
计算机视觉领域顶级会议Computer Vision and Pattern Recognition Conference(CVPR 2023)将于6月18日至22日在加拿大温哥华召开,来自快手音视频技术团队题为《Quality-aware Pre-trained Models for Blind Image Quality Assessment》——适用于无参考图像/视频质量评估的质量感知预训练模型的最新研究成果被会议成功收录。

CVPR是计算机视觉领域的顶级国际会议,也是中国计算机协会CCF推荐的A类学术会议。其收录的论文代表了计算机视觉和模式识别领域的创新技术与重大成果,是该领域学术研究与行业发展的风向标。CVPR 2023共收到9,155篇投稿,其中有2,360篇论文被接收,接收率为25.78%。
| 论文链接:https://arxiv.org/abs/2303.00521 |
01 背景
在快手App,每天都有海量视频内容被生产出来。为提升用户体验质量(Quality-of-Experience, QoE),视频质量作为一个必要的指标,能够快速精准地过滤筛选出高质量的视频,从而大幅提升平台内容画质。
因此,业内一直在探索建立自动的图像/视频质量评估算法 [1,2,3,4],取得与人眼一致的感知质量。虽然,VMAF和SSIM等有参考评估算法已经在业界得到了广泛应用,但由于实际业务的海量UGC视频不存在“画质无损”或“近乎无损”的源视频作参考,无参考图像/视频质量评估方法更具实用价值。
近些年,基于深度学习的无参考图像/视频质量评估有效地提升了算法的表现。但由于标注数据的获取成本较高,依赖于大批的标注人员以及保序性校验获取无偏的标签,对应的数据量相对较少。作为参考,业界最大的BIQA数据集仅包含了40,000张真实场景的损伤图像,而图像识别领域的入门级数据集CIFAR100包含了60,000张图像,更大的ImageNet包含百万量级的标注数据。现有的BIQA数据集极大地限制了数据驱动的深度学习算法取得更好的表现。因此,如何弥补标注数据缺失,同时提升图像/视频质量评估算法在各种场景中的泛化能力,是这一领域亟需解决的痛点和难点。
02 方法
在这篇论文中,快手音视频技术团队提出了一种基于自监督(Self-Supervised Learning, SSL)的方法用于区分样本间不同的画质质量,并生成质量感知的预训练模型(Quality-aware Pre-trained models, QPT)供下游不同场景的图像/视频质量评估任务使用。
