
要明白一个知识点,首先要快速的对这个知识点建立一个概念模型,有了概念模型之后,再在这个模型上不断的去填充一些细节的东西,会有助于我们把握知识的本质。
带宽是什么?
带宽是网络被发送的能力,它会受到网卡复制网络包到内核缓冲区或者搬运内核缓冲区的网络包到网卡缓冲区能力的影响,也会受到接收窗口或拥塞窗口的影响,也就是说如果对端接收能力变小,那么带宽是不能提升上去的。
当整个网络的链路变长以后,网络的情况是很复杂的。网络包有可能会经过多个路由器或者不同运营商之间的线路去进行数据交换,而不同代理商之间的网络流量是极其庞大的,它会导致你的网络包产生丢包或者重发的状况,针对于这种情况,平时在部署服务节点时候,如果有能力在设计链路的时候最好能够避免这种不同代理商之间的网络交换,优化整个网络传输的链路选择能力,这也是cdn提供全局加速的一个原理。
cdn原理是能够在世界各地部署很多个节点,然后每个节点之间的一个链路选择是通过服务运营商精心编排过的,它能够保证你的整个网络的链路是经过优化的,能够让你的网络包更少的产生丢包或者是重发的状况。
网络包的收发过程
我们得明白一个网络包是如何经过应用程序的,
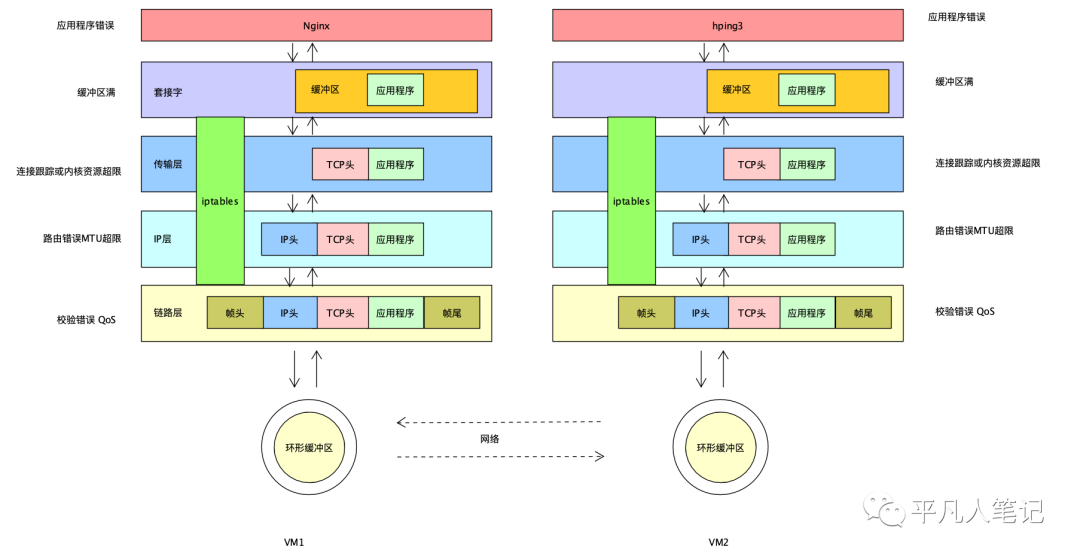
一般应用程序发起一个网络请求,这个网络请求的数据会写到内核的套接字缓冲区当中,然后内核会对这个套接字缓冲区的数据去加上tcp头或udp头,然后又经由ip层,再加上一个ip头,中间会经过防火墙的一系列规则对这个网络包进行过滤,看是丢弃还是继续往网卡上面去发送,最终到达链路层之后,这个网络包会经由链路层去发到网卡上的环形缓冲区上,最后由网卡发送到整个网络当中,其中每一环都是有可能会发生丢包的。
理解了网络包的收发过程,建立起了这样一种概念模型之后,会有助于我们对丢包问题的排查。
如何去衡量网络情况的好坏
对应用服务进行监控的时候,如何去衡量网络情况的好坏,一般也用来衡量硬件资源的好坏。
一个通用套路,一般我们会先看一下,在系统层面上网络指标的一个表现,再看下具体是哪个进程造成这种表现的异常,再去定位到问题代码。
具体对网络而言,如何从系统的层面或者是我们要使用哪些工具去看这个网络的好坏?
