
自动语音识别(Automatic Speech Recognition,ASR)技术目前已大规模落地于B站相关业务场景,例如音视频内容安全审核,AI字幕(C端,必剪,S12直播等),视频理解(全文检索)等。
作者:邓威——资深算法工程师,哔哩哔哩语音识别方向负责人
来源: 哔哩哔哩技术
另外,B站ASR引擎在工业界benchmark SpeechIO (https://github.com/SpeechColab/Leaderboard)2022年11月最近一期全量测评中也取得了第一名的成绩,且在非公开测试集中优势更加明显。
| 全部测试集排名 | 厂家 | 字错误率 |
| 1 | B站 | 2.82% |
| 2 | 阿里云 | 2.85% |
| 3 | 依图 | 3.16% |
| 4 | 微软 | 3.28% |
| 5 | 腾讯 | 3.85% |
| 6 | 讯飞 | 4.05% |
| 7 | 思必驰 | 5.19% |
| 8 | 百度 | 8.14% |
- AI字幕(中英文C端,必剪,S12直播等)
- 全文检索
本文将介绍在这一过程中,我们在数据和算法上所做的积累与探索。
高质量ASR引擎
一个适合工业化生产的高质量(高性价比)ASR引擎,它应该具有如下的特点:
| 说明 | |
| 高精度 | 在相关的业务场景精度高,鲁棒性好 |
| 高性能 | 工业化部署延迟低,速度快,计算资源占用少 |
| 高扩展性 | 能高效支持业务迭代定制,满足业务快速更新需求 |
下面结合B站的业务场景在以上几个方面介绍我们相关的探索与实践。
数据冷启动
语音识别任务即从一段语音中完整识别出其中的文字内容(语音转文字)。
满足现代工业生产的ASR系统依赖大量且多样的训练数据,这里“多样”是指说话周围环境,场景语境(领域)及说话人口音等非同质数据。
针对于B站的业务场景,我们首先需要解决语音训练数据冷启动的问题,我们将碰到如下挑战:
- 冷启动:开始只有极少量的开源数据,购买的数据和业务场景匹配度很低。
- 业务场景领域广:B站音视频业务场景覆盖几十个领域,可以认为是泛领域,对数据“多样性”要求很高。
- 中英文混合:B站年轻用户较多,且存在较多中英文混合泛知识类视频。
对于以上问题,我们采用了以下的数据解决方案:
业务数据筛选
B站存在少量UP主或用户投稿的字幕(cc字幕),但同时也存在一些问题:
- 时间戳不准,句子开始和结束时间戳往往在首尾字中间或者数个字之后;
- 语音和文字没有完全对应,多字,少字,注释或翻译,存在按意思理解生成字幕的情况;
- 数字转换,比如字幕2002年(实际发音二千零二年,二零零二年等);
为此,我们基于开源数据,采购的成品数据及少量标注数据训练一个筛选数据的基础模型,以投稿字幕文本训练子语言模型,用来做句子时间对齐及字幕筛选过滤;
半监督训练
近年来因数据,GPU计算能力大幅提升及大规模人工标注数据成本过高,业界涌现了大量无监督(wav2vec,HuBERT,data2vec等)[1][2]及半监督训练方法。
B站存在大量的无标注业务数据,同时我们也从其它网站获取了大量无标注视频数据,我们前期采用被称为NST(Noisy Student Training)[3]的半监督训练方法,
初期按领域及播放量分布筛选了近50万稿件最终生成约4万小时自动标注数据,加上初始1.5万小时标注数据训练后识别精度有相对近15%左右的提升,且模型鲁棒性改善明显。
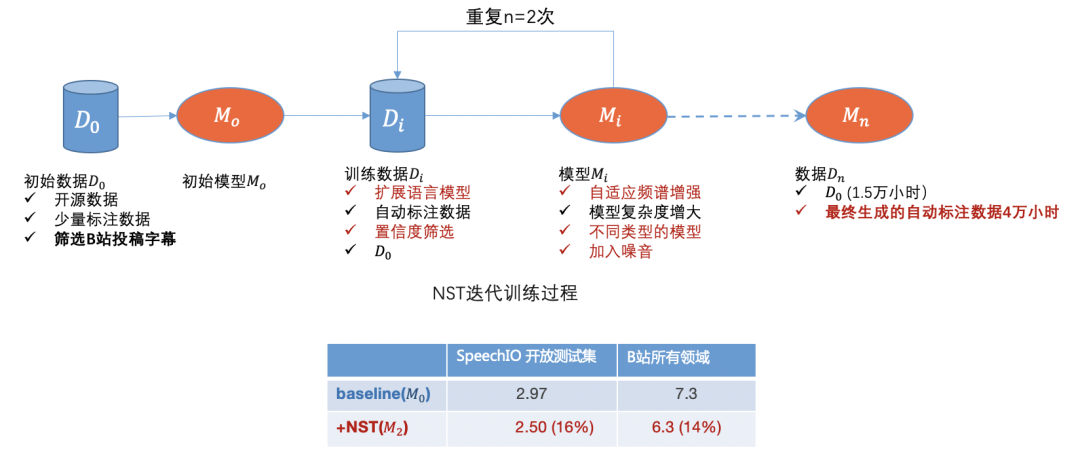
图一
通过开源数据,B站投稿数据,人工标注数据及自动标注数据我们初步解决数据冷启动问题,随着模型的迭代,我们可以进一步筛选出识别比较差的领域数据,
这样形成一个正向循环。初步解决数据问题后,下面我们重点介绍模型算法相关优化。
模型算法优化
ASR技术发展历程
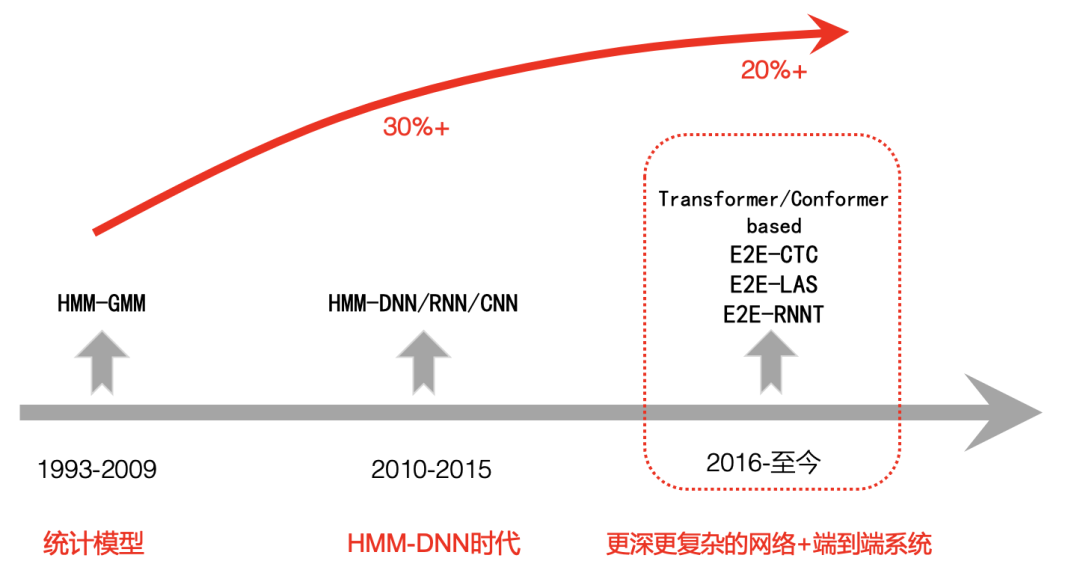
我们简单回顾下现代语音识别发展历程,大体可以分为三个阶段:
第一阶段是从1993年到2009年,语音识别一直处于HMM-GMM时代,由以前基于标准模板匹配开始转向统计模型,研究的重点也由小词汇量、孤立词转大词汇量、非特定人连续语音识别,自90年代以后在很长一段时间内语音识别的发展比较缓慢,识别错误率没有明显的下降。
第二阶段是2009年到2015年左右,随着GPU计算能力的大幅提升,2009年深度学习又开始在语音识别中兴起,语音识别框架开始转变为HMM-DNN,开始步入DNN时代,语音识别准确度得到了显著的提升。
第三阶段是2015年以后,由于端到端技术的兴起,CV,NLP等其它AI领域的发展相互促进,语音识别开始使用更深,更复杂的网络,同时采用端到端技术进一步大幅提升了语音识别的性能,在一些限制的条件下甚至超过了人类水平。