具体地,我们设计了一种质量感知的代理任务:将来自同一张损伤图像的样本定义为正样本,即具有相同的画质;将来自于不同图像,和同一张图像但具有不同的画质损伤的样本定义为负样本,即具有不同的画质。为了模拟真实场景中可能遇到的低质类型和复杂的视频消费链路,我们设计了一个包含 2 x 107 种退化方式的退化空间(Degradation Space)。通过在包含百万量级数据的ImageNet上采用对比学习进行自监督训练,预训练模型能够学习到质量相关的先验信息,提升下游质量评估任务的表现。以下是具体的算法细节,包括退化空间和代理任务的设计。
完备的退化空间
为了在自监督训练过程中获得画质相关的信息,我们使用可控的退化算子生成样本对,以此获得相对质量关系。在设计具体的退化类型之前,有几个观察应该被注意到:
- 影响一幅图片的感知质量的因素较多,包括内容、失真和压缩等。比如,一张包含无意义内容的图片应该被归类到低质。同时,在拍摄过程中引入的失真和编码过程中引入的压缩伪影也会降低图片本身的质量。
- 上述的影响因素在实际场景中往往是以组合的方式同时出现。一张图片可能会经历复杂的处理过程,包括拍摄、编辑、压缩和传输,引入复杂的失真类型。这些场景增加了质量评估任务的难度,一个好的预训练模型应该能够感知尽可能多、尽可能真实的失真场景。
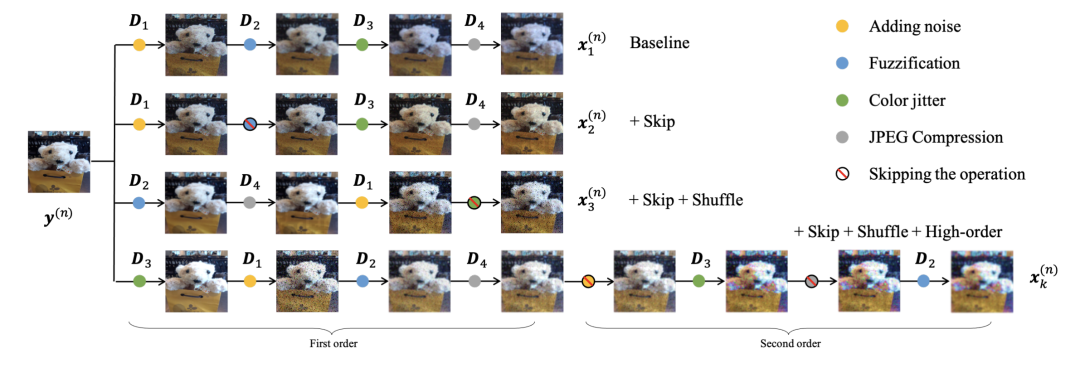
图1 使用不同退化算子和组合形式模拟构造失真图像的过程
基于上述观察,我们从退化算子的类型和组合方式两个角度来设计退化空间。如图1所示,针对上述第一点,我们引入丰富的退化算子类型来模拟真实失真,可以大致分为三种类型:
- 几何变换:模拟编辑和屏幕分辨率适应过程中引入的失真,包含四种类型的算子(尺寸变换、水平翻转、下采样和上采样);
- 色彩变换:模拟拍摄或者编解码过程中引入的亮度、色度和色调变换,包含两种类型的算子(颜色空间变换、灰度化);
- 纹理变化:模拟环境干扰和传输过程中的失真,包含三种类型的算子(添加噪声、模糊化、JPEG压缩)。处理过程可以表示为:
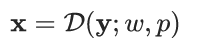
针对上述第二点,我们使用包含“随机选择”的退化算子的高阶(high-order)序列来模拟更为复杂的场景,比如一组退化算子组合{“尺寸变换”,“色彩空间变换”,“添加噪声”},每一个算子有一定概率被“跳过执行”,整体顺序也可以被“打乱”,处理过程可以被表示为:
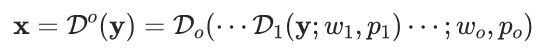
理论上,这个退化空间所包含的离散的组合方式数量约为 2 x 107 。
质量感知的代理任务
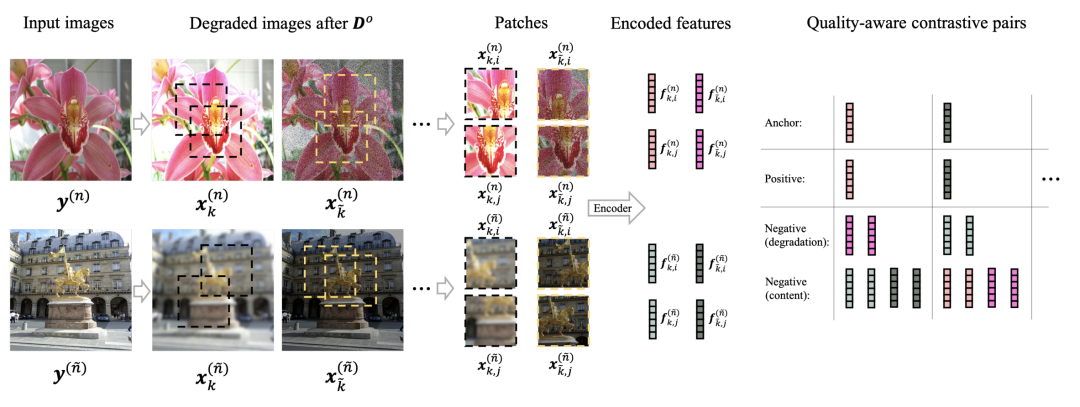
图2 质量感知的预训练代理任务(QPT)流程图
