
近日,ICASSP2023 通用会议理解及生成挑战(MUG)完成了测试集评测及结果公布,并举办了线上完赛沙龙。本次挑战由ModelScope魔搭社区、阿里巴巴达摩院语音实验室、阿里巴巴达摩院语言实验室、阿里云天池、浙江大学数字媒体计算与设计实验室联合举办,多位国内外行业专家包括达摩院语音实验室负责人鄢志杰、达摩院语言技术实验室负责人黄非、达摩院语音实验室资深算法专家王雯、浙江大学赵洲副教授等组委会成员参与了大会的组织和评审;伊利诺伊大学厄巴纳-香槟分校Heng Ji教授、Amazon Alexa AI 首席科学家Yang Liu、上海交通大学俞凯教授、中科院自动化所宗成庆研究员、埃默里大学Fei Liu副教授提供了技术咨询与指导。本次挑战赛共设置5个赛道,历时近2个月,总计300余人次报名参赛,最终47支队伍提交比赛结果。会议伊始,达摩院语音实验室负责人鄢志杰介绍了“人-人交互会议”场景任务的背景、技术挑战及应用空间;随即,达摩院语音实验室资深算法专家王雯对各赛道Top3队伍进行了线上颁奖并组织圆桌讨论;最后,各个赛道Top1队伍进行了参赛方法的总结及分享。


随着数字化经济的进一步发展,越来越多的企业开始将现代信息网络作为数据资源的主要载体,并通过网络通信技术进行数据传输。另一方面,协同办公套件的完善也促使越来越多行业将互联网作为主要的信息交流和分享的方式。以往的研究表明,会议记录的口语语言处理(Spoken Language Processing, 简称 SLP) 如关键词提取和摘要生成,对于会议的理解和生成 (Meeting Understanding and Generation,MUG) 包括信息的提取、组织排序及加工至关重要,可以显著提高用户获取重要信息的效率。
然而由于会议数据的高度保密性,会议的理解和生成技术的发展一直受到大规模公开数据集缺失的制约。为了促进会议理解和生成技术的研究和发展,阿里巴巴达摩院语音实验室构建并发布了目前为止规模最大的中文会议数据集 Alimeeting4MUG Corpus(AMC),并基于会议人工转写结果进行了多项SLP任务的人工标注。AMC 也是目前为止支持最多 SLP任务开发的会议数据集。基于AMC 举办的 ICASSP2023 MUG 挑战目标是推动SLP在会议文本处理场景的研究并应对其中的多项核心挑战,包括人人交互场景下多样化的口语现象、会议场景下的长篇章文档建模等。
▏AMC数据集开源
AMC(Alimeeting4MUG Corpus)数据集当前已经开源至ModelScope社区。
数据链接:
https://modelscope.cn/datasets/modelscope/Alimeeting4MUG/summary
