
本文介绍图像分割的概念,图像分割的类型、架构、方法、数据集、工具和框架、应用场景、未来发展方向以及基于深度学习方面的图像分割技术。
1、什么是图像分割
图像分割是图像分析的第一步,是计算机视觉的基础,是图像理解的重要组成部分,同时也是图像处理中最困难的问题之一。所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分为若干个互不相交的区域,使得这些特征在同一个区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。简单的说就是在一幅图像中,把目标从背景中分离出来。图像分割是为图像中的每一个像素打上标签,其中具有相同标签的像素具有相同特征。
2、图像分割类型
图像分割是将像素分类的过程,分类的依据可建立在:像素间的相似性、非连续性。图像分割主要有两种类型:语义分割和实例分割。
在语义分割中,所有物体都是同一类型的,所有相同类型的物体都使用一个类标签进行标记,而在实例分割中,相似的物体可以有自己独立的标签。

3、图像分割架构
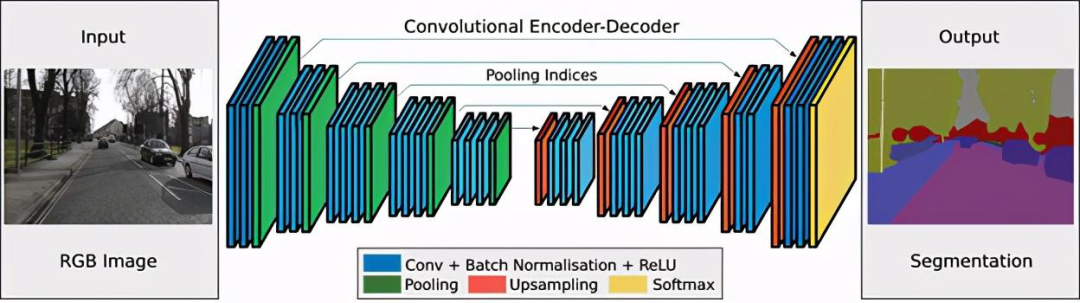
图像分割的基本结构由编码器和解码器组成。编码器通过过滤器从图像中提取特征。解码器负责生成最终输出,通常是包含对象轮廓的分割掩码(segmantation mask)。大多数架构都有这种体系结构或其变体。
4、图像分割方法
在图像分割领域中有多种技术:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。
1)阈值技术–该技术的主要目的在于确定图像的最佳阈值。强度值超过阈值的像素其强度将变为1,其余像素的强度值将变为零,最后形成一个二值图。用于选择阈值的方法有:Otsu,k均值聚类,和最大熵法。

2)运动与交互分割–该技术基于图像中的运动来进行分割。其思想很直观,在假设目标是运动的情况下找出两幅图中的差异,那么不同之处一定就是目标位置。
3)边界检测–包含多种数学方法,其目的在于标出数字图像中处于图像亮度变化剧烈,或者更正式的讲,具有不连贯性的区域中的点。由于区域边界和边具有很高关联性,因此边界检测通常是另一种分割技术的前提步骤。
4)区域增长方法–主要建立在同一区域中相邻像素具有相近像素值的假设之上。常见步骤为将像素与其近邻像素作比较,如果满足相似性标准,则该像素就可以被划分到以一个或更多其近邻点组成的聚类中去。相似性标准的选择很关键,并且在所有实例中其结果易受到噪声影响。
5、基于深度学习的图像分割
深度学习使得图像分割的准确率提高了很多,现代图像分割技术以深度学习技术为动力。下面是几种用于分割的深度学习架构:
1)U-Net
U-Net是一个最初用于开发生物影响分割的卷积神经网络。从视觉上看,它的架构看起来像字母U,因此而得名U-Net。它的架构由两部分组成,左边是收缩路径,右边是扩展路径。收缩路径的目的是捕获内容,而扩展路径的角色是帮助精确定位。
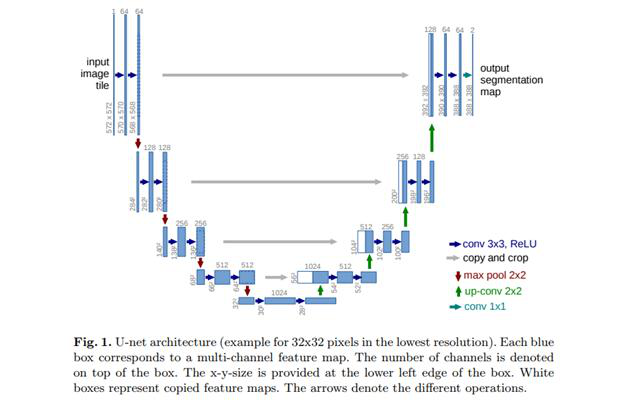