不同于自监督任务中(例如MoCo,SimCLR)经常采用的语意相关的(semantic-aware)代理任务,将每一张图片看作独立的类别,我们提出了一种质量感知的(quality-aware)代理任务,能够区分具有不同画质感知质量的样本。首先,图像经过不同的退化算子进行处理,得到具有不同失真形式的图片。然后,我们从失真图片中裁切出不同区域的图像块构成样本对。其中,来自同一种退化方式并且从同一张图像中裁剪出的不同区域的图像块构成正样本。其余为负样本,包含两种类型:
- 退化相关的负样本对(degradation-based negative pairs),这些样本对所包含的内容是一致的,但是经过了不同的退化组合,具有不同的画质;
- 内容相关的负样本对(content-based negative pairs),不管图像块所经历的退化方式是否相同,由于内容不同均被认定为负样本。值得注意的是,会存在少量内容不同但质量相同的图像块,但是这些样本对的比例相较于整体较少可以被忽略。最后,这些样本对应提取出的特征会使用质量感知对比损失函数进行约束(Quality-aware Contrastive Loss, QC-Loss),区分出正负样本的类型:
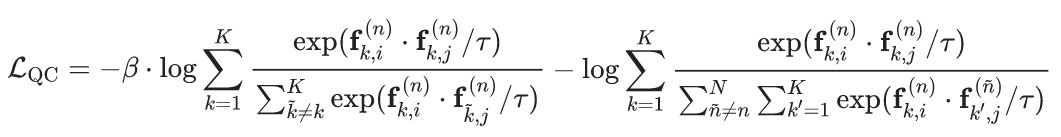
为了构造包含更多内容和纹理信息的样本对,提升下游不同场景BIQA任务的泛化能力,我们使用被广泛采用的ImageNet数据集作为基准数据进行预训练。ImageNet包含超过一百万张自然图像,对应1,000个类别,根据退化空间和代理任务的设计,理论上在预训练阶段可以产生 2 x 1014 个可能的样本对,提升了预训练阶段覆盖场景的范围。
03 实验结果
整体的训练过程分为两个阶段:
- 预训练(pre-training),使用QPT的方式进行训练模型的训练。
- 微调(fine-tuning),在预训练模型后面接入回归头进行网络参数的微调。
我们使用SRCC和PLCC作为指标进行对比。更高的SRCC表示样本间更好的保序性,更高的PLCC表示与标注分数更好地拟合程度。所有实验经过10次重复运行,中位数作为最终的比较分数。我们在常用的五个BIQA数据集上进行了算法的验证,所有数据集所使用的预训练参数为一致的。
如表1所示,QPT将现有SOTA方法的结果往前推进了一大步,超越了基于传统特征设计、精心设计的网络结构(CNN、Transformer)的方法。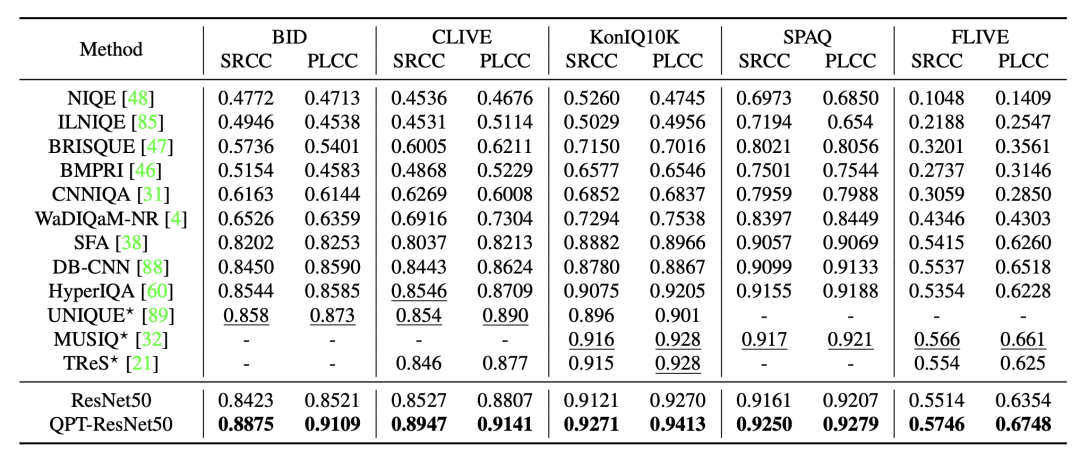
表1 QPT与当前SOTA的BIQA方法的对比