该数据集总共包括654个会议,其中524个会议包括全部5个SLP任务的人工标注,即话题分割-TS,话题抽取式摘要和篇章抽取式摘要-ES,话题标题生成-TTG,关键词抽取-KPE,行动项抽取-AID;另外130个会议仅有话题分割任务标注。 每个会议中包括2到4个参会人,针对多个明确话题参与讨论,会议时长在15到30分钟,话题涵盖了商务、工业生产、组织管理、医疗、教育和其他日常会议。参考Alimeeting数据集的方案,我们对会议音频进行了人工转写以及对标点及说话人进行了人工标注,接着使用分段模型进行自动分段并在此基础上进行了五个SLP任务的人工标注(TS, ES, TTG, KPE, AID)。
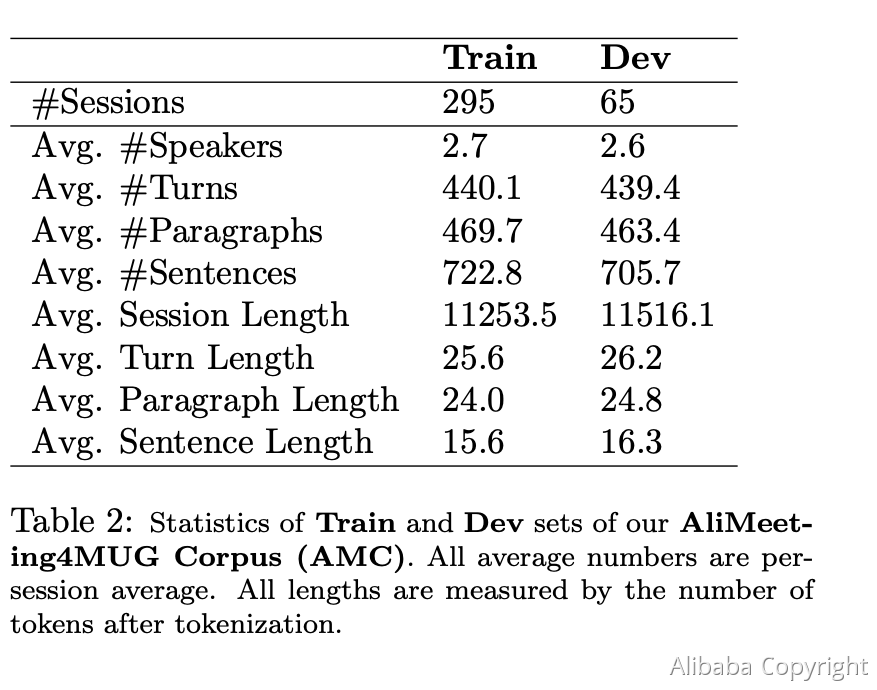
MUG挑战总共包含五个赛道:Track1-话题分割,Track2-话题及篇章抽取式摘要,Track3-话题标题生成,Track4-关键词抽取,Track5-行动项抽取。对于赛道二到赛道五,我们随机将包含SLP任务标注的524场会议切分为训练集 (Train)-295场,验证集 (Dev) -65场,挑战一阶段测试集(测试集1)-82场,挑战二阶段测试集(测试集2)-82场。对于赛道一话题分割,我们随机将仅包含话题分割标注的130个会议切分为挑战一阶段测试集(测试集1)-65场,挑战二阶段测试集(测试集2)-65场,赛道一同时复用其他赛道的训练集295场会议和验证集65场会议。训练集和验证集的统计分析如下表所示,统计清晰地展示了会议数据展现的长篇章文档以及说话人间频繁交互的特性。
▏五大赛道结果分析
针对MUG的5个赛道,每个赛道的参赛者可以使用主办方提供的Alimeeting4MUG Corpus以及挑战允许的额外公开数据进行模型训练及验证。比赛总共分为两阶段:第一阶段榜单使用测试集1进行评估并动态更新榜单,第二阶段使用测试集2进行评估并允许提交有限次结果。最终挑战排名以各提交队伍二阶段的最好分数为标准。同时主办方基于ModelScope社区为各位参赛者提供了简单易用的基线系统,包括预训练模型,微调代码以及评估脚本。针对会议口语现象和长篇章建模的挑战,5个赛道的基线系统分别使用了达摩院自研的高效长序列模型 PoNet (ICLR 2022),高鲁棒性文本预训练模型 StructBERT (ICLR 2020) 和文本生成模型PALM ( EMNLP 2020)。
基线系统具体见Github 链接:https://github.com/alibaba-damo-academy/SpokenNLP
具体各个赛道的介绍以及结果分析如下:
Track1:话题分割
话题分割任务需要将会议记录分割成一系列不重叠的、主题一致的片段。我们使用三个文本分割任务常见的评估指标 positiveF1、Pk和WD进行综合打分,最终排行榜分数计算公式为 0.5*positiveF1 + 0.25*(1-Pk) + 0.25*(1-WD)。赛道1 话题分割总共有9支队伍提交了结果。该赛道 Top6 队伍的结果汇总如下表所示。