U-Net由右侧的扩展路径和左侧的收缩路径组成。收缩路径由两个3×3的卷积层组成。卷积之后是一个校正的线性单元和和一个2×2的max-pooling池化层的计算来做下采样。
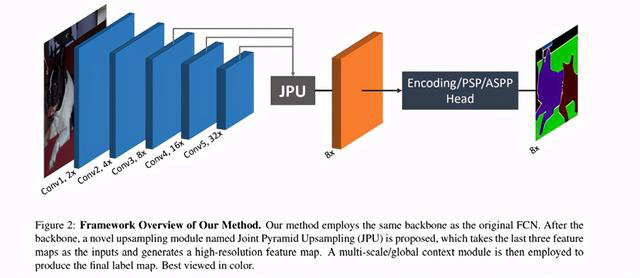
2)FastFCN — 快速全连接网络
在这种结构中,一个使用联合金字塔上采样(JPU)模块来代替了扩展卷积网络,因为卷积网络消耗大量的内存和计算时间。它使用一个完全连接的网络作为核心,同时应用JPU进行上采样。JJPU将低分辨率的feature map上采样为高分辨率的feature map。
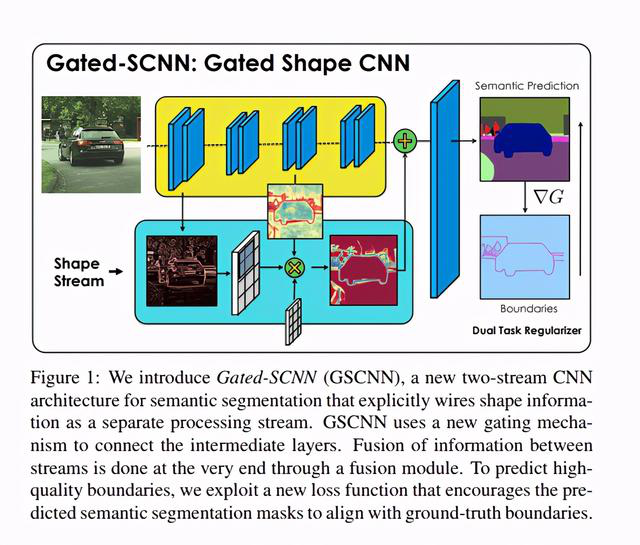
3)Gated-SCNN
这个架构由一个双流CNN架构组成。在该模型中,使用一个单独的分支来处理图像的形状信息。形状流用于处理边界信息。
4)DeepLab(深度实验室)
在这种体系结构中,带有上采样滤波器的卷积用于涉及密集预测的任务。多个对象的分割是通过无空间金字塔空间池完成的。最后,利用DCNNs改进了目标边界的定位。通过插入零或输入特征图进行稀疏采样来对滤波器进行上采样,从而实现无用卷积。
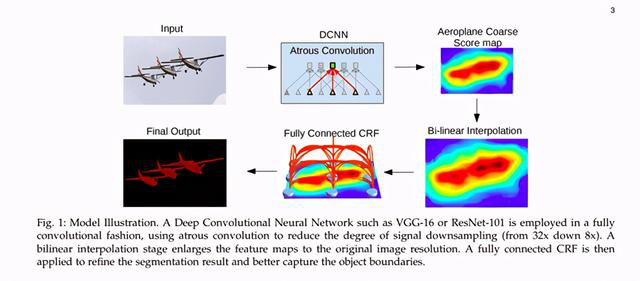
5)Mask R-CNN
在这个体系结构中,使用一个边界框/包围盒和语义分割对对象进行分类和定位,该语义分割将每个像素分类为一组类别。每个感兴趣的区域都有一个分割蒙版。并且将产生一个类标签和一个边界框作为最终输出。实际上该体系结构是Faster R-CNN的扩展。Faster R-CNN由提出区域的深度卷积网络和利用区域的检测器组成。
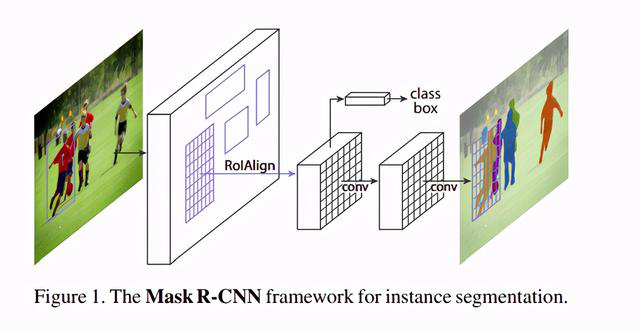
这是在COCO测试集上获得的结果的图像。

6、图像分割的数据集
介绍完训练方法后,从哪里可以获得相应的数据集来进行图像分割的学习呢?现在来看下有哪些数据集可直接使用:
1)Common Objects in COntext — Coco数据集
COCO是一个大规模的物体检测、图像分割和五项描述生成的大规模数据集。这个数据集中一共包含91个物品类别。包含着250000带有关键点标注的人。它的下载大小是37.57GIB。它包含80个对象类别。它在Apache2.0许可下可用,可以从这里下载(https://cocodataset.org/#download)。
2)PASCAL可视化对象类(PASCAL VOC)
PASCAL有9963张图片,有20个不同的类别。训练/验证集是一个2GB的tar文件。数据集可以从官方网站下载:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
3)Cityscapes 数据集
此数据集包含城市场景的图像。它可以用来评价视觉算法在城市场景中的性能。数据集可以从这里下载:https://www.cityscapes-dataset.com/。
4)Cambridge驾驶标注视频数据库 — CamVid
