
一、三维声一场声音的革命
众所周知,电影诞生于18世纪90年代,但不同于今天的电影,电影刚诞生时是没有声音的,在很长一段时间,人们习惯于在寂静中欣赏电影里的画面。不过谁都知道,电影如果要作为一门艺术走上主流舞台,仅仅只有画面是不够的。伴随着这种期待,历史来到了20世纪,1927年的某一天,当观众像往常一样,准备在寂静中欣赏上映的电影《The Jazz Singer》时,他们突然听到主角开口说道:“等一下,等一下,你们听见我了吗?”就这样,电影的一个新的时代来临了!

可以说,电影技术的发展一直是两条腿在走路,迈动左脚是画面技术的进步,迈动右脚则是声音技术的更新。自1940 年世界首部立体声电影《幻想曲》,到1992年世界首部5.1 环绕立体声电影《蝙蝠侠归来》,再到2010 年世界首部7.1 环绕立体声电影《玩具总动员3》,短短几十年的时间里,从单声道到立体声,再过渡至被声音包围的环绕声,飞速发展的电影声音技术在朝着“将声音最接近现实的还原”这一终极目标不断冲刺着。而三维声就带着这样的历史使命在21世纪诞生了。
三维声所带来的革命不仅体现在影视行业,在虚拟现实行业,三维声同样扮演着至关重要的角色。完整的虚拟现实的体验,需要视觉、听觉、嗅觉、触觉信息的搭配,其中视觉和听觉信息尤为重要,三维声技术是VR技术标准里重要且不可或缺的一环。在其他领域,三维声同样有着非常广泛的作用,如设计者在飞机驾驶舱利用三维声技术来播放警报信息,帮助飞行员更有效的应对空中危机。
二、三维声渲染的理论基础
两只耳朵为什么能够听到三维的声音?要想知道答案,首先必须了解人耳定位的基本原理。空间某点声源发出的声音传递到人的两耳,会有时间差(ITD,interaural time difference)和强度差(ILD,interaural level difference),并且声音在传递过程中会与人的躯干、肩膀、头部以及耳廓发生一系列的相互作用,使声音的音质改变,人耳则根据到达两耳声音的时间、强度和音质的差别来确定声源的位置。在自然界中,由于声源分布在听众的四面八方,来自于不同方位的声音因为上文所提到的ITD和ILD在听众那里产生了方位感。

如何让录制的声音播放出来产生同样的方位感效果,则是三维声渲染需要解决的问题。通常声音播放有两种形式,一种是多音响阵列,另外一种是使用耳机播放。对于前者,通过使用多个扬声器,并将其在空间中按照预设的位置摆放来模拟三维声源播放方位,比较典型的例如日本NHK 电视台的22.2 多声道音频重放环境,Auro Technologies 使用9.1、10.1 来构建家庭影院的重放环境,使用11.1、13.1 构建电影院的重放环境。 如果使用耳机播放,上文提到的ITD和ILD信息可以用一个传递函数来表示,称为头相关传递函数(HRTF,head-related transfer function),耳机最后播放的声音可以表示为声源声音与HRTF函数的卷积输出,如下面公式所示,其中HL,HR分别为左右耳的HRTF参数,S表示声源声音。
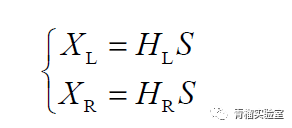
看到这里,很多人可能要问,是不是只要我们精确摆放了扬声器,或者精确测量了每个人的HRTF参数,我们就一定能播放出媲美真实的空间声音?答案是否定的,HRTF和扬声器阵列仅仅解决了让我们能够听到三维声的物理基础,但怎么“制(渲)造(染)”出三维声,“合适的混响”同样必不可少。
传递到人耳的声音由直达声、前期反射声和后期混响声组成。直达声可以为听音者提供声源的方向信息。前期反射声是声源发出的声音经周围界面单次或少数次反射后的声音,比直达声到达听音点晚约80 ms。由于人耳听觉的延迟效应,人耳不能将直达声和前期反射声区分开来。后期混响声是经过多次反射后到达人耳的声音。合适的混响声可以使声音浑厚饱满,但过强的混响声会破坏声音的清晰度。人耳对环境和声源位置的感知受到混响声的影响,理想的混响时间可以使人对声源定位的准确度达到最高。房间的早期反射声及后期混响声对声源的定位、环境的感知十分重要。