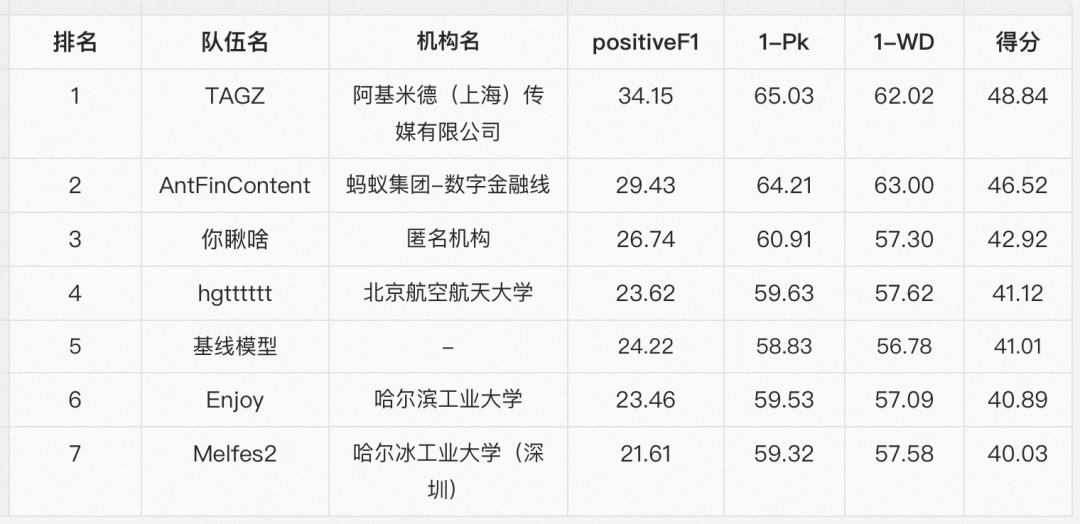
可以看到,Top3 队伍汇报的 positiveF1 指标在 30 左右,而书面语文本话题分割benchmark的 state-of-the-art positiveF1 可以达到80+, 说明会议场景下的话题分割任务仍然充满挑战。
算法方面,针对话题分割任务的输入长度较长、口语化表达存在句间信息冗余和语法错误等问题,Top2 队伍基本都使用了数据增强策略、PoNet长序列模型结构优化和训练优化等方法。
排名第一的 TAGZ 队伍充分利用官方允许使用的额外语料,合成了 130k 篇与训练集文本分布基本一致的增强数据;模型方面聚合句子内的词序列信息得到较鲁棒的句子表征,并增加句子级别的 Transformer 模块用于全局信息的建模。
排名第二的 AntFinContent 队伍则是聚合段落内的句子特征,在更高层级上进行建模,并且添加 Maximum Mean Discrepancy Loss 用于实现原始训练集和增强数据集在特征空间的分布一致性。除此之外,多数参赛队伍在训练方面都加入了 Focal Loss 缓解类别不均衡问题,加入 FGM 对抗训练进一步提升模型的泛化能力。
Track2:抽取式摘要
抽取式摘要赛道分为两个子任务,分别是话题摘要和篇章摘要。话题摘要和篇章摘要分别需要为每个人工标注的话题片段和整个会议提取关键句。
本任务使用标准的 ROUGE-1/ROUGE-2/ROUGE-L F-score (简称 R-1,R-2,R-L) 作为话题和篇章抽取式摘要的评估指标。本任务的数据标注采用多人标注的形式,因此对于每个话题和篇章分别有三个不同的抽取式摘要标注结果。在排行榜分数计算时,本任务评测系统计算基于三个标注结果的平均和最佳 R-1,2,L 分数,总共有 12 个分数(6个话题摘要分数+6个篇章摘要分数),这 12 个分数的均值作为Track2的排行榜分数。该赛道的排名前三的队伍及结果如下表所示。

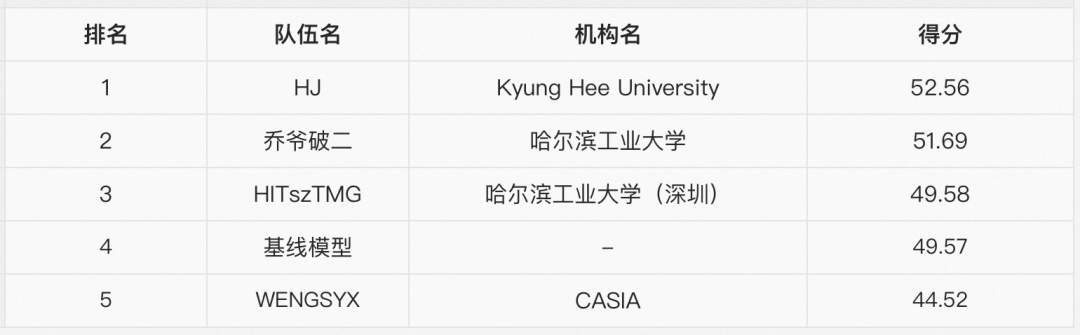
排名第一的队伍是来自韩国庆熙大学的HJ队伍,该队伍的提交系统将Track2任务建模为多任务的话题和篇章级别的句序列标注任务,并通过使用掩码预测和片段预测的自监督预训练技术提高预训练语言模型DeBERTa在下游任务上的性能,同时还通过随机加权平均的方式进一步提升模型的泛化性。
本赛道排名第二的乔爷破二队伍引入PoNet + TransformerEncoder的混合结构,有效提升了长文本处理的效率和效果。该队首先对AMC数据集进行预处理,过滤口语篇章中部分“短小”且“意义不大”的句子;该队伍还探索利用topic 级别的LCSTS 摘要数据集和session 级别的CLES 摘要数据集先进行第一阶段的微调训练,最后在下游目标任务的AMC数据上进行微调。
Track3:话题标题生成