从系统层面看网络有几个重要的指标,MBS 代表网卡每秒发送多少或者是接收多少个M字节,Mbps是每秒多少M比特位。通常说的带宽的单位就是Mbps,一般100M带宽的话换算成MBS等于Mbps除以8。
平时选择服务器节点的时候,除了带宽,还有pps就是每秒发送、接收包的数量,它也是有限制的。
当我们在遇到网络性能问题的时候,首先可以去观察你的机器节点上这两个指标是否是已经达到了一个瓶颈的状态。如果带宽只有100Mbps,然后通过工具查看机器上面的节点带宽,马上就要超过这个值的时候,很有可能这个时候带宽已经成为瓶颈,可能要对机器的配额去进行升级。
sar
# 使用sar每一秒统计一次网络接口的活动状况,连续显示5次
sar -n DEV 1 5
- IFACE是网卡接口名称
- rxpck/s、txpck/s 每秒收或发的数据包数量
- rxkB/s、txkB/s 每秒收或发的字节数,以kB/s为单位
- rxcmp/s、txcmp/s 每秒收或发的压缩过的数据包数量
- rxmcst/s 每秒收到的多播(多播是一点对多点的通信)数据包
看完了整个系统层面的网络情况,可以再精细点的从进程的角度去看这个问题。
iftop
# https://www.tecmint.com/iftop-linux-network-bandwidth-monitoring-tool/
yum -y install libpcap libpcap-devel ncurses ncurses-devel
yum install epel-release
yum install -y iftop
iftop -P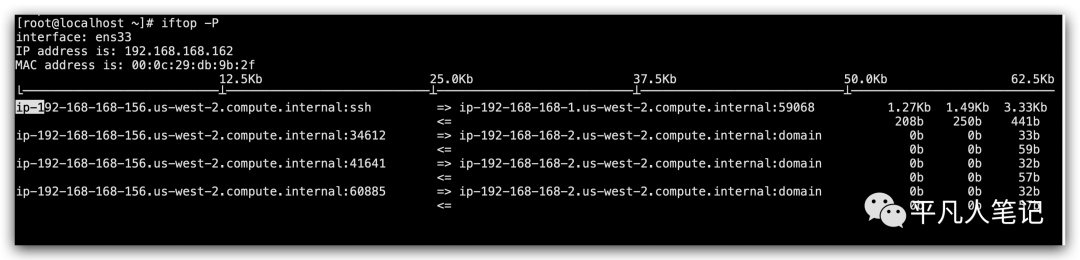

