
本文提出了一个新颖的框架,可以从单一野外视频中重构人物和场景,并能够渲染出新的人体姿态和视角。给定一段由移动相机捕捉的视频,作者训练了两个 NeRF 模型:一个是人类的 NeRF 模型,另一个是场景的 NeRF 模型。为了训练这些模型,作者依赖现有的方法来估计人物和场景的粗略几何形状。这些粗略的几何形状估计允许作者创建一个从观测空间到规范的姿态无关空间的变形场,作者在这个空间中训练人类模型。作者的方法能够从仅有的 10 秒视频剪辑中学习特定个体的细节,包括衣物皱纹和配饰,并在新的姿态和视角下,连同背景一起提供高质量的人体渲染。
来源:ECCV 2022
原标题:NeuMan: Neural Human Radiance Field from a Single Video
论文作者:Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, Anurag Ranjan
内容整理:王彦竣——煤矿工厂
引言
本文研究仅提供单个视频的情境,旨在重建人体模型和静态场景模型,并实现对人体的新姿态渲染,而无需昂贵的多摄像机设置或手动注释。然而,即使在 NeRF 方法的最近进展下,这仍然不是微不足道的。现有的方法需要多摄像机设置、一致的光照和曝光、干净的背景和准确的人体几何形状来训练 NeRF 模型。表格中显示的 HyperNeRF 基于单个视频建模动态场景,但不能由人体姿态驱动。ST-NeRF 从多个摄像机中使用时变的 NeRF 模型重建每个个体,但编辑仅限于包围盒的转换。Neural Actor 可以生成人体的新姿态,但需要多个视频。HumanNeRF 基于单个视频构建人体模型,使用手动注释掩膜,但不能将其推广到新姿态。Vid2Actor 使用在单个视频上训练的模型生成人体的新姿态,但不能建模背景。作者通过引入 NeuMan 来解决这些问题,它可以从一个单独的野外视频重建人体和场景,并具有渲染新的人体姿态和视角的能力。
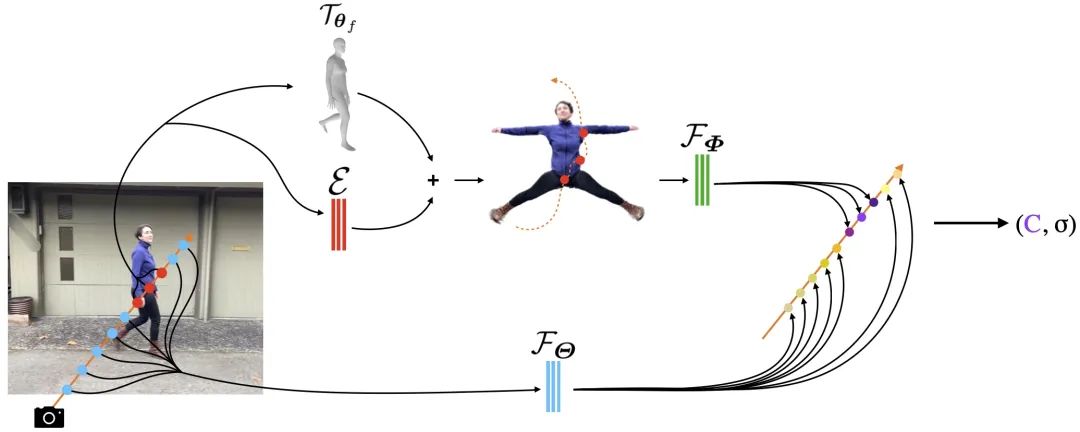
NeuMan 是一个新的框架,用于训练 NeRF 模型,同时适用于人物和场景,可以实现高质量的姿势驱动渲染,如下图所示。通过使用常规的现成方,作者首先估计移动相机拍摄的视频中的人物姿态、人物形状、人物掩码以及相机姿态、稀疏场景模型和深度图。
然后,作者训练两个 NeRF 模型,一个用于人物,一个用于场景,由 Mask-RCNN 估计的分割掩码进行引导。此外,作者通过融合多视角重建和单目深度估计来规范化场景 NeRF 模型。
作者在一个姿势无关的规范空间(canonical volume)中,使用SMPL参数化模型,训练人物NeRF模型。作者改进从 ROMP 中 SMPL 的估计,以更好地服务于训练。然而,这些改进的估计仍然不完美。因此,作者以端到端的方式联合优化 SMPL 估计和人物 NeRF 模型。
由于静态规范人体 NeRF 模型不能表示 SMPL 模型未捕获的动态行为,因此作者引入一个错误校正网络来解决它。SMPL 估计和错误校正网络在训练期间进行联合优化。
先导:神经辐射场