三、三维声渲染的技术细节
三维声从技术环节来说,可以分为三个环节,生产制作,传输,以及渲染:
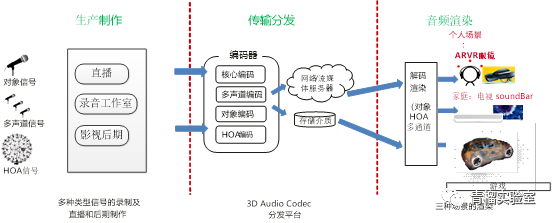
从图4可以看出,音频渲染的主要任务是将音频解码后的输出渲染至具体的音频回放设备中去,形象的说,三维声渲染主要是解决三维声“最后一公里”的任务。
下图展示了三维声渲染系统框架里的主要环节:
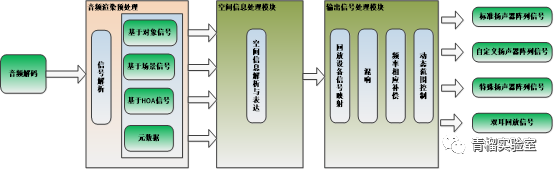
- 音频渲染预处理
对于当前主流支持三维声编解码技术的Codec,其支持的三维声信号可以分为三种类型:
- 基于场景的音频表示信号
- 基于声道的音频表示信号
- 基于对象的音频表示信号
除此之外还有解码后的元数据。音频渲染预处理模块的主要任务是识别解码输出后的信号属于上述哪一种信号,进而根据信号种类将解码后的格式数据统一成为系统约束的格式,为接下来的空间信息处理模块调用正确的空间信息解析器做准备。
- 空间信息处理模块
这一环节的主要任务是读取三种音频信号的空间信息和场景信息,并将其归一化转换成渲染器后续所需要的音频元素,运动元素,场景空间元素等。
- 输出信号处理模块
该模块的主要任务是将空间信息处理模块输出的中间信号根据用户应用场景的回放类型解码到播放设备上。对于扬声器阵列信号,渲染器将中间信号与回放扬声器矩阵相乘即可获取回放信号。对于耳机回放信号,先预设扬声器阵列,再根据扬声器的位置进行HRTF卷积来对扬声器进行虚拟化处理。
同时,考虑到不同回放方式的不一致性,不同回放设备有着不同的频响曲线和增益,为了呈现一致的声学体验,渲染系统通常会对输出信号后处理调整。后处理的操作包括但不限于针对具体设备的频率响应补偿(EQ,Equalization)以及动态范围控制(DRC,Dynamic range control)等。
四、三维声渲染的主要技术挑战及展望
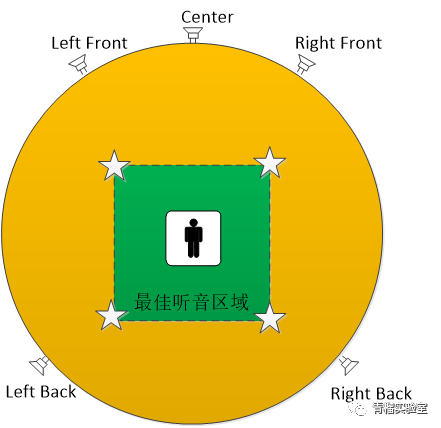
三维声渲染的主要挑战有几个方面,第一,从回放设备上来考虑,基于扬声器阵列实现的回放环境存在物理空间里不同位置听觉体验的显著差异,在一个由扬声器阵列构建的回放环境里,存在着一个sweet spot即最佳听音位置(图5中小人所在位置),超过下图绿色区域的位置将无法获得预期的空间音效。
基于耳机的回放环境,其回放效果依赖于HRTF的准确性,而每个人的HRTF参数又是不一样的,这意味着无法在耳机中通过使用通用HRTF来播放三维声。换句话说,如果要获得准确的三维声效果,必须准确测量每个人的HRTF参数。
三维声渲染面临的第二个挑战是三维声渲染过程中所消耗的资源,以HOA信号为例,如果想更精确的表达语音信号以及所携带的空间信息,需要增加球谐函数的阶数,与此同时,高阶球谐函数精确恢复声场时需要庞大的扬声器数目。假如在半径1m区域内恢复最高频率为20 kHz 的声场,需要对球谐函数进行不少于36 阶的截断,这需要大概1369个扬声器才能实现,即使不考虑扬声器的数目,如此庞大的计算量,在实际应用中也是不现实的。所以在实际应用中,需要在球谐函数的阶数,语音质量以及空间精准度之间做相应的妥协与平衡。
三维音频技术在虚拟现实、消费电子,网络直播等领域有着广泛的应用前景,因此成为近年来音频信号处理领域中颇为引人注目的研究课题之一。国内对三维音频技术的研究尽管起步较晚,但发展较快,2016 年2 月19 日,AVS(数字音视频编解码技术标准)技术应用联合推进工作组领导小组召开第七次会议,决定成立三维声(3D Audio)专题组,2021年3月,CUVA与AVS两大组织宣布联手进行三维声标准化研究。此外,当前国际上众多知名公司如Google, Apple, Sony等也纷纷推出自己的三维音频一体化解决方案。三维声正迎来音频技术领域发展的“风口”。
作者:韩建 来源:青榴实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