能够列出这个系统里面每一条链接的一个Mbps,能够找出哪个ip消耗流量最多。更多的时候其实不是系统网络达到瓶颈,而是进程处理网络包的能力跟不上。
nethogs
yum install nethogs
# 查看进程占用带宽的情况
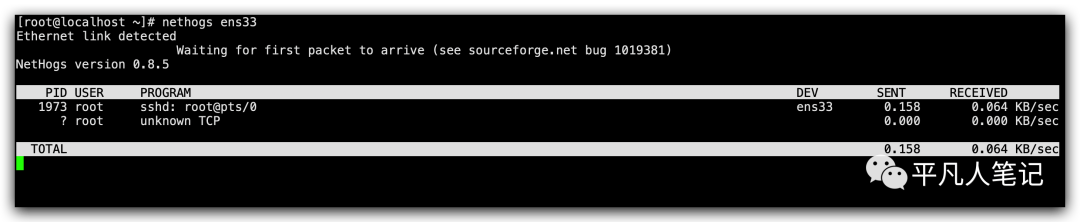
nethogs ens33列出每个进程的收发流量的数据,找出哪个进程是最消耗流量的,能够更方便的让我们去定位哪个进程出的问题。
go trace这个工具能够去分析出网络调度带来的延迟问题,其实也能够从侧面去反馈出你的程序在某一块代码上面可能是在进行频繁的网络调度,有可能是进行频繁调度之后,比较消耗带宽,从而可能间接的反映出延迟会略有提高,go trace也能够从让我们在网络性能问题当中能够比较间接去找出一块问题的代码。
网络性能当中比较重要的一个点就是如何查找你的一个丢包问题,对于上面的图[网络包传输过程],从上到下依次分析,先看应用层,通过listen这个方法去监听套接字的时候,在三次握手的时候,会有两个队列,首先服务器接收到客户端的syn包的时候,会创建一个半连接队列 ,这个半连接队列会将那些还没有完成三次握手但是却发送了一个syn包的这种连接放到里面,会回复客户端一个syn+ack,客户端收到了这个ack和syn包之后,会回复给服务端一个ack,这个时候内核就会将这个连接放到全连接队列,当服务器调用accept方法的时候,会将这条连接从全连接队列里取出来,所以这个时候涉及了两个队列,如果这两个队列满了的话,就会可能会产生丢包的行为。
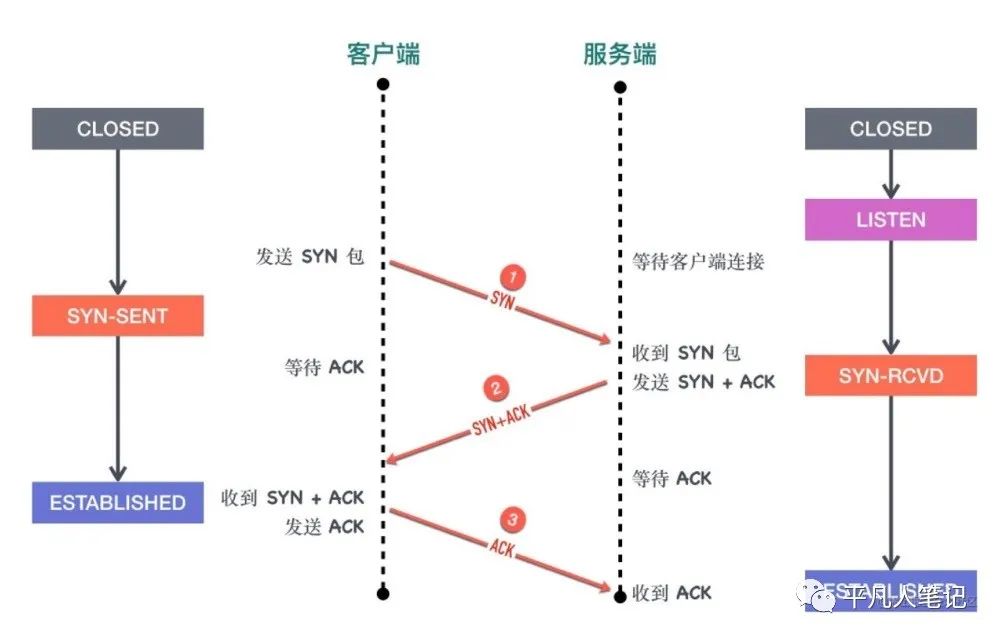
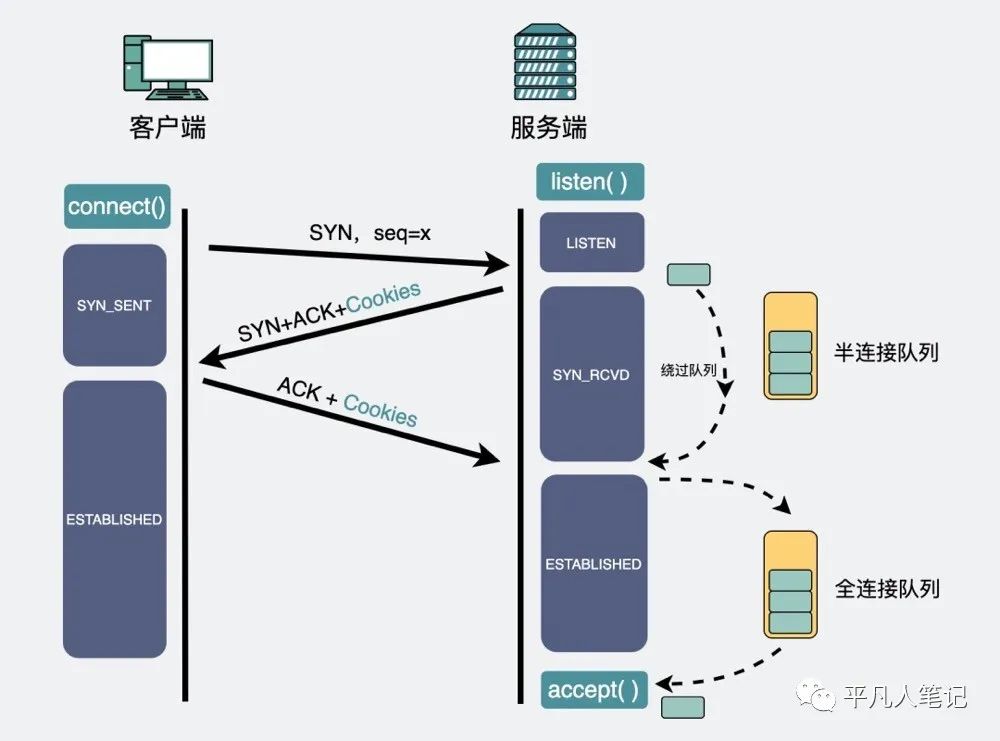