方法
本方法的框架概述如下图所示。主要由两个 NeRF 网络组成:人体 NeRF 对场景中的人的外观和几何形状进行编码,并与人体姿态相结合;场景 NeRF 对场景背景的外观进行编码。作者先训练场景 NeRF,然后在训练好的场景 NeRF 的条件下训练人体 NeRF。
场景 NeRF 模型
场景 NeRF 型类似于传统运动检测工作中的背景模型,但它是一种 NeRF 模型。对于场景 NeRF 模型,作者构建了一个 NeRF 模型并只用被认为是背景的像素进行训练。

预处理: 给定一个视频序列,作者使用 COLMAP 来获取相机姿态、稀疏场景模型和多视角立体(MVS)深度图。通常,MVS 深度图 Dmvs 包含空洞,作者使用 Miangoleh 等人提出的方法,利用密集的单目深度图 Dmomo 填充这些空洞。作者将 Dmvs 和 Dmomo 融合在一起,得到一个深度一致的融合深度图 Dfuse。更详细地说,作者使用具有两个估计值的像素之间的线性映射来找到两个深度图之间的映射关系。然后,作者使用该映射将 Dmomo 的值转换为匹配 Dmvs 中的深度尺度,并通过填充空洞来获得融合深度图 Dfuse 。
为了检索人的分割地图,作者使用 Mask-RCNN。作者进一步扩张人的掩膜 4%,以确保完全遮盖人体。利用估计的相机姿态和背景掩膜,作者只在背景上训练场景 NeRF 模型。
人体 NeRF 模型
为了构建一个可以被姿势驱动的人体模型,需要该模型具有姿势独立性。因此,作者基于“大”姿态(Da-pose)下的 SMPL 网格定义了一个规范空间。相比传统的 T-pose,Da-pose 在从观测空间到规范空间的腿部变形时避免了体积碰撞。
使用这个模型在观测空间中渲染一个人的像素时,作者将该射线上的点转换到规范空间中。困难在于如何将 SMPL 网格的变换扩展到整个观测空间,以允许在规范空间中进行射线跟踪。作者使用一种简单的策略将网格蒙皮扩展到体积变形场。



为了渲染一个像素,模型会发射两条光线,一条用于人体 NeRF ,另一条用于场景 NeRF。模型评估沿着这两条光线的样本的颜色和密度,然后根据深度值按升序对颜色和密度进行排序。最后,模型通过先导节中的体渲染方程对这些值进行积分,得到像素的值。
训练: 为了训练人体辐射场,模型在人体掩模覆盖的区域上采样光线,并最小化以下损失函数:

其中,w 是沿光线终止时的透明度,如先导节所定义。

预处理: 作者利用 ROMP 来估计视频中人类的 SMPL 参数。然而,估计的 SMPL 参数并不准确。因此,作者使用从 DensePose 估计的轮廓和从 HigherHRNet 估计的 2D 关节点来优化 SMPL 参数。最后将 SMPL 估计值对齐到场景坐标中。
场景对齐的 SMPL 模型: 为了将人类置于新视角和姿势中,以及训练两个 NeRF 模型,需要将这两个模型所在的坐标系进行对齐。这实际上是一个不容易解决的问题,因为人体姿态估计器通常在其自己的摄像机系统中操作,并采用近正交相机模型。为了解决这个问题,作者首先使用 COLMAP 相机内参解决了估计的 3D 关节和投影的 2D 关节之间的透视-点 (PnP) 问题。这可以解决对齐问题,但不确定比例尺。足总和假设人类至少在一个帧上站在地面上,并通过找到允许 SMPL 模型的脚网格触碰地面的比例尺来解决比例尺的模糊度。通过应用 RANSAC 来获取地平面。下图中展示了对齐后的 SMPL 估计结果。

一旦两个 NeRF 模型被正确对齐,作者可以通过发射两条射线来渲染像素,一条用于人类 NeRF 模型,另一条用于场景 NeRF 模型,如上文所述。为了在公式体渲染公式中生成样本的近和远平面,作者使用估计的场景点云来确定场景 NeRF 的近和远平面,并使用估计的 SMPL 网格来确定人类 NeRF 的近和远平面。
实验
下图体现了场景 NeRF 模型的新视角生成效果,模型有效的学到了场景一致的集合信息,并有效地取出来动态的人体。

下图展现了网络有效的学习真实的人体细节,它采集了材质信息如衣物的样式,同时保留了细节的几何形状如衣领,袖子。同时,这个人体模型可以合成在新视角下全新的姿态。

下表和下图对比了该方法与其他方法新视角生成的效果,本方法可以在动态场景下生成高质量的模型。


总结
作者提出了一种新颖的框架,用于重建人体和场景的 NeRF 模型,并可以从一段野外视频中渲染出新的人体姿势和视角。为此,作者使用现成的方法来估计场景和人体的 2D 或 3D 几何形状,以提供初始化。作者的人体 NeRF 模型能够从少于 40 张图像中学习纹理细节,例如衣物上的图案和衣袖、领口、拉链等几何细节。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
