
本文分享完整的直播需要的流程,理清主播到观众之间的交互过程,包括直播推流端和拉流端的具体步骤。
试想一下,主播在这边捧着手机,表演一番,然后粉丝们在另外一边拿着手机看得津津有味,其实中间经历了很多步骤,非常复杂的过程。下面简单阐释了主播到观众之间的交互过程。
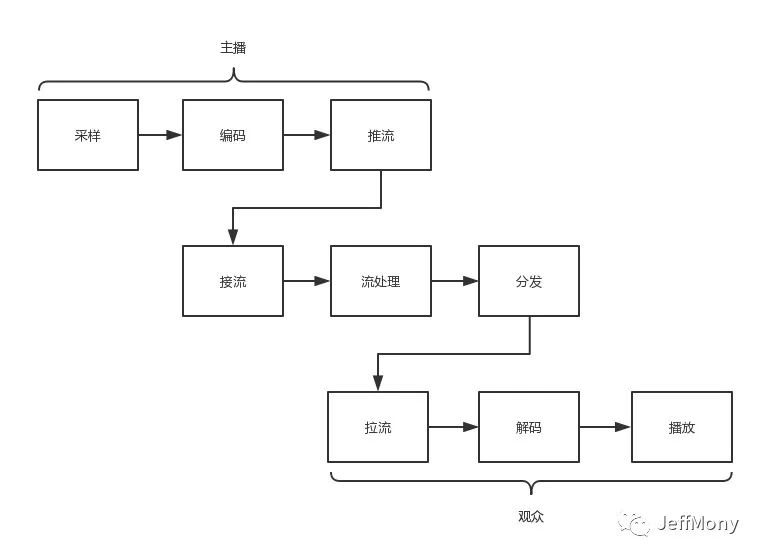
推流端
在主播这边,详细拆分具体的步骤,如下;
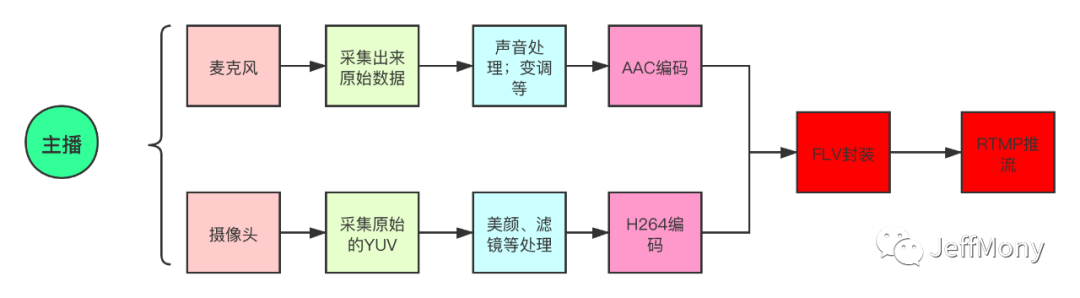
- 我们知道原始数据,音频从麦克风中获取,视频从camera中获取,原始数据很大,大得吓人,有多吓人,给大家举个例子:每一张图片,我们称为一帧。只要每秒钟帧的数据足够多,也即播放得足够快。比如每秒 30 帧,以人的眼睛的敏感程度,是看不出这是一张张独立的图片的,这就是我们常说的帧率(FPS)。每一张图片,都是由像素组成的,假设为 1024*768(这个像素数不算多)。每个像素由 RGB 组成,每个 8 位,共 24 位。我们来算一下,每秒钟的视频有多大?30 帧 × 1024 × 768 × 24 = 566,231,040Bits = 70,778,880Bytes, 如果一分钟呢?4,246,732,800Bytes,已经是 4 个 G 了。这简直是噩梦,我们能直接上传原始数据吗,当然不能。
- 对于音频而言,我们针对采集的原始数据,会降噪,去杂音,还会变调,变声,根据直播的玩法不同,选择不同的功能,这个soundtouch都是可以实现的。
- 对于视频而言,我们会加上美颜,滤镜,瘦脸,大眼,贴纸等操作,单纯滤镜的话,使用opengl es是可以实现的,如果加上美颜、瘦脸、大眼等操作,需要人脸识别算法,推荐opencv库,当然现在市面上很火的是arcsoft公司的人脸识别算法。
- 对音频和视频的原视频数据处理完了之后,还需要编码处理,编码就是压缩,说法不同罢了,压缩讲究很多技巧,不过一般不需要我们实现,我们使用h264编码视频,aac编码音频。
- 压缩完视频和音频之后,需要对音频和视频封包处理,因为是直播场景,我们需要封包成流式数据,FLV就是流式封装格式。
- 封包完成,使用RTMP向服务器推流,服务器接收流数据,准备分发。
这儿涉及到很多细节的知识点,我们单独拎出来讲解的;
- H264怎么压缩的?
- FLV封装格式怎样的?
- AAC怎么压缩的?
- RTMP协议是怎么协商的?
- OpenGL ES的实现原理?
知识点实在太多了,我建议分几篇文章讲解,本文只介绍直播经历的主要过程,以及各个阶段主要在做什么?
拉流端
拉流端就是观众所在的那一端,观众解析服务器给过来的地址,然后渲染播放,主要经历的步骤如下:

拉流操作基本上可以看成推流操作的反操作,有些地方略有不同。
- 首先对服务器url发起请求,一段一段的请求,这是RTMP的特色。
- 请求回来的数据,是采用FLV封装好的信息,需要解封装,就是解析FLV文件,将文件的轨道信息取出来,分别是音轨和视轨。
- 针对音轨和视轨,我们分别起子线程去解析处理它们,首先对它们解码,获取原始文件,视频就是YUV,音频就是PCM;
- 音频使用opensl es播放,opensl是一个嵌入式的sound library;视频使用opengl es渲染,对应的是GLSurfaceView来消费图像;
- 当然最重要的是音视频同步,这个千万别忘了,音视频同步有3种方式:以音频pts为准;以视频pts为准;另外起一个参考的pts时钟,音频和视频都以这个为准;通常我们以音频pts为准。
这里我们也留了一些知识点:
- 音视频同步具体怎么实现?
- 软硬解码如何切换?
以这篇文章为起点,我们围绕着直播系统展开分析音视频相关的知识点,从具体项目中出发,发现音视频领域中更有趣的东西。
解决一个大而难得问题,最核心的做法就是分解任务,把任务分解成较为合理的一个个子任务,然后一个个攻克它们,之后再汇总这些任务,整合不在一起,变成一整个项目,这是解决问题的思路。
作者:音视频平凡之路,文章略有改编。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