首先来看一下半连接队列,它是由内核参数决定的,这个也是可以调整的。通过三次握手,才能够去建立连接,但是由于这种队列的机制很有可能在并发量大的时候,会产生队列满了,然后丢包的行为,所以内核提供了一个tcp_syncookies参数,它能够去启用tcp_syncookies这个机制,当半连接队列溢出的时候,它能够让内核不直接去丢弃这个新包,而是回复带有syncookie的包,这个时候客户端再去向服务器进行请求的时候,它会去验证这个syncookie,这样能够防止半连接队列溢出的时候造成服务不可用的一个情况。
如何去确定是由于半连接队列溢出导致的丢包?
通过dmesg去日志里面去搜寻tcp drop,是能够发现丢包的情况,dmesg是一个内核的日志记录,我们能够从里面去找出一些内核的行为,
dmesg|grep "TCP: drop open erquest form"然后看下全连接队列该怎么看,通过ss命令的话,能够去看到你的服务在listen的时候,全连接队列的大小
ss -lnt
# -l 显示正在监听
# -n 不解析服务名称
# -t 只显示 tcp socket
对于你的那个监听服务而言,它的一个Send-Q,就是代表当前全连接队列长度,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接。Recv-Q是指当前全连接队列的大小,上面的输出结果说明监听 9000 端口的 TCP 服务,最大全连接长度为 128。Recv-Q一般都是为0,如果存在一种大于0的情况并且会持续一个较长时间的话,就说明你的服务处理连接的能力比较慢了,会导致全连接队列过满或者丢弃,这个时候应该会加快你的服务处理连接的能力。