话题标题生成任务需要为会议转写结果中人工标注的每个话题片段生成对应的标题。我们使用生成式任务最为常用的ROUGE-1/ROUGE-2/ROUGE-L F-score 作为任务评估指标,考虑到存在多人标注,最终得分为基于三个标注结果的平均和最佳 R-1,2,L 分数(总共6个分数)的平均数。
该任务总共9支队伍提交结果,该赛道的排名前五的队伍及结果如下表所示。

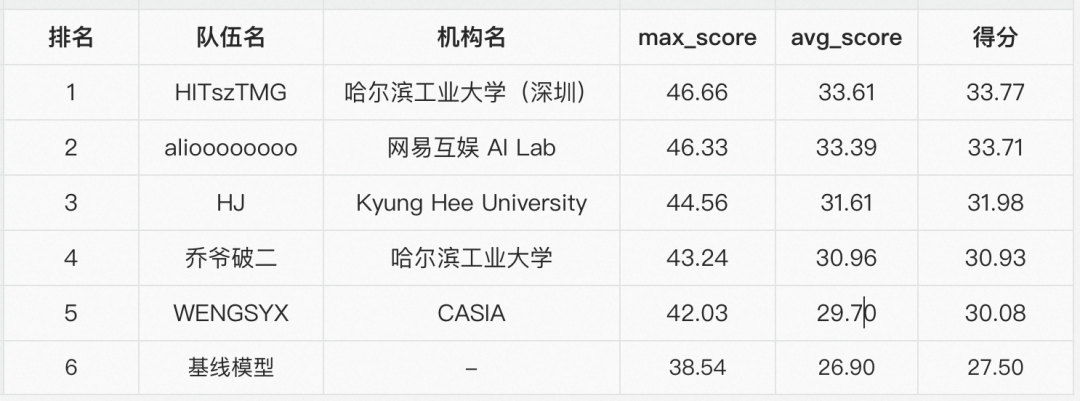
赛道3由于任务定义为生成式,参赛队伍均使用了基于预训练语言模型的encoder-decoder架构进行基础建模。
针对会议人工转写文本中的口语现象,第二名队伍使用了一个独立的前处理模块来过滤掉口语重复词汇以及独立短句。为了充分利用挑战允许使用的公开摘要数据,第一名队伍设计了“书面语预训练->微调/蒸馏”的训练范式。
具体为第一步先使用大规模书面语摘要数据进行中文预训练模型CPT大模型的预训练,第二步对CPT大模型进行领域内数据微调,最后使用teacher-student方式进行模型蒸馏产出符合比赛对于模型参数量要求的base模型;同时该队伍也探索了多种利用多人标注的方式,包括直接复制多份、启发式方法选取最优标注,并在调优不同训练阶段中使用不同训练数据的构造方式取得了最优结果。
Track4:关键词抽取
关键词提取要求模型从文档中提取出反映其主要内容的若干个关键短语。我们使用 exact_F1@K 和 partial_F1@K 作为评估指标,其中 @K 是指计算模型预测的前 K 个关键词和人工标注关键词的指标(K 取 10、15和20),exact_F1 是指预测关键词和人工标注关键词完全匹配时计算的 F1 值,partial_F1 是指预测关键词和人工标注关键词部分匹配时计算的 F1 值(本挑战中当两个关键词的最长公共序列长度为2个字符时便视为部分匹配),计算所有指标 (共6个分数)的平均值得到最终的排行榜分数。赛道4关键词提取总共有 7 支队伍提交了结果,Top3 团队的结果以及方法汇总如下表所示。

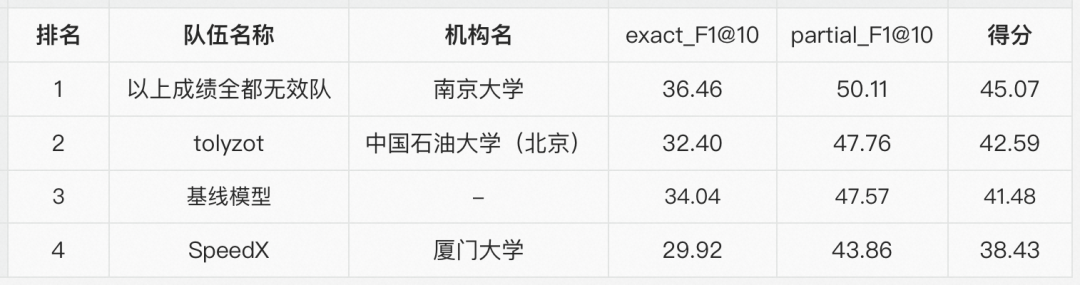
其中,排名第一的队伍采用基于ERNIE3.0的 W2NER 关系分类方法作为主要框架,使用 Focal Loss 和 Regression Loss,其中 Focal loss 用于缓解分类的类别不均衡问题,Regression Loss 用于得到每个关键词的分数作为排序的依据;此外模型层面通过组合多个句子为一个片段来提高模型单次输入的信息量。排名第二的队伍设计了一个重排序模块,得到模型预测的关键词得分后再根据关键词出现频次进行重新打分,进一步提升模型效果。
Track5:行动项抽取
行动项抽取需要检测会议篇章中包含可操作任务信息的句子作为正样本。本赛道的每个句子标注均来自三位不同的标注员。如果来自三个标注员的标签不一致,那么将由最终的专家决定该句标签。对于本赛道,我们使用positiveF1作为最终的分数排名。本赛道Top3 团队的结果如下表所示。