图二
B战ASR技术方案
重要概念介绍
为方便理解,下面简单介绍一些重要基础概念
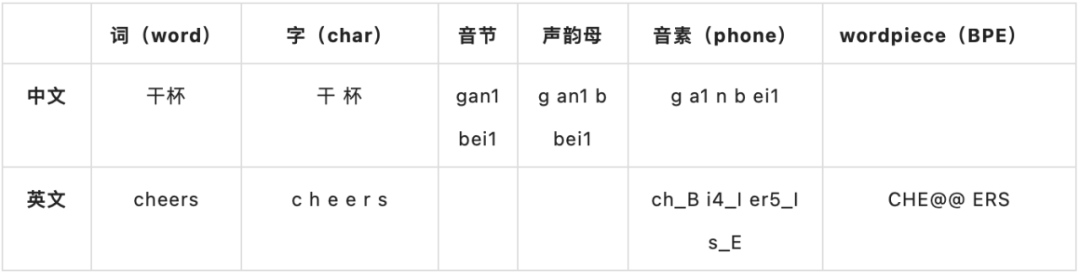
建模单元
Hybrid or E2E
第二阶段基于神经网络的混合框架HMM-DNN相比比第一阶段HMM-GMM系统语音识别准确率是有着巨大的提升,这点也得到了大家的共识。
但第三阶段端到端(end-to-end,E2E)系统对比第二阶段在开始的一段时间业界也有争议[4],随着AI技术的发展,特别是transformer相关模型的出现,模型的表征能力越来越强,
同时随着GPU计算能力的大幅提升,我们可以加入更多的数据训练, 端到端方案逐渐表现出它的优势,越来越多的公司选择端到端的方案。
这里我们结合B站业务场景对比这两种方案:
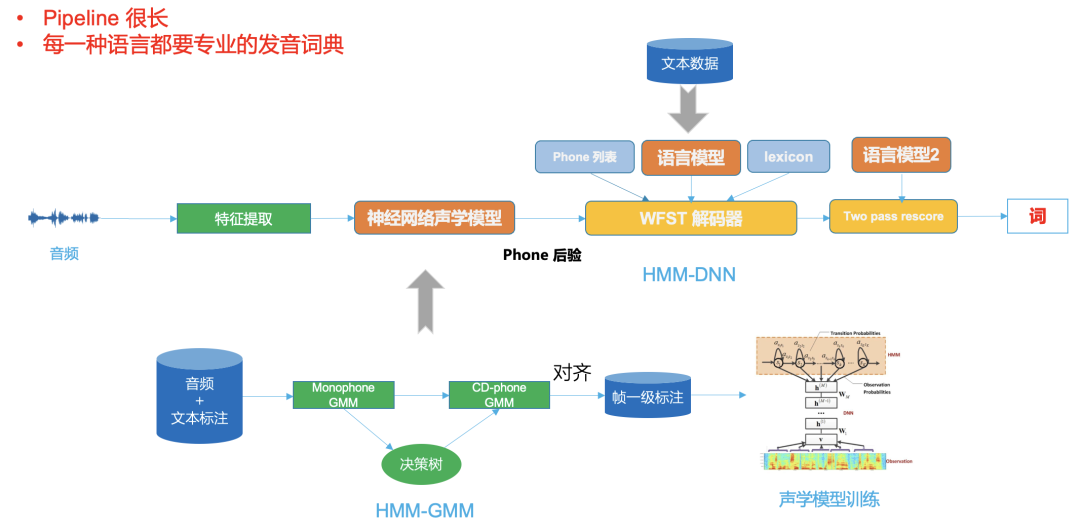
图三
图三是一个典型的DNN-HMM框架,可以看出它的pipeline 很长,不同的语言都需要专业的发音词典,
而图四端到端系统把所有这些放在一个神经网络模型中,神经网络输入是音频(或特征),输出即是我们想要的识别结果。
图四
随着技术的发展端到端系统在开发工具,社区及性能上优势也越来越明显:
- 代表性工具及社区比较
| 混合框架(hybrid) | 端到端框架(E2E) | |
| 代表性开源工具及社区 | HTK, Kaldi | Espnet, Wenet, DeepSpeech, K2等 |
| 编程语言 | C/C++, Shell | Python, Shell |
| 可扩展性 | 从头开发 | TensorFlow/Pytorch |
- 性能比较
下面表格是典型的数据集基于代表性工具下的最优结果(字错误率 CER):
| 混合框架(hybrid) | 端到端框架(E2E) | |
| 代表工具 | Kaldi | Espnet |
| 代表技术 | tdnn+chain+rnnlm rescoring | conformer-las/ctc/rnnt |
| Librispeech | 3.06 | 1.90 |
| GigaSpeech | 14.84 | 10.80 |
| Aishell-1 | 7.43 | 4.72 |
| WenetSpeech | 12.83 | 8.80 |