ss命令对于状态为ESTAB的连接,它看的不是你这个监听服务,而是去看一条已经建立好的连接相关指标,Recv-Q是代表收到但未被应用程序读取的一个字节数,Send-Q已发送但未收到确认的字节数,通过这两个指标,能够去看到是应用程序对一个数据的处理能力慢,还是说是客户端对接收的数据处理的比较慢的情况,一般这两个值也都是为0,如果有其中一个不为0 ,你可能要去排查一下是客户端的问题还是服务器的问题。
当全连接队列满了之后,内核默认会将包丢弃,但是也已可指定内核的一个其他行为,如果是将tcp_abort_on_overflow这个值设为1的话,那会直接发一个reset的包给客户端,直接将这个连接断开掉,表示废掉这个握手过程和这个连接。
经过应用层之后,网络包会到达到传输层,传输层会有防火墙的存在,如果防火墙开启的话,那和防火墙有关的连接跟踪表:nf_conntrack这个是linux为每个经过内核网络栈的数据包,会生成一个连接的记录项,当服务器处理过多时,这个连接记录项所在的连接跟踪表就会被打满,然后服务器就会丢弃新建连接的数据包,所以有时候丢包有可能是防火墙的连接跟踪表设计的太小了。
那如何去看连接跟踪表的大小呢
# 查看nf_conntrack表最大连接数
cat /proc/sys/net/netfilter/nf_conntrack_max
# 查看nf_conntrack表当前连接数
cat /proc/sys/net/netfilter/nf_conntrack_count
通过这个文件看连接跟踪表的一个最大连接数nf_conntrack_max,所以在丢包的时候,可以对这一部分去进行排查,看下连接跟踪表是不是被打满了。