本赛道排名第一的队伍仔细分析了行动项的一些特点,主要有: a. 被标注为行动项的句子必须是被其他参会人认同的,虽然有时这个认同是隐含的。b. 行动项需要包含完整可执行的动作,所以通常行动项句子需要是一句完整的话。c. 行动项需要是一个决定,通常不应该是建议或者猜想等不确定语气;如果是建议或猜想,那么需要在后面的对话中被肯定。
通过以上的分析,该队伍提交的系统充分利用AMC数据中人工标注的说话人信息以及候选句的上下文信息进行相关的数据增强和模型建模。对于每个会议的每个对话句,他们的方法将该句与该句的下一句话及其对应的说话人为同一说话人或者不同说话人的信息拼接起来进行模型建模。同时在模型训练时还结合了对抗方法,有效提高了会议行动项识别的性能和系统整体的鲁棒性。
排名第二的队伍在调研后认为,SGD优化器在精度上,可以取得较其他优化器更优的结果,但相对于其他优化器其收敛速度并不具备优势。为此,他们的解决方案采用了二阶段训练方法TST(two-stage-training)来提升性能并兼顾收敛速度。在第一阶段的训练中,他们使用了Adamw的优化器进行训练,将模型训练到一个“局部较优”的性能。在第二阶段的训练中,他们加载了第一阶段训练使用的最优模型,在此基础上,将优化器更改为SGD进行二阶段训练。这个方法得到该队伍比赛提交中的最优结果。
▏总结展望
MUG赛事两阶段榜单都已经公布,具体可见各赛道详情页的排行榜:https://modelscope.cn/competition主办方介绍MUG benchmark 的论文 “MUG: A General Meeting Understanding and Generation Benchmark”, MUG挑战的总结论文,以及5个赛道Top1队伍介绍各自系统的5篇论文均已被 ICASSP2023 接收。
在3月6日完赛沙龙的技术分享中,5个赛道的Top1队伍对于会议理解和生成的两大核心挑战口语现象以及长篇章建模都给出了有启发的思考和解决方案。同时,5个Top1队伍对于会议理解和生成挑战的未来方向也给出了很有价值的建议和期望,包括从目前的会议人工转写扩展到在会议ASR转写结果上进行理解和生成,加入会议音频和其他模态信息的多模态理解和生成的建模,进一步扩大会议数据集的规模和多样化,进一步扩大理解和生成任务的类型,支持探索大/超大规模预训练模型和广泛的公开数据对于MUG任务的作用,增加真实性评估指标以及主观评估指标等等。人人交互场景下的理解与生成技术的研发依然面临重大挑战,期望和各位同仁一道继续探索并解决这个难题。
▏联系我们
欢迎对语音开源和语音应用感兴趣的研究人员和开发人员加入魔搭语音服务社区,共同探讨精进!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。