总之,选择端到端系统,相比传统的混合框架,在资源一定的情况下,我们可以更快更好的开发出一个高质量的ASR系统。
当然,基于混合框架,如果我们也采用同等先进的模型及高度优化的解码器也是可以达到和端到端接近的效果,但我们可能需要投入数倍的人力及资源来开发优化这个系统。
端到端方案选择
B站每天都有数十万小时的音频需要转写,对ASR系统吞吐和速度要求都很高,生成AI字幕对精度也有较高的要求,同时B站的场景覆盖也非常广泛,选择一个合理高效的ASR系统对我们来说很重要。
理想的ASR系统
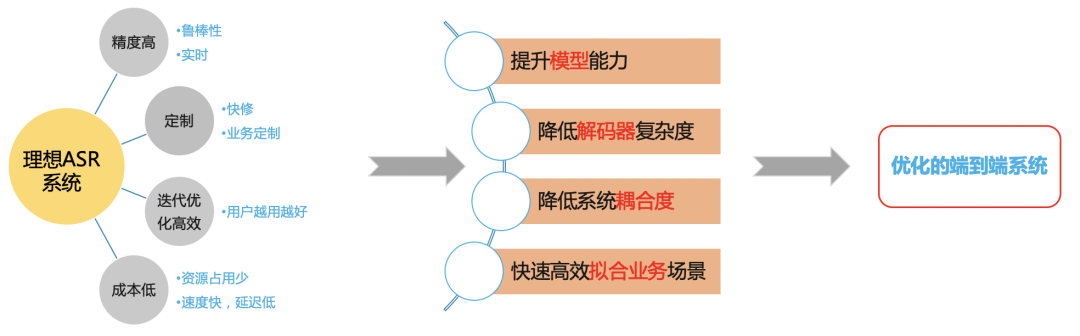
图五
我们希望基于端到端框架构建一个高效的ASR系统解决在B站场景的问题。
端到端系统比较
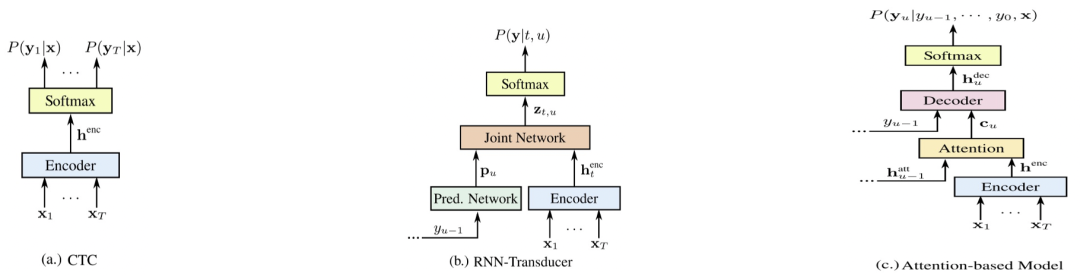
图六
图六是现在有代表性的三种端到端系统[5],分别是E2E-CTC,E2E-RNNT,E2E-AED,下面从各个方面对比各个系统优缺点(分数越高越好)
- 系统比较
| E2E-AED | E2E-RNNT | 优化的E2E-CTC | |
| 识别精度 | 6 | 5 | 6 |
| 实时(流式) | 3 | 5 | 5 |
| 成本及速度 | 4 | 3 | 5 |
| 快修 | 3 | 3 | 6 |
| 快速高效迭代 | 6 | 4 | 5 |
- 非流式精度比较(字错误率 CER)
| 2000小时 | 15000小时 | |
| Kaldi Chain model+LM | 13.7 | — |
| E2E-AED | 11.8 | 6.6 |
| E2E-RNNT | 12.4 | — |
| E2E-CTC(greedy) | 13.1 | 7.1 |
| 优化的E2E-CTC+LM | 10.2 | 5.8 |
上面是分别基于2000小时及15000小时视频训练数据在B站生活美食场景的结果,其中Chain及E2E-CTC采用了相同语料训练的扩展语言模型,
E2E-AED及E2E-RNNT没有采用扩展的语言模型,端到端系统都是基于Conformer模型。
从第二表格可以看出单一的E2E-CTC系统精度并不明显弱于其它端到端系统,但同时E2E-CTC 系统存在着以下优点:
- 因为没有神经网络的自回归(AED decoder 及RNNT predict)结构,E2E-CTC 系统在流式,解码速度,部署成本有着天然的优势;
- 在业务定制上,E2E-CTC 系统也更容易外接各种语言模型(nnlm及ngram),这样使得在没有足够数据充分覆盖的通用开放领域其泛化稳定性要明显优于其它端到端系统。
高质量ASR解决方案
高精度可扩展ASR框架
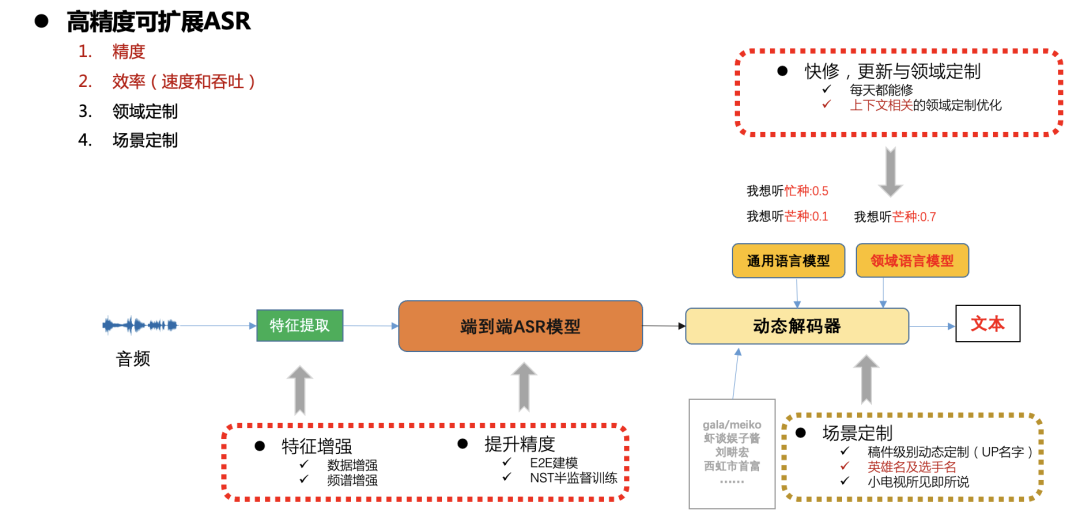
图七
在B站生产环境中对速度,精度以及资源消耗都有较高的要求,在不同的场景也有快速更新及定制的需求(比如稿件相关的实体词,热门游戏及体育赛事的定制等),
这里我们总体采用端到端CTC系统,通过动态解码器解决可扩展性定制问题,见图七。下面将重点分开阐述模型精度,速度及扩展性优化工作。
端到端CTC区分性训练
我们系统采用中文字加上英文BPE建模,基于AED及CTC多任务训练完以后,我们只保留CTC部分,后面我们会进行区分性训练,我们采用端到端的lattice free mmi[6][7]区分性训练:
- 区分性训练准则
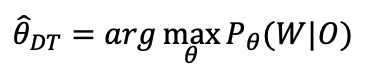
- 区分性准则-MMI

- 和传统区分性训练区别
1. 传统做法
a. 先在CPU上生成全部训练语料对应的alignment和解码lattice;
b. 训练的时候每个minibatch由预先生成的alignment和lattice 分别计算分子和分母梯度并更新模型; 2. 我们做法 a. 训练的时候每个minibatch直接在GPU上计算分子和分母梯度并更新模型;
- 和kaldi基于phone的lattice free mmi区分性训练区别
1. 直接端到端对字及英文BPE建模,抛弃phone hmm状态转移结构; 2. 建模粒度大,训练输入没有近似截断,context 为整个句子;下表是在15000小时数据上,CTC训练完成后,用解码置信度选取3000小时进行区分性训练的结果,可以看出采用端到端的lattice free mmi区分性训练结果要好于传统DT训练,除了精度上的提升,整个训练过程都能在tensorflow/pytorch GPU中完成。
| B站视频测试集 | |
| CTC baseline | 6.96 |
| 传统DT | 6.63 |
| E2E LFMMI DT | 6.13 |