网络包经过传输层之后,再来看网络层和物理层,提到网络层和物理层,就要看网卡了,通过netstat命令,能够去看整个机器上面网卡的丢包和收包的情况。
RX-DRP这个指标数据,如果它大于0,说明这个网卡是有丢包情况,这里记录的是从开机到目前为止的数据情况,所以在分析的时候,隔一定的时间去看这个指标是否有上涨。
RX-OVR指标说明这个网卡的环形缓冲区满了之后产生的丢弃行为。
通过netstat能够分析网卡丢包的情况,
# netstat可以统计网路丢包以及环形缓冲区溢出
netstat -i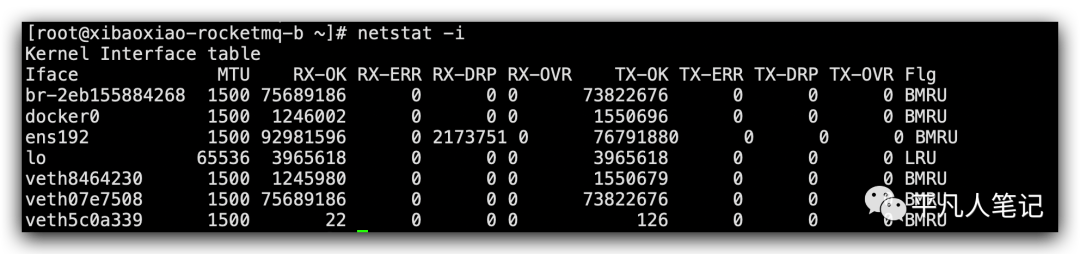
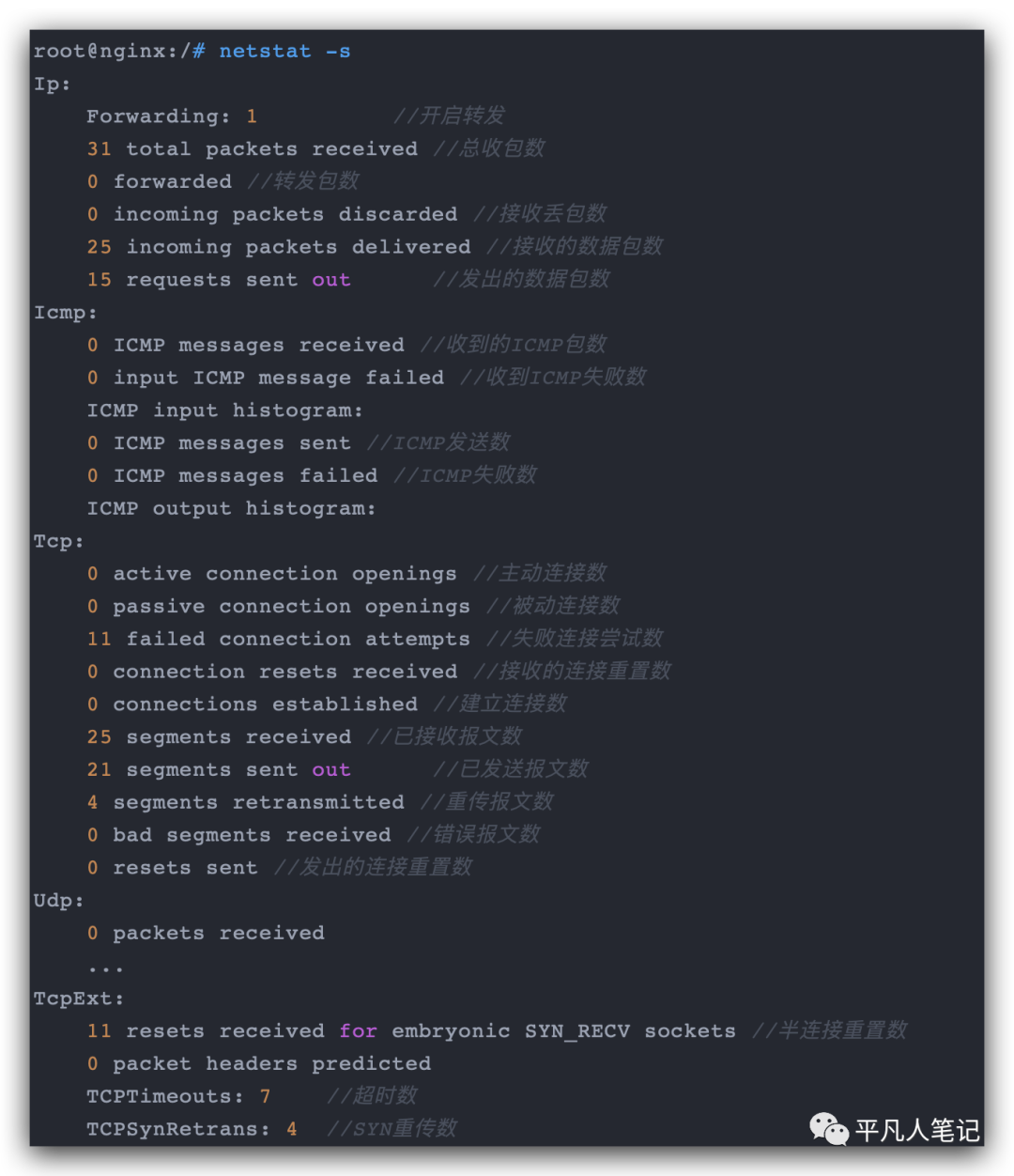
netstat还能够统计网络协议层的丢包情况,
MTU
应用层的网络包通过网络层的时候会根据数据包的大小去进行分包发送。
当tcp数据包的大小发送网络层之后,网络层发现这个包会大于它的mtu值,这个数据包会进行一个分包的操作。在进行网卡设置的时候,会设置为你的传输层包,如果大于了mtu这个值,那就可以直接将这个网络包丢弃,这也是在现实生活中经常会碰到的一个丢包问题。
所以你在检查链路的时候,通常链路长了可能不太好排查,链路短一点,可能会很容易看到整条链路当中mtu的情况,看一下是不是每条链路上对应的每个网卡的mtu指标是不一样的,如果不一样的话,有可能会造成你的丢包问题,因为一个包的转发跟网络上面设置的mtu值大小有关系,比如设置为大于mtu之后会把这个包给丢弃掉。如果发送的mtu包的大小超过网卡规定的大小,并且网卡不允许分片,那么则会产生丢包。
文章来源于平凡人笔记 ,作者孟凡霄
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
