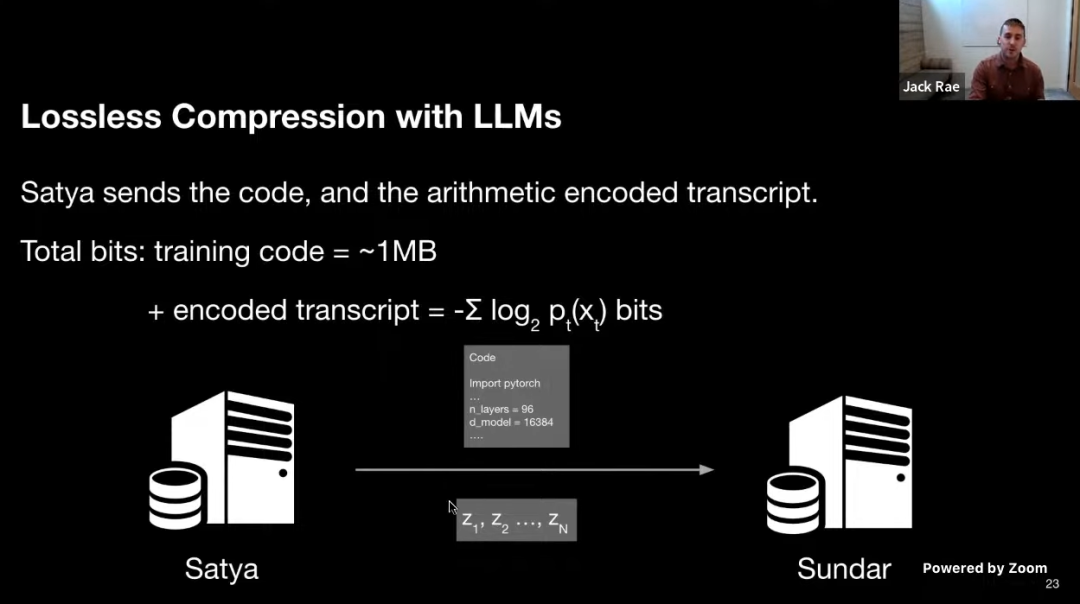
然后 Satya 把代码和算术编码后的 z 发送给 Sundar,训练代码约为 1MB,编码抄本为 -log2pt(xt) 。也就是说实际上,他并没有发送神经网络(可能几千万甚至上亿参数),而只是发送了训练的代码。

在 Sundar 这端,他运行确定的训练代码:使用相同的初始化网络进行初始化,在时间戳 1 模型使用 P1 对 Z1 进行算术解码得到 X1,然后经过一个训练步长使得网络预测出 P1,之后迭代地遍历并恢复整个数据集。这看起来更像是一个思想实验,因为这需要大量的中间计算资源才能达到如此高的压缩率。有个有趣的事实是,利用大语言模型进行无损压缩的想法与香农的信息熵定理不谋而合。

之前我们讨论了为什么大语言模型是最先进的无损压缩器,现在我们讨论如何解决感知问题并转向 AGI 的诀窍是什么。这主要分为两步:一是收集所有有用的感知信息,二是学习使用强大的基础模型来尽可能地压缩数据。这样做的好处是你可以从任意的角度,使用任意的研究方法来提高压缩的效率,例如改进网络架构、使用生成数据来辅助生成等。

对于使用神经网络进行压缩目前还存在很多的困惑。通常神经网络的权重可以被视为对源数据的有损压缩,然而这是一个糟糕的有损压缩算法。因为传输网络权重本身有可能会消耗比源数据更多的空间,而且实际上会丢失很多源数据的信息。

图中红色圆圈表示训练数据,从有损压缩的角度来看,神经网络在红色圆圈中丢失了数据(甚至不能很好地重建出训练集),但我们更在意的是神经网络的生成能力,或者说泛化性。这里我们需要重新审视我们的目标,也就是说我们其实并不在于神经网络对于红色圆圈的重建能力如何,我们在意的是神经网络对于白色圆圈的表示能力。而我们训练神经网络去重建红色圆圈数据只是为了得到更强的泛化性。
局限性和总结

前面我们讨论了使用语言模型进行压缩的机制,并将其与有损压缩的混淆联系起来,下面讲讲一些局限性。
- 压缩有可能是正确的,但效率不高
像素级图像的建模是一个很好的例子,对于像素级图像进行建模是十分昂贵的,因此研究者更多开始尝试使用语义信息进行建模。 - 很多有用的信息是不可观察的
一个典型的例子是 Alphazero,你可能只观察到了他可以进行围棋的自我博弈,但忽略了在训练它时用到了很多其他游戏的中间搜索结果。它看起来更像是一个代理人,可以通过搜索中间结果实现不同行为。

因此我们可以得出一些结论。
- 目前更好的压缩实体是可扩展的,但可扩展并不是你所需要的全部
- 有很多的算法的先进之处等待被发掘
- 几乎所有主要的 LM 模型的进展与更好的文本压缩同义
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