由于QPT方法的灵活性,它可以很好地与现有方法进行结合。如表2所示,通过将现有SOTA方法进行预训练参数的直接替换,我们进一步提升了HyperIQA和TRes的预测准确性,展现了所提出方法良好的泛化能力。

表2 通过替换预训练参数,
QPT能够对现有SOTA方法带来持续提升
QPT具有很强的可扩展性,数据和模型的持续扩充能够带来进一步的预测性能提升。如表3、表4所示,随着预训练使用的数据量持续提升(20%到100%),下游任务上BIQA的表现也是持续提升,未来可以考虑在更大尺度和规模的数据上进行预训练任务。同时,随着预训练编码模型容量的持续增加(4.9M到18.45M,11.69M到25.56M),下游任务上的表现也持续提升,未来可以在更大规模的模型上进行预训练,持续提升图像/视频质量评估的效果。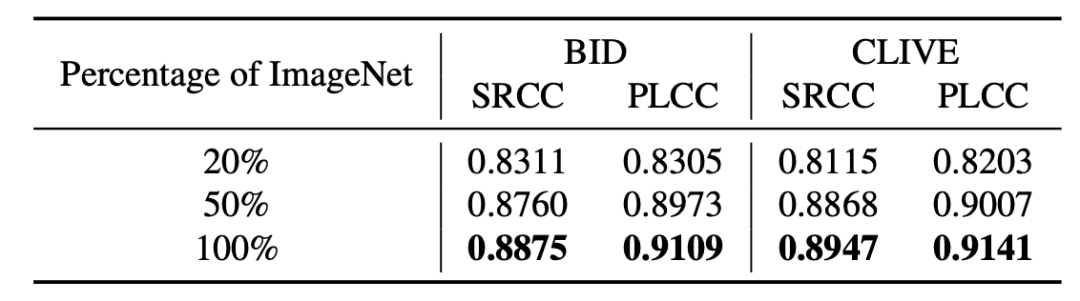
表3 随着预训练数据量的增加,
QPT在下游BIQA任务上的表现持续提升
表4 随着预训练编码模型容量的增加,
QPT在下游BIQA任务上的表现持续提升
04 总结
在本篇论文中,我们提出了一种质量感知的预训练方法。通过设计贴合快手真实使用场景的退化空间和质量感知的代理任务,QPT充分利用了无标签数据的内容丰富性,在预训练阶段提取到更为丰富的内容相关、纹理相关、失真相关的质量信息,在下游BIQA任务上获得显著提升,持续为快手视频质量评估(Kuaishou Visual Quality, KVQ)提供支持。
目前,KVQ已广泛应用于内部多个业务场景中,如全链路质量监控、基于内容的自适应处理和编码、搜索推荐等。同时,在快手技术toB品牌StreamLake业务中,KVQ也已商业化,并为业内数家知名公司提供了服务。未来,快手音视频技术团队将持续推动视频质量评估算法的提升,探索更为广泛的应用场景。
参考资料
[1] Toward a practical perceptual video quality metric (VMAF), Tech Blog 2016.
[2] Image quality assessment: from error visibility to structural similarity, TIP, 2004.
[3] Blindly assess image quality in the wild guided by a self-adaptive hyper network, CVPR 2020.
[4] MUSIQ: multi-scale image quality transformer, ICCV 2021.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