相对混合系统,端到端系统解码结果时间戳都不是很准,AED 训练没有随时间单调的对其,CTC 训练的模型相比 AED 时间戳准确很多,但也存在尖峰问题,每个字的持续时长不准;
经过端到端区分性训练后,模型输出会变得更加平整,解码结果的时间戳边界更加准确;
端到端CTC解码器
在语音识别技术发展过程中,无论是基于GMM-HMM的第一阶段还是基于DNN-HMM混合框架的第二阶段,解码器都是其中非常重要的组成部分。
解码器的性能直接决定了最终ASR系统的速度及精度,业务的扩展及定制也大部分依赖灵活高效的解码器方案。传统解码器不管是动态解码器还是基于WFST的静态解码器都非常复杂,不仅依赖大量的理论知识,还需要专业的软件工程设计,开发一个性能优越的传统解码引擎不仅前期需要投入大量的人力开发,而且后期维护成本也很高。
典型的传统的 WFST 解码器,需要把hmm,triphone context,字典,语言模型编译成一个统一的网络,即HCLG,在一个统一的FST网络搜索空间,这样可以提升解码速度,提高精度。
随着端到端系统技术的成熟,端到端系统建模单元粒度较大,比如一般为中文的字或英文的wordpiece,因为去除了传统HMM转移结构,triphone context及发音字典,这使得后面的解码搜索空间变的小很多,这样我们选择基于beam search 为基础的简单高效动态解码器,下图八是两种解码框架,相比传统的WFST解码器,端到端动态解码器有以下优势:
- 占用资源少,典型的为WFST解码资源1/5;
- 其耦合度低,方便业务定制,方便和各种语言模型融合解码,每次修改不需要重新编译解码资源;
- 解码速度快,采用字同步解码[8],典型的比WFST解码速度快5倍;
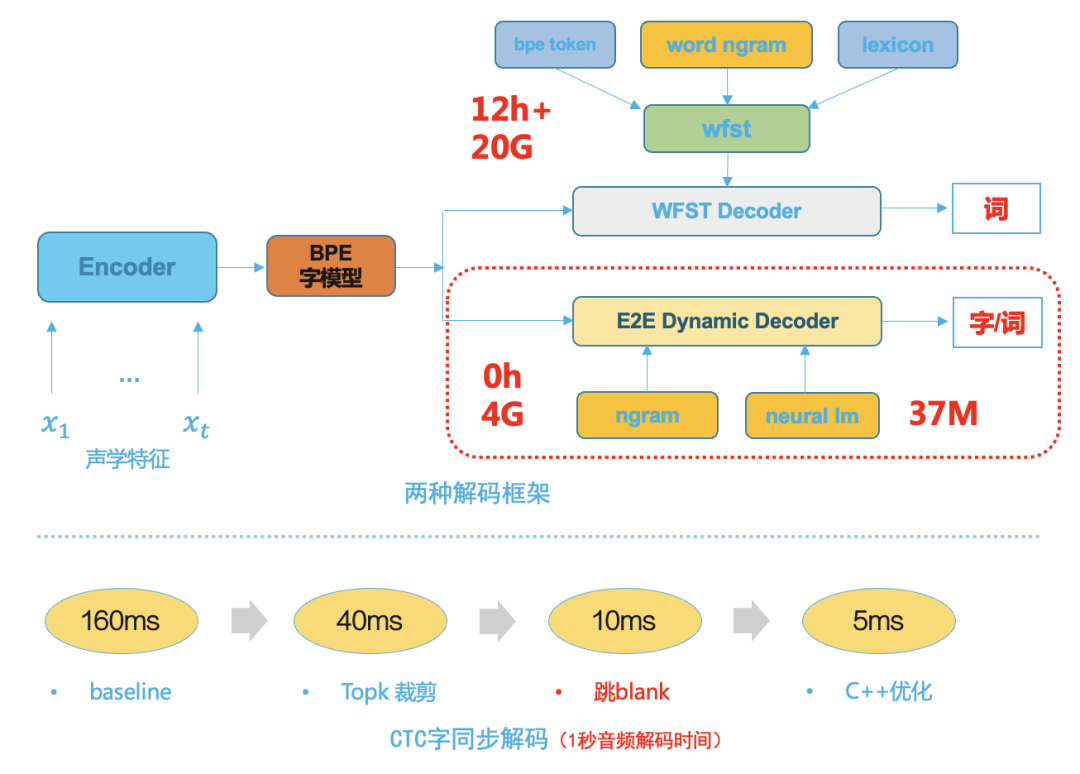
图八
模型推理部署
在一个合理高效的端到端ASR框架下,计算量最大的部分应该在神经网络模型的推理上,而这块计算密集的部分可以充分利用GPU的计算能力,我们分别从推理服务,模型结构及模型量化几部分优化模型推理部署:
- 模型采用F16半精度推理;
- 模型转FasterTransformer[9],基于nvidia高度优化的 transformer;
- 采用triton部署推理模型,自动组batch,充分提升GPU使用效率;
在单块GPU T4下速度提升30%,吞吐提升2倍,1小时能转写3000小时长音频;