这是一个基于运动的分割和识别数据集。它包含32个语义类别。此链接包含进一步的解释和指向数据集的下载链接:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/。
7、图像分割工具及框架
在已经准备好了可使用的数据集后,下面介绍一些可以用来入门的工具/框架。
FastAI库——给定一个图像,这个库可以创建图像中对象的掩码/遮罩。
Sefexa图像分割工具-——Sefexa是一个免费的工具,可用于半自动图像分割、图像分析和地面真实性的创建。
Deepmask——Facebook Research的Deepmask是Deepmask和SharpMask的Torch实现。
MultiPath——这是“用于对象检测的MultiPath网络 ”中对象检测网络的Torch实现。
OpenCV——这是一个开源的计算机视觉库,有超过2500个优化算法。
MIScnn——是一个医学图像分割开源库。它允许在几行代码中使用最先进的卷积神经网络和深度学习模型来建立管道。
Fritz——Fritz提供了几种计算机视觉工具,包括用于移动设备的图像分割工具。
8、图像分割的应用
图像分割有助于确定目标之间的关系,以及目标在图像中的上下文。应用包括人脸识别、车牌识别和卫星图像分析。例如,零售和时尚等行业在基于图像的搜索中使用了图像分割。自动驾驶汽车用它来了解周围的环境。
1)目标检测和人脸检测
人脸检测:一种用于许多应用的目标检测,包括数字相机的生物识别和自动对焦功能。算法检测和验证面部特征的存在。例如,眼睛在灰度图像中显示为谷地。
医学影像:从医学影像中提取临床相关信息。例如,放射学家可以使用机器学习来增强分析,通过将图像分割成不同的器官、组织类型或疾病症状。这可以减少运行诊断测试所需的时间。
机器视觉:捕捉和处理图像,为设备提供操作指导的应用。这包括工业和非工业的应用。机器视觉系统使用专用摄像机中的数字传感器,使计算机硬件和软件能够测量、处理和分析图像。例如,检测系统为汽水瓶拍照,然后根据合格 – 不合格标准分析图像,以确定瓶子是否被正确地填充。
2)视频监控 — 视频跟踪和运动目标跟踪
这涉及到在视频中定位移动物体。其用途包括安全和监视、交通控制、人机交互和视频编辑。
自动驾驶:自动驾驶汽车必须能够感知和理解他们的环境,以便安全驾驶。相关类别的对象包括其他车辆、建筑物和行人。语义分割使自动驾驶汽车能够识别图像中的哪些区域可以安全驾驶。
虹膜识别:一种能识别复杂虹膜图案的生物特征识别技术。它使用自动模式识别来分析人眼的视频图像。
3)零售图像识别
这个应用让零售商了解货架上商品的布局。算法实时处理产品数据,检测货架上是否有商品。如果有产品缺货,他们可以找出原因,通知跟单员,并为供应链的相应部分推荐解决方案。
9、未来发展方向
目前的发展方向是语义分割,包括从图像到视频中的分割,对分割的精确度有很大的要求,以目前的模型表现来看,在准确率上无疑还有提升空间。另外,弱监督甚至无监督训练来解决昂贵的数据标注问题也是一种方向。最后,示例级别(Instance level)的图像分割也是一个热门研究方向。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