总结
这篇文章主要介绍了语音识别技术在B站场景的落地,如何从头解决训练数据问题,整体技术方案的选择,各个子模块的介绍及优化,包括模型训练,解码器优化及服务推理部署等。未来我们将进一步提升相关落地场景用户体验,比如采用即时热词技术,优化稿件级别相关实体词准确率;结合流式ASR相关技术,更加高效的定制支持游戏,体育赛事的实时字幕转写。
参考资料
[1] A Baevski, H Zhou, et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
[2] A Baevski, W Hsu, et al. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
[3] Daniel S, Y Zhang, et al. Improved Noisy Student Training for Automatic Speech Recognition
[4] C Lüscher, E Beck, et al. RWTH ASR Systems for LibriSpeech: Hybrid vs Attention — w/o Data Augmentation
[5] R Prabhavalkar , K Rao, et al, A Comparison of Sequence-to-Sequence Models for Speech Recognition
[6] D Povey, V Peddinti1, et al, Purely sequence-trained neural networks for ASR based on lattice-free MMI
[7] H Xiang, Z Ou, CRF-BASED SINGLE-STAGE ACOUSTIC MODELING WITH CTC TOPOLOGY
[8] Z Chen, W Deng, et al, Phone Synchronous Decoding with CTC Lattice
[9] https://github.com/NVIDIA/FasterTransformer
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